 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEstimating Item Difficulty with Large Language Models as Experts
May 18, 2026Accurate estimates of item difficulty are essential for valid assessment and effective adaptive learning. However, for newly created tasks, response data are typically unavailable. Pretesting and expert judgement can be costly and slow, while machine learning methods often require large labelled training datasets. Recent work suggests that large language models (LLMs) may help. However, there is limited evidence on the elicitation procedures and prompt configurations used to emulate experts for difficulty estimation. This study addresses this gap by evaluating three off-the-shelf LLMs as difficulty raters for newly created items without access to response data. Using an item bank from an online learning system, the study examined 6 domains of primary-school mathematics, with empirical difficulty estimates treated as empirical reference. The study used a full factorial design crossing three factors: judgement format (absolute vs pairwise), decision type (hard decisions vs token-probability-based estimates), and prompting strategy (zero-shot vs few-shot). LLM-derived difficulty estimates were compared with empirical difficulties using Spearman rank correlations. Across domains, LLM-based estimates exhibited moderate to strong positive correlations with empirical item difficulties. For simpler arithmetic tasks, some configurations approached the upper end of the accuracy range reported for human experts in previous research. Pairwise comparison consistently outperformed absolute judgement in the absence of additional refinements. However, when token-level probabilities were incorporated and examples of items with known empirical difficulty were provided, the absolute judgement configuration likewise demonstrated moderate-to-high alignment. The study positions LLMs as a promising tool for initial item calibration and offers insights into effective workflow configuration.
Falcon2-11B Technical Report
Jul 20, 2024



We introduce Falcon2-11B, a foundation model trained on over five trillion tokens, and its multimodal counterpart, Falcon2-11B-vlm, which is a vision-to-text model. We report our findings during the training of the Falcon2-11B which follows a multi-stage approach where the early stages are distinguished by their context length and a final stage where we use a curated, high-quality dataset. Additionally, we report the effect of doubling the batch size mid-training and how training loss spikes are affected by the learning rate. The downstream performance of the foundation model is evaluated on established benchmarks, including multilingual and code datasets. The foundation model shows strong generalization across all the tasks which makes it suitable for downstream finetuning use cases. For the vision language model, we report the performance on several benchmarks and show that our model achieves a higher average score compared to open-source models of similar size. The model weights and code of both Falcon2-11B and Falcon2-11B-vlm are made available under a permissive license.
LM-Polygraph: Uncertainty Estimation for Language Models
Nov 13, 2023
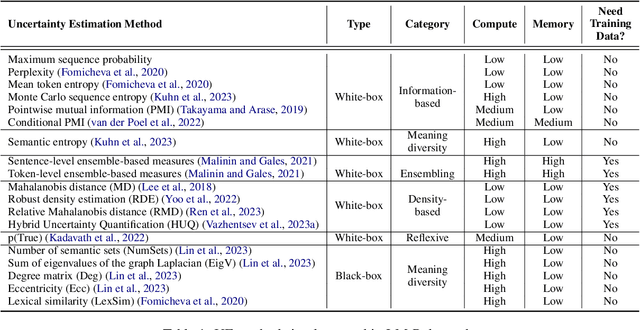
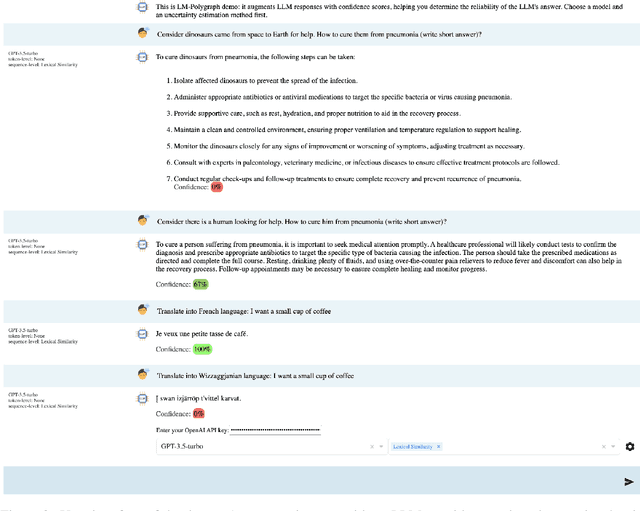
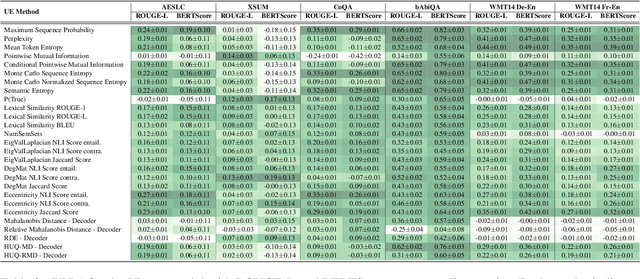
Recent advancements in the capabilities of large language models (LLMs) have paved the way for a myriad of groundbreaking applications in various fields. However, a significant challenge arises as these models often "hallucinate", i.e., fabricate facts without providing users an apparent means to discern the veracity of their statements. Uncertainty estimation (UE) methods are one path to safer, more responsible, and more effective use of LLMs. However, to date, research on UE methods for LLMs has been focused primarily on theoretical rather than engineering contributions. In this work, we tackle this issue by introducing LM-Polygraph, a framework with implementations of a battery of state-of-the-art UE methods for LLMs in text generation tasks, with unified program interfaces in Python. Additionally, it introduces an extendable benchmark for consistent evaluation of UE techniques by researchers, and a demo web application that enriches the standard chat dialog with confidence scores, empowering end-users to discern unreliable responses. LM-Polygraph is compatible with the most recent LLMs, including BLOOMz, LLaMA-2, ChatGPT, and GPT-4, and is designed to support future releases of similarly-styled LMs.
One-Step Distributional Reinforcement Learning
Apr 27, 2023



Reinforcement learning (RL) allows an agent interacting sequentially with an environment to maximize its long-term expected return. In the distributional RL (DistrRL) paradigm, the agent goes beyond the limit of the expected value, to capture the underlying probability distribution of the return across all time steps. The set of DistrRL algorithms has led to improved empirical performance. Nevertheless, the theory of DistrRL is still not fully understood, especially in the control case. In this paper, we present the simpler one-step distributional reinforcement learning (OS-DistrRL) framework encompassing only the randomness induced by the one-step dynamics of the environment. Contrary to DistrRL, we show that our approach comes with a unified theory for both policy evaluation and control. Indeed, we propose two OS-DistrRL algorithms for which we provide an almost sure convergence analysis. The proposed approach compares favorably with categorical DistrRL on various environments.
ScaleFace: Uncertainty-aware Deep Metric Learning
Sep 12, 2022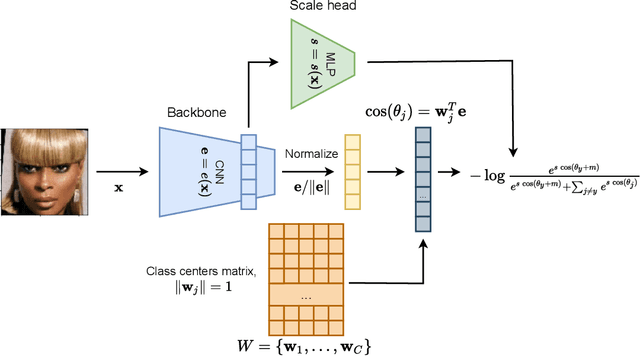
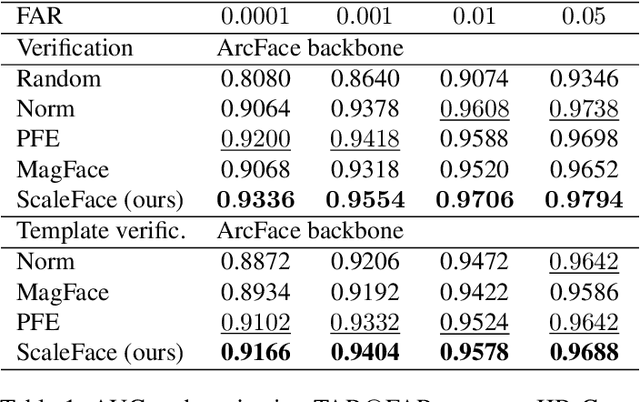

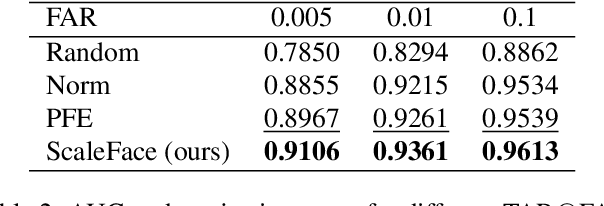
The performance of modern deep learning-based systems dramatically depends on the quality of input objects. For example, face recognition quality would be lower for blurry or corrupted inputs. However, it is hard to predict the influence of input quality on the resulting accuracy in more complex scenarios. We propose an approach for deep metric learning that allows direct estimation of the uncertainty with almost no additional computational cost. The developed \textit{ScaleFace} algorithm uses trainable scale values that modify similarities in the space of embeddings. These input-dependent scale values represent a measure of confidence in the recognition result, thus allowing uncertainty estimation. We provide comprehensive experiments on face recognition tasks that show the superior performance of ScaleFace compared to other uncertainty-aware face recognition approaches. We also extend the results to the task of text-to-image retrieval showing that the proposed approach beats the competitors with significant margin.
NUQ: Nonparametric Uncertainty Quantification for Deterministic Neural Networks
Feb 07, 2022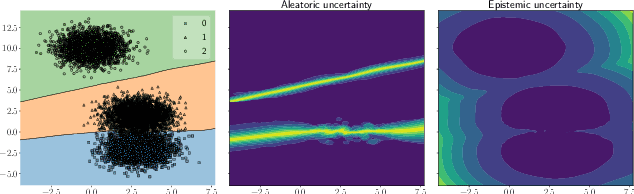

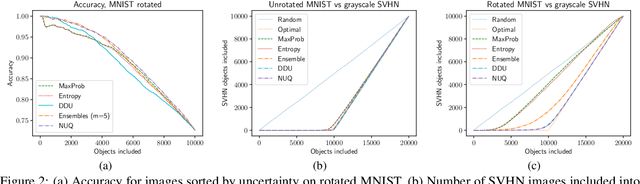

This paper proposes a fast and scalable method for uncertainty quantification of machine learning models' predictions. First, we show the principled way to measure the uncertainty of predictions for a classifier based on Nadaraya-Watson's nonparametric estimate of the conditional label distribution. Importantly, the approach allows to disentangle explicitly aleatoric and epistemic uncertainties. The resulting method works directly in the feature space. However, one can apply it to any neural network by considering an embedding of the data induced by the network. We demonstrate the strong performance of the method in uncertainty estimation tasks on a variety of real-world image datasets, such as MNIST, SVHN, CIFAR-100 and several versions of ImageNet.
EWS-GCN: Edge Weight-Shared Graph Convolutional Network for Transactional Banking Data
Sep 30, 2020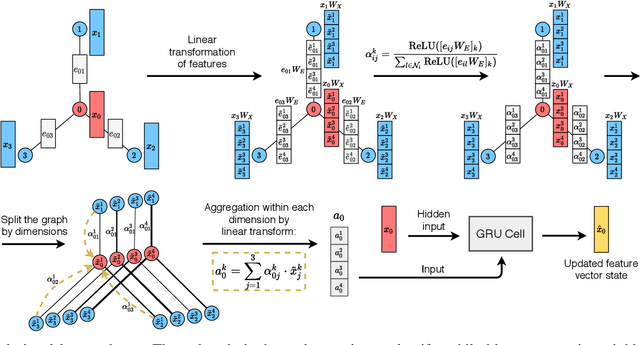

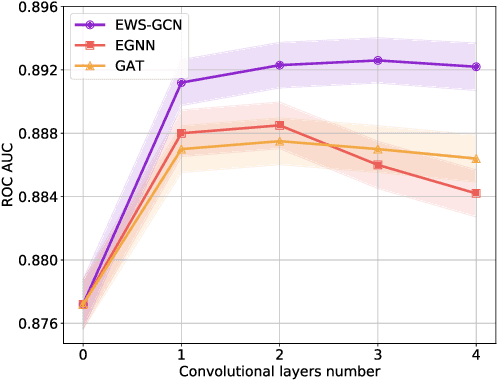

In this paper, we discuss how modern deep learning approaches can be applied to the credit scoring of bank clients. We show that information about connections between clients based on money transfers between them allows us to significantly improve the quality of credit scoring compared to the approaches using information about the target client solely. As a final solution, we develop a new graph neural network model EWS-GCN that combines ideas of graph convolutional and recurrent neural networks via attention mechanism. The resulting model allows for robust training and efficient processing of large-scale data. We also demonstrate that our model outperforms the state-of-the-art graph neural networks achieving excellent results
Dropout Strikes Back: Improved Uncertainty Estimation via Diversity Sampled Implicit Ensembles
Mar 06, 2020
Modern machine learning models usually do not extrapolate well, i.e., they often have high prediction errors in the regions of sample space lying far from the training data. In high dimensional spaces detecting out-of-distribution points becomes a non-trivial problem. Thus, uncertainty estimation for model predictions becomes crucial for the successful application of machine learning models in many applications. In this work, we show that increasing the diversity of realizations sampled from a neural network with dropout helps to improve the quality of uncertainty estimation. In a series of experiments on simulated and real-world data, we demonstrate that diversification via determinantal point processes-based sampling allows achieving state-of-the-art results in uncertainty estimation for regression and classification tasks. Importantly, our approach does not require any modification to the models or training procedures, allowing for straightforward application to any deep learning model with dropout layers.
Linking Bank Clients using Graph Neural Networks Powered by Rich Transactional Data
Jan 23, 2020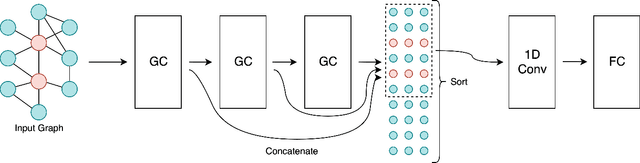
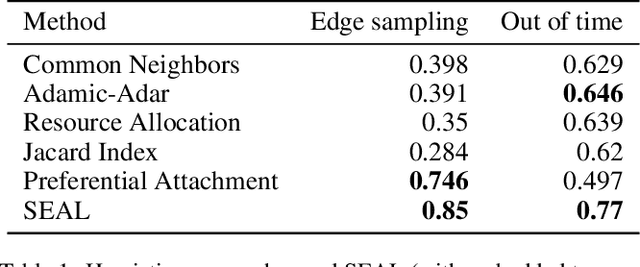

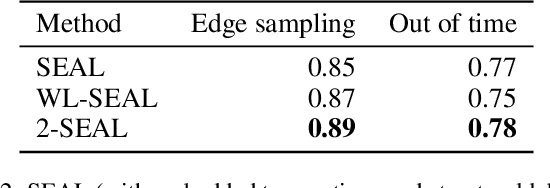
Financial institutions obtain enormous amounts of data about user transactions and money transfers, which can be considered as a large graph dynamically changing in time. In this work, we focus on the task of predicting new interactions in the network of bank clients and treat it as a link prediction problem. We propose a new graph neural network model, which uses not only the topological structure of the network but rich time-series data available for the graph nodes and edges. We evaluate the developed method using the data provided by a large European bank for several years. The proposed model outperforms the existing approaches, including other neural network models, with a significant gap in ROC AUC score on link prediction problem and also allows to improve the quality of credit scoring.