 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Hallucinations in SpeechLLMs at Inference Time Using Attention Maps
Apr 21, 2026Hallucinations in Speech Large Language Models (SpeechLLMs) pose significant risks, yet existing detection methods typically rely on gold-standard outputs that are costly or impractical to obtain. Moreover, hallucination detection methods developed for text-based LLMs do not directly capture audio-specific signals. We investigate four attention-derived metrics: AUDIORATIO, AUDIOCONSISTENCY, AUDIOENTROPY, and TEXTENTROPY, designed to capture pathological attention patterns associated with hallucination, and train lightweight logistic regression classifiers on these features for efficient inference-time detection. Across automatic speech recognition and speech-to-text translation tasks, evaluations on Qwen-2-Audio and Voxtral-3B show that our approach outperforms uncertainty-based and prior attention-based baselines on in-domain data, achieving improvements of up to +0.23 PR-AUC, and generalises to out-of-domain ASR settings. We further find that strong performance can be achieved with approximately 100 attention heads, improving out-of-domain generalisation compared to using all heads. While effectiveness is model-dependent and task-specific training is required, our results demonstrate that attention patterns provide a valuable tool for hallucination detection in SpeechLLMs.
Fact-Checking the Output of Large Language Models via Token-Level Uncertainty Quantification
Mar 07, 2024
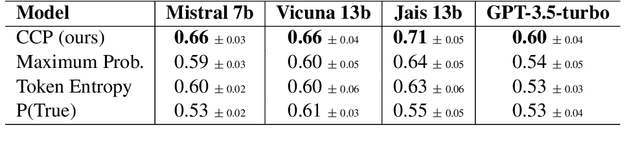
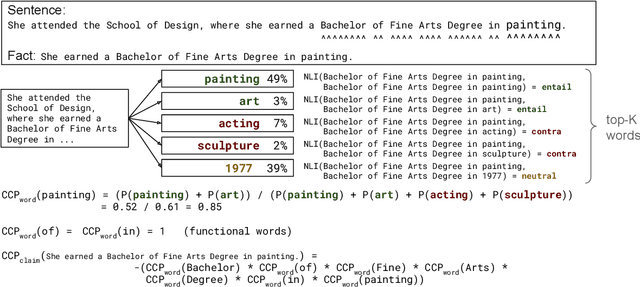
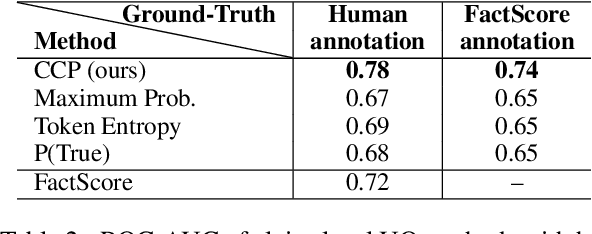
Large language models (LLMs) are notorious for hallucinating, i.e., producing erroneous claims in their output. Such hallucinations can be dangerous, as occasional factual inaccuracies in the generated text might be obscured by the rest of the output being generally factual, making it extremely hard for the users to spot them. Current services that leverage LLMs usually do not provide any means for detecting unreliable generations. Here, we aim to bridge this gap. In particular, we propose a novel fact-checking and hallucination detection pipeline based on token-level uncertainty quantification. Uncertainty scores leverage information encapsulated in the output of a neural network or its layers to detect unreliable predictions, and we show that they can be used to fact-check the atomic claims in the LLM output. Moreover, we present a novel token-level uncertainty quantification method that removes the impact of uncertainty about what claim to generate on the current step and what surface form to use. Our method Claim Conditioned Probability (CCP) measures only the uncertainty of particular claim value expressed by the model. Experiments on the task of biography generation demonstrate strong improvements for CCP compared to the baselines for six different LLMs and three languages. Human evaluation reveals that the fact-checking pipeline based on uncertainty quantification is competitive with a fact-checking tool that leverages external knowledge.
ClimateGPT: Towards AI Synthesizing Interdisciplinary Research on Climate Change
Jan 17, 2024This paper introduces ClimateGPT, a model family of domain-specific large language models that synthesize interdisciplinary research on climate change. We trained two 7B models from scratch on a science-oriented dataset of 300B tokens. For the first model, the 4.2B domain-specific tokens were included during pre-training and the second was adapted to the climate domain after pre-training. Additionally, ClimateGPT-7B, 13B and 70B are continuously pre-trained from Llama~2 on a domain-specific dataset of 4.2B tokens. Each model is instruction fine-tuned on a high-quality and human-generated domain-specific dataset that has been created in close cooperation with climate scientists. To reduce the number of hallucinations, we optimize the model for retrieval augmentation and propose a hierarchical retrieval strategy. To increase the accessibility of our model to non-English speakers, we propose to make use of cascaded machine translation and show that this approach can perform comparably to natively multilingual models while being easier to scale to a large number of languages. Further, to address the intrinsic interdisciplinary aspect of climate change we consider different research perspectives. Therefore, the model can produce in-depth answers focusing on different perspectives in addition to an overall answer. We propose a suite of automatic climate-specific benchmarks to evaluate LLMs. On these benchmarks, ClimateGPT-7B performs on par with the ten times larger Llama-2-70B Chat model while not degrading results on general domain benchmarks. Our human evaluation confirms the trends we saw in our benchmarks. All models were trained and evaluated using renewable energy and are released publicly.
Dropout Strikes Back: Improved Uncertainty Estimation via Diversity Sampled Implicit Ensembles
Mar 06, 2020
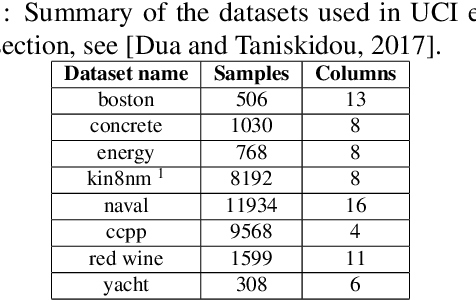
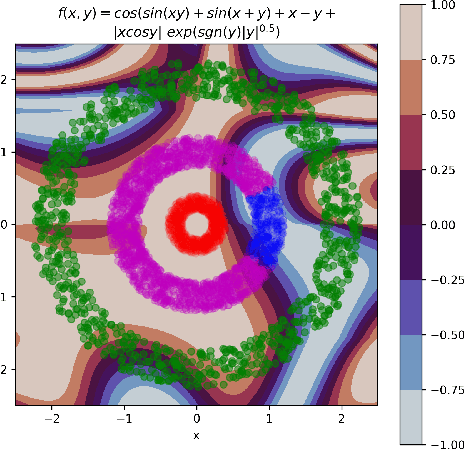
Modern machine learning models usually do not extrapolate well, i.e., they often have high prediction errors in the regions of sample space lying far from the training data. In high dimensional spaces detecting out-of-distribution points becomes a non-trivial problem. Thus, uncertainty estimation for model predictions becomes crucial for the successful application of machine learning models in many applications. In this work, we show that increasing the diversity of realizations sampled from a neural network with dropout helps to improve the quality of uncertainty estimation. In a series of experiments on simulated and real-world data, we demonstrate that diversification via determinantal point processes-based sampling allows achieving state-of-the-art results in uncertainty estimation for regression and classification tasks. Importantly, our approach does not require any modification to the models or training procedures, allowing for straightforward application to any deep learning model with dropout layers.
Deeper Connections between Neural Networks and Gaussian Processes Speed-up Active Learning
Feb 27, 2019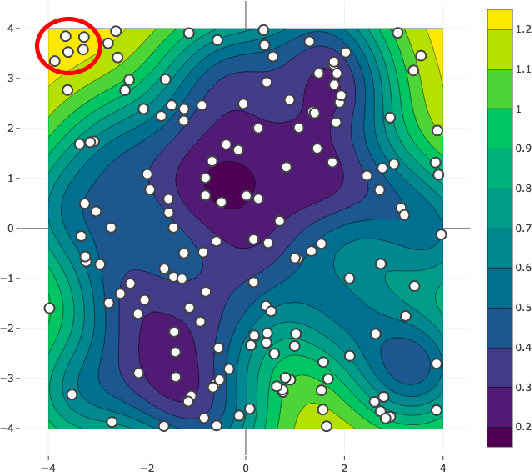
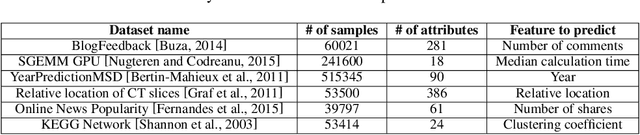
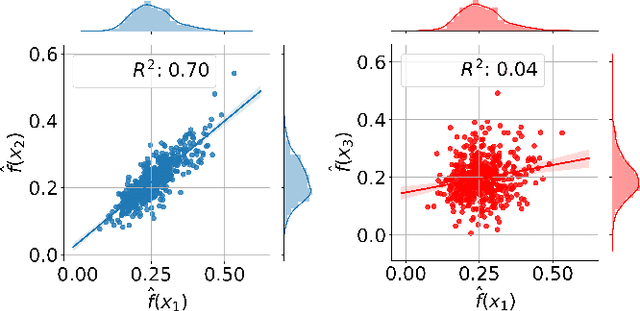
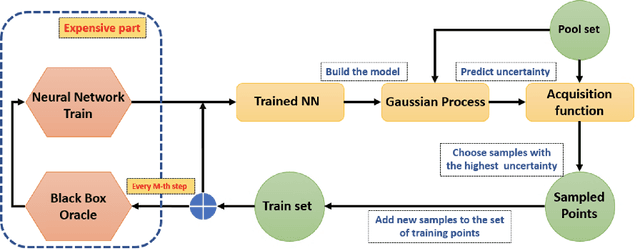
Active learning methods for neural networks are usually based on greedy criteria which ultimately give a single new design point for the evaluation. Such an approach requires either some heuristics to sample a batch of design points at one active learning iteration, or retraining the neural network after adding each data point, which is computationally inefficient. Moreover, uncertainty estimates for neural networks sometimes are overconfident for the points lying far from the training sample. In this work we propose to approximate Bayesian neural networks (BNN) by Gaussian processes, which allows us to update the uncertainty estimates of predictions efficiently without retraining the neural network, while avoiding overconfident uncertainty prediction for out-of-sample points. In a series of experiments on real-world data including large-scale problems of chemical and physical modeling, we show superiority of the proposed approach over the state-of-the-art methods.
Dropout-based Active Learning for Regression
Jul 05, 2018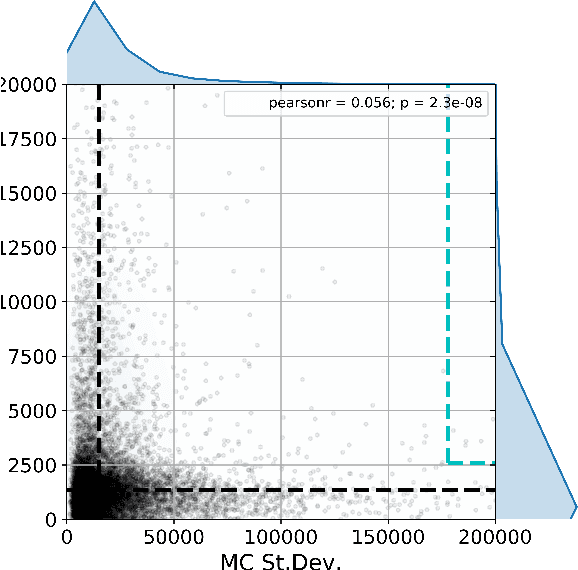
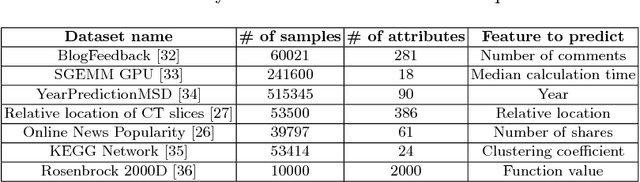
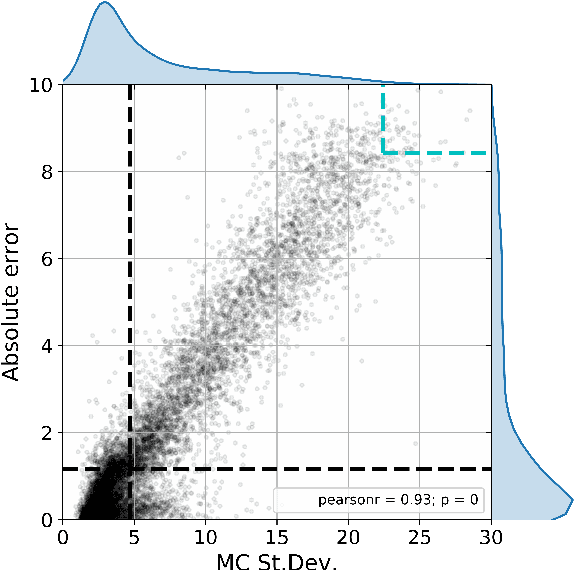
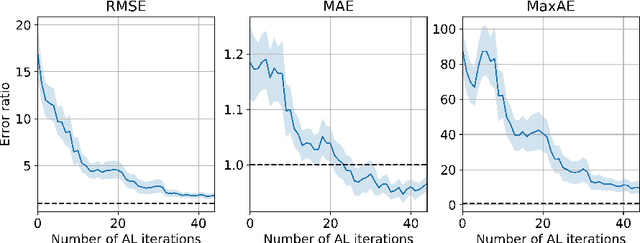
Active learning is relevant and challenging for high-dimensional regression models when the annotation of the samples is expensive. Yet most of the existing sampling methods cannot be applied to large-scale problems, consuming too much time for data processing. In this paper, we propose a fast active learning algorithm for regression, tailored for neural network models. It is based on uncertainty estimation from stochastic dropout output of the network. Experiments on both synthetic and real-world datasets show comparable or better performance (depending on the accuracy metric) as compared to the baselines. This approach can be generalized to other deep learning architectures. It can be used to systematically improve a machine-learning model as it offers a computationally efficient way of sampling additional data.
* Report on AIST 2018; will be published in Springer LNCS series (Analysis of Images, Social Networks and Texts - 7th International Conference, AIST 2018)