 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrompting and Fine-Tuning of Small LLMs for Length-Controllable Telephone Call Summarization
Oct 24, 2024



This paper explores the rapid development of a telephone call summarization system utilizing large language models (LLMs). Our approach involves initial experiments with prompting existing LLMs to generate summaries of telephone conversations, followed by the creation of a tailored synthetic training dataset utilizing stronger frontier models. We place special focus on the diversity of the generated data and on the ability to control the length of the generated summaries to meet various use-case specific requirements. The effectiveness of our method is evaluated using two state-of-the-art LLM-as-a-judge-based evaluation techniques to ensure the quality and relevance of the summaries. Our results show that fine-tuned Llama-2-7B-based summarization model performs on-par with GPT-4 in terms of factual accuracy, completeness and conciseness. Our findings demonstrate the potential for quickly bootstrapping a practical and efficient call summarization system.
Towards a World-English Language Model for On-Device Virtual Assistants
Mar 27, 2024



Neural Network Language Models (NNLMs) for Virtual Assistants (VAs) are generally language-, region-, and in some cases, device-dependent, which increases the effort to scale and maintain them. Combining NNLMs for one or more of the categories is one way to improve scalability. In this work, we combine regional variants of English to build a ``World English'' NNLM for on-device VAs. In particular, we investigate the application of adapter bottlenecks to model dialect-specific characteristics in our existing production NNLMs {and enhance the multi-dialect baselines}. We find that adapter modules are more effective in modeling dialects than specializing entire sub-networks. Based on this insight and leveraging the design of our production models, we introduce a new architecture for World English NNLM that meets the accuracy, latency, and memory constraints of our single-dialect models.
ClimateGPT: Towards AI Synthesizing Interdisciplinary Research on Climate Change
Jan 17, 2024This paper introduces ClimateGPT, a model family of domain-specific large language models that synthesize interdisciplinary research on climate change. We trained two 7B models from scratch on a science-oriented dataset of 300B tokens. For the first model, the 4.2B domain-specific tokens were included during pre-training and the second was adapted to the climate domain after pre-training. Additionally, ClimateGPT-7B, 13B and 70B are continuously pre-trained from Llama~2 on a domain-specific dataset of 4.2B tokens. Each model is instruction fine-tuned on a high-quality and human-generated domain-specific dataset that has been created in close cooperation with climate scientists. To reduce the number of hallucinations, we optimize the model for retrieval augmentation and propose a hierarchical retrieval strategy. To increase the accessibility of our model to non-English speakers, we propose to make use of cascaded machine translation and show that this approach can perform comparably to natively multilingual models while being easier to scale to a large number of languages. Further, to address the intrinsic interdisciplinary aspect of climate change we consider different research perspectives. Therefore, the model can produce in-depth answers focusing on different perspectives in addition to an overall answer. We propose a suite of automatic climate-specific benchmarks to evaluate LLMs. On these benchmarks, ClimateGPT-7B performs on par with the ten times larger Llama-2-70B Chat model while not degrading results on general domain benchmarks. Our human evaluation confirms the trends we saw in our benchmarks. All models were trained and evaluated using renewable energy and are released publicly.
Translating away Translationese without Parallel Data
Oct 28, 2023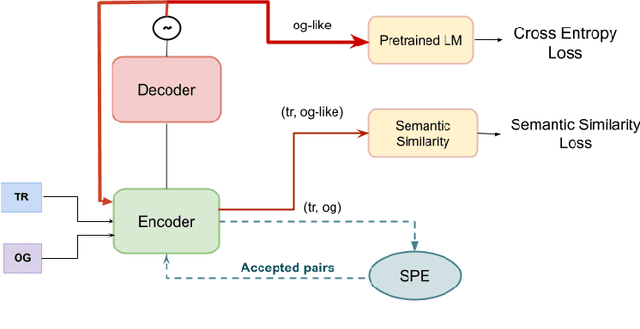

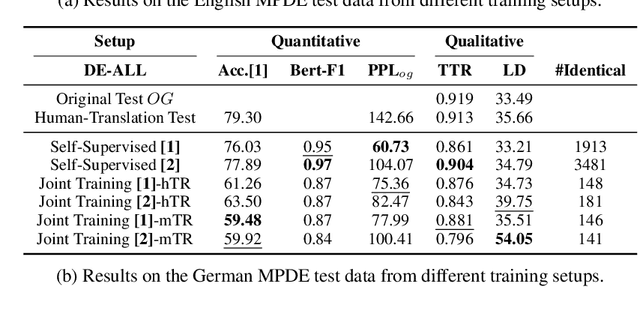

Translated texts exhibit systematic linguistic differences compared to original texts in the same language, and these differences are referred to as translationese. Translationese has effects on various cross-lingual natural language processing tasks, potentially leading to biased results. In this paper, we explore a novel approach to reduce translationese in translated texts: translation-based style transfer. As there are no parallel human-translated and original data in the same language, we use a self-supervised approach that can learn from comparable (rather than parallel) mono-lingual original and translated data. However, even this self-supervised approach requires some parallel data for validation. We show how we can eliminate the need for parallel validation data by combining the self-supervised loss with an unsupervised loss. This unsupervised loss leverages the original language model loss over the style-transferred output and a semantic similarity loss between the input and style-transferred output. We evaluate our approach in terms of original vs. translationese binary classification in addition to measuring content preservation and target-style fluency. The results show that our approach is able to reduce translationese classifier accuracy to a level of a random classifier after style transfer while adequately preserving the content and fluency in the target original style.
Towards Debiasing Translation Artifacts
May 16, 2022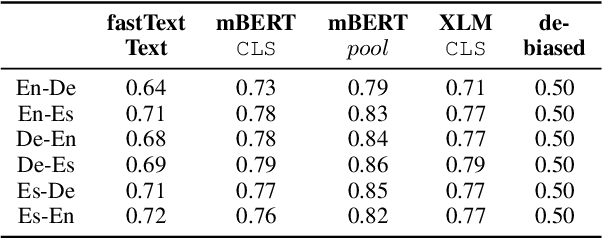
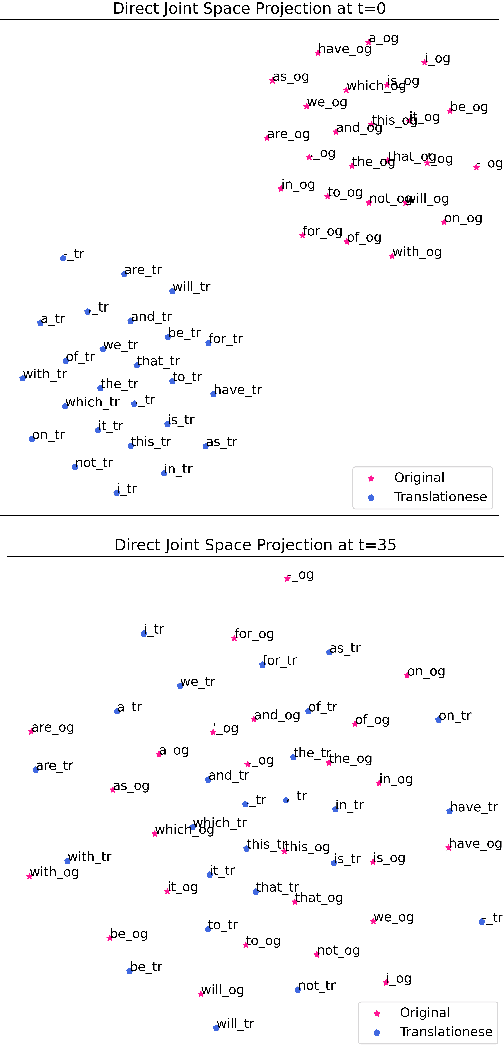
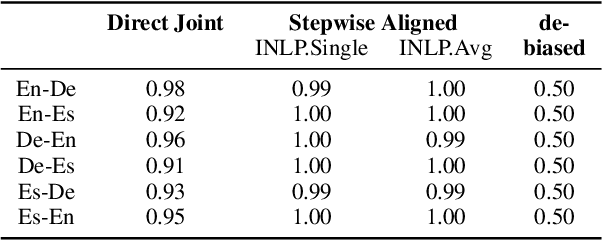
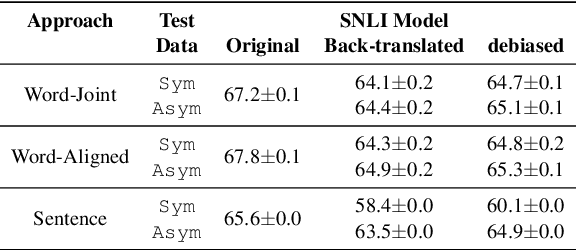
Cross-lingual natural language processing relies on translation, either by humans or machines, at different levels, from translating training data to translating test sets. However, compared to original texts in the same language, translations possess distinct qualities referred to as translationese. Previous research has shown that these translation artifacts influence the performance of a variety of cross-lingual tasks. In this work, we propose a novel approach to reducing translationese by extending an established bias-removal technique. We use the Iterative Null-space Projection (INLP) algorithm, and show by measuring classification accuracy before and after debiasing, that translationese is reduced at both sentence and word level. We evaluate the utility of debiasing translationese on a natural language inference (NLI) task, and show that by reducing this bias, NLI accuracy improves. To the best of our knowledge, this is the first study to debias translationese as represented in latent embedding space.
Knowledge Graph Question Answering using Graph-Pattern Isomorphism
Mar 11, 2021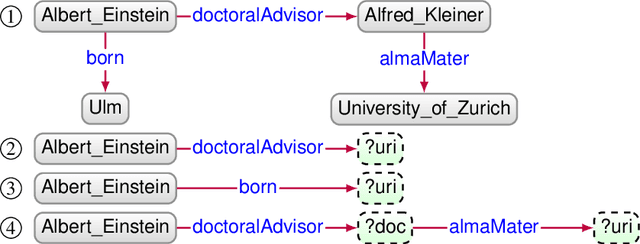

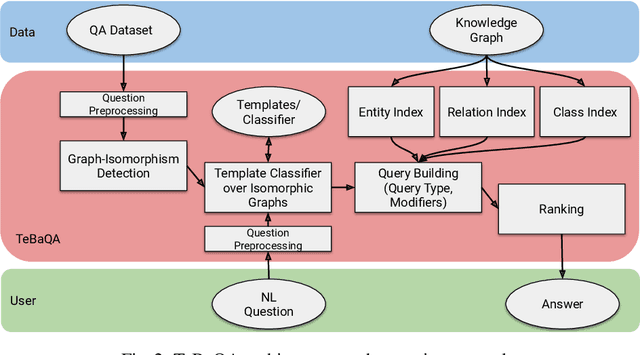

Knowledge Graph Question Answering (KGQA) systems are based on machine learning algorithms, requiring thousands of question-answer pairs as training examples or natural language processing pipelines that need module fine-tuning. In this paper, we present a novel QA approach, dubbed TeBaQA. Our approach learns to answer questions based on graph isomorphisms from basic graph patterns of SPARQL queries. Learning basic graph patterns is efficient due to the small number of possible patterns. This novel paradigm reduces the amount of training data necessary to achieve state-of-the-art performance. TeBaQA also speeds up the domain adaption process by transforming the QA system development task into a much smaller and easier data compilation task. In our evaluation, TeBaQA achieves state-of-the-art performance on QALD-8 and delivers comparable results on QALD-9 and LC-QuAD v1. Additionally, we performed a fine-grained evaluation on complex queries that deal with aggregation and superlative questions as well as an ablation study, highlighting future research challenges.
I-AID: Identifying Actionable Information from Disaster-related Tweets
Aug 04, 2020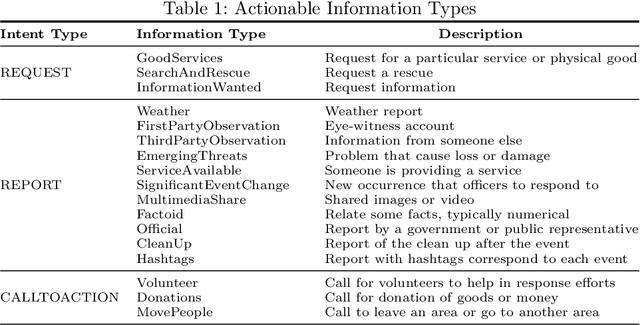
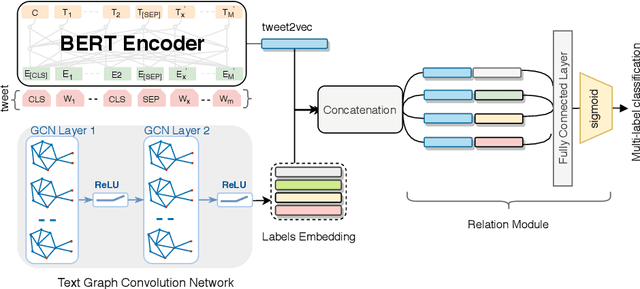
Social media data plays a significant role in modern disaster management by providing valuable data about affected people, donations, help requests, and advice. Recent studies highlight the need to filter information on social media into fine-grained content categories. However, identifying useful information from massive amounts of social media posts during a crisis is a challenging task. Automatically categorizing the information (e.g., reports on affected individuals, donations, and volunteers) contained in these posts is vital for their efficient handling and consumption by the communities affected and organizations concerned. In this paper, we propose a system, dubbed I-AID, to automatically filter tweets with critical or actionable information from the enormous volume of social media data. Our system combines state-of-the-art approaches to process and represents textual data in order to capture its underlying semantics. In particular, we use 1) Bidirectional Encoder Representations from Transformers (commonly known as, BERT) to learn a contextualized vector representation of a tweet, and 2) a graph-based architecture to compute semantic correlations between the entities and hashtags in tweets and their corresponding labels. We conducted our experiments on a real-world dataset of disaster-related tweets. Our experimental results indicate that our model outperforms state-of-the-art approaches baselines in terms of F1-score by +11%.