 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeListen to the Context: Towards Faithful Large Language Models for Retrieval Augmented Generation on Climate Questions
May 21, 2025Large language models that use retrieval augmented generation have the potential to unlock valuable knowledge for researchers, policymakers, and the public by making long and technical climate-related documents more accessible. While this approach can help alleviate factual hallucinations by relying on retrieved passages as additional context, its effectiveness depends on whether the model's output remains faithful to these passages. To address this, we explore the automatic assessment of faithfulness of different models in this setting. We then focus on ClimateGPT, a large language model specialised in climate science, to examine which factors in its instruction fine-tuning impact the model's faithfulness. By excluding unfaithful subsets of the model's training data, we develop ClimateGPT Faithful+, which achieves an improvement in faithfulness from 30% to 57% in supported atomic claims according to our automatic metric.
Prompting and Fine-Tuning of Small LLMs for Length-Controllable Telephone Call Summarization
Oct 24, 2024



This paper explores the rapid development of a telephone call summarization system utilizing large language models (LLMs). Our approach involves initial experiments with prompting existing LLMs to generate summaries of telephone conversations, followed by the creation of a tailored synthetic training dataset utilizing stronger frontier models. We place special focus on the diversity of the generated data and on the ability to control the length of the generated summaries to meet various use-case specific requirements. The effectiveness of our method is evaluated using two state-of-the-art LLM-as-a-judge-based evaluation techniques to ensure the quality and relevance of the summaries. Our results show that fine-tuned Llama-2-7B-based summarization model performs on-par with GPT-4 in terms of factual accuracy, completeness and conciseness. Our findings demonstrate the potential for quickly bootstrapping a practical and efficient call summarization system.
ClimateGPT: Towards AI Synthesizing Interdisciplinary Research on Climate Change
Jan 17, 2024This paper introduces ClimateGPT, a model family of domain-specific large language models that synthesize interdisciplinary research on climate change. We trained two 7B models from scratch on a science-oriented dataset of 300B tokens. For the first model, the 4.2B domain-specific tokens were included during pre-training and the second was adapted to the climate domain after pre-training. Additionally, ClimateGPT-7B, 13B and 70B are continuously pre-trained from Llama~2 on a domain-specific dataset of 4.2B tokens. Each model is instruction fine-tuned on a high-quality and human-generated domain-specific dataset that has been created in close cooperation with climate scientists. To reduce the number of hallucinations, we optimize the model for retrieval augmentation and propose a hierarchical retrieval strategy. To increase the accessibility of our model to non-English speakers, we propose to make use of cascaded machine translation and show that this approach can perform comparably to natively multilingual models while being easier to scale to a large number of languages. Further, to address the intrinsic interdisciplinary aspect of climate change we consider different research perspectives. Therefore, the model can produce in-depth answers focusing on different perspectives in addition to an overall answer. We propose a suite of automatic climate-specific benchmarks to evaluate LLMs. On these benchmarks, ClimateGPT-7B performs on par with the ten times larger Llama-2-70B Chat model while not degrading results on general domain benchmarks. Our human evaluation confirms the trends we saw in our benchmarks. All models were trained and evaluated using renewable energy and are released publicly.
Task-oriented Document-Grounded Dialog Systems by HLTPR@RWTH for DSTC9 and DSTC10
Apr 14, 2023

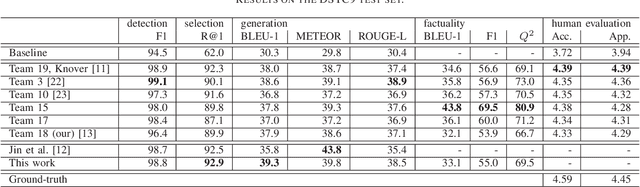
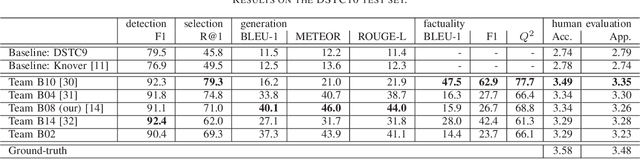
This paper summarizes our contributions to the document-grounded dialog tasks at the 9th and 10th Dialog System Technology Challenges (DSTC9 and DSTC10). In both iterations the task consists of three subtasks: first detect whether the current turn is knowledge seeking, second select a relevant knowledge document, and third generate a response grounded on the selected document. For DSTC9 we proposed different approaches to make the selection task more efficient. The best method, Hierarchical Selection, actually improves the results compared to the original baseline and gives a speedup of 24x. In the DSTC10 iteration of the task, the challenge was to adapt systems trained on written dialogs to perform well on noisy automatic speech recognition transcripts. Therefore, we proposed data augmentation techniques to increase the robustness of the models as well as methods to adapt the style of generated responses to fit well into the proceeding dialog. Additionally, we proposed a noisy channel model that allows for increasing the factuality of the generated responses. In addition to summarizing our previous contributions, in this work, we also report on a few small improvements and reconsider the automatic evaluation metrics for the generation task which have shown a low correlation to human judgments.
Controllable Factuality in Document-Grounded Dialog Systems Using a Noisy Channel Model
Oct 31, 2022



In this work, we present a model for document-grounded response generation in dialog that is decomposed into two components according to Bayes theorem. One component is a traditional ungrounded response generation model and the other component models the reconstruction of the grounding document based on the dialog context and generated response. We propose different approximate decoding schemes and evaluate our approach on multiple open-domain and task-oriented document-grounded dialog datasets. Our experiments show that the model is more factual in terms of automatic factuality metrics than the baseline model. Furthermore, we outline how introducing scaling factors between the components allows for controlling the tradeoff between factuality and fluency in the model output. Finally, we compare our approach to a recently proposed method to control factuality in grounded dialog, CTRL (arXiv:2107.06963), and show that both approaches can be combined to achieve additional improvements.
Adapting Document-Grounded Dialog Systems to Spoken Conversations using Data Augmentation and a Noisy Channel Model
Dec 16, 2021


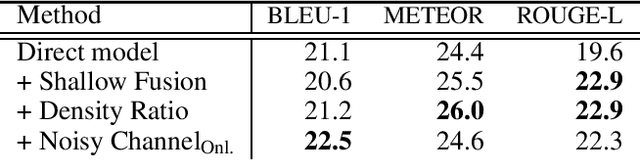
This paper summarizes our submission to Task 2 of the second track of the 10th Dialog System Technology Challenge (DSTC10) "Knowledge-grounded Task-oriented Dialogue Modeling on Spoken Conversations". Similar to the previous year's iteration, the task consists of three subtasks: detecting whether a turn is knowledge seeking, selecting the relevant knowledge document and finally generating a grounded response. This year, the focus lies on adapting the system to noisy ASR transcripts. We explore different approaches to make the models more robust to this type of input and to adapt the generated responses to the style of spoken conversations. For the latter, we get the best results with a noisy channel model that additionally reduces the number of short and generic responses. Our best system achieved the 1st rank in the automatic and the 3rd rank in the human evaluation of the challenge.
Investigation on Data Adaptation Techniques for Neural Named Entity Recognition
Oct 12, 2021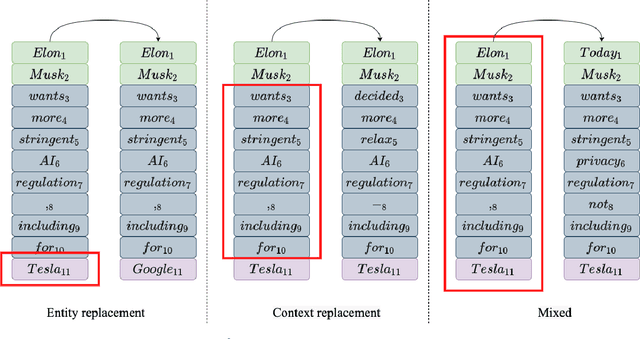
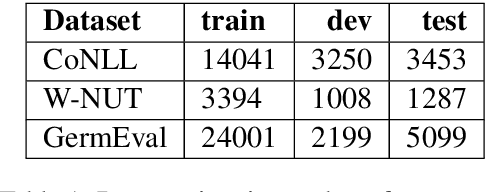
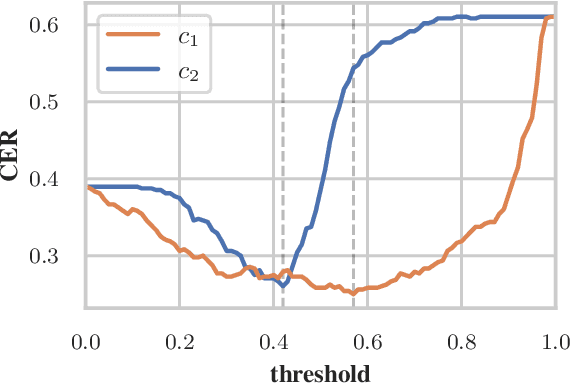
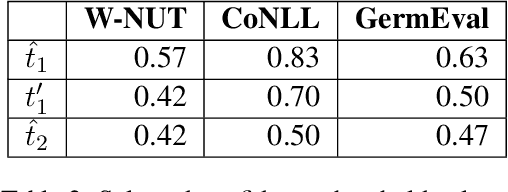
Data processing is an important step in various natural language processing tasks. As the commonly used datasets in named entity recognition contain only a limited number of samples, it is important to obtain additional labeled data in an efficient and reliable manner. A common practice is to utilize large monolingual unlabeled corpora. Another popular technique is to create synthetic data from the original labeled data (data augmentation). In this work, we investigate the impact of these two methods on the performance of three different named entity recognition tasks.
Cascaded Span Extraction and Response Generation for Document-Grounded Dialog
Jun 14, 2021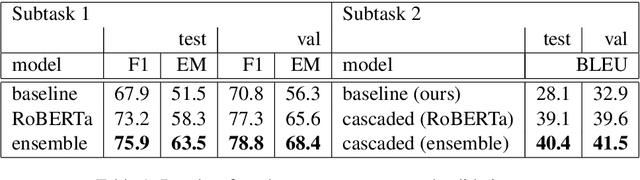
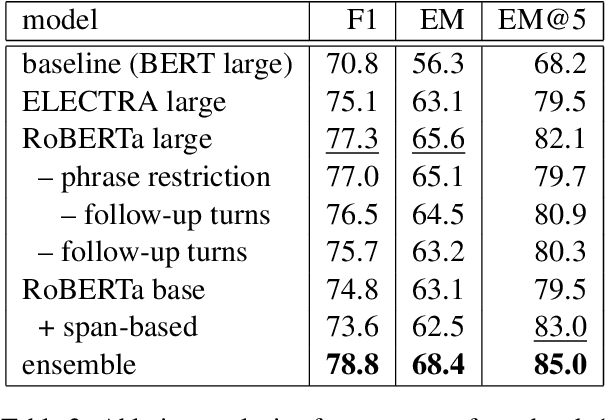
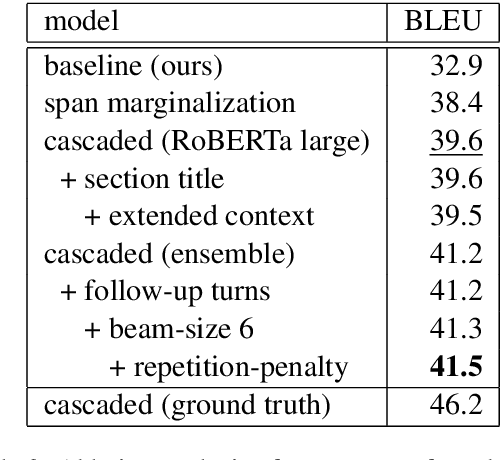
This paper summarizes our entries to both subtasks of the first DialDoc shared task which focuses on the agent response prediction task in goal-oriented document-grounded dialogs. The task is split into two subtasks: predicting a span in a document that grounds an agent turn and generating an agent response based on a dialog and grounding document. In the first subtask, we restrict the set of valid spans to the ones defined in the dataset, use a biaffine classifier to model spans, and finally use an ensemble of different models. For the second subtask, we use a cascaded model which grounds the response prediction on the predicted span instead of the full document. With these approaches, we obtain significant improvements in both subtasks compared to the baseline.
Efficient Retrieval Augmented Generation from Unstructured Knowledge for Task-Oriented Dialog
Feb 09, 2021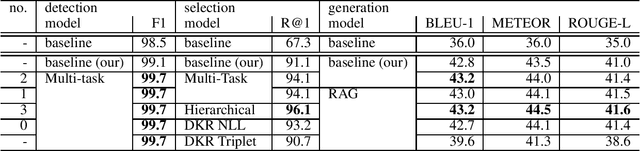
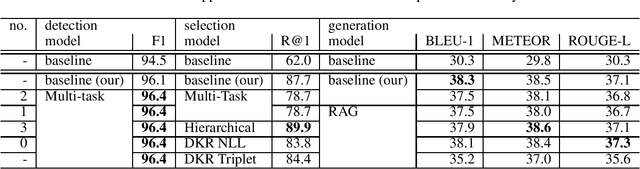

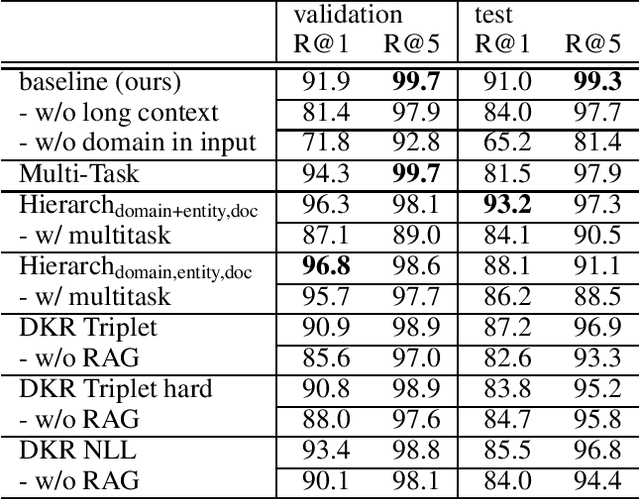
This paper summarizes our work on the first track of the ninth Dialog System Technology Challenge (DSTC 9), "Beyond Domain APIs: Task-oriented Conversational Modeling with Unstructured Knowledge Access". The goal of the task is to generate responses to user turns in a task-oriented dialog that require knowledge from unstructured documents. The task is divided into three subtasks: detection, selection and generation. In order to be compute efficient, we formulate the selection problem in terms of hierarchical classification steps. We achieve our best results with this model. Alternatively, we employ siamese sequence embedding models, referred to as Dense Knowledge Retrieval, to retrieve relevant documents. This method further reduces the computation time by a factor of more than 100x at the cost of degradation in R@1 of 5-6% compared to the first model. Then for either approach, we use Retrieval Augmented Generation to generate responses based on multiple selected snippets and we show how the method can be used to fine-tune trained embeddings.