 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhonetically-Augmented Discriminative Rescoring for Voice Search Error Correction
Jun 06, 2025End-to-end (E2E) Automatic Speech Recognition (ASR) models are trained using paired audio-text samples that are expensive to obtain, since high-quality ground-truth data requires human annotators. Voice search applications, such as digital media players, leverage ASR to allow users to search by voice as opposed to an on-screen keyboard. However, recent or infrequent movie titles may not be sufficiently represented in the E2E ASR system's training data, and hence, may suffer poor recognition. In this paper, we propose a phonetic correction system that consists of (a) a phonetic search based on the ASR model's output that generates phonetic alternatives that may not be considered by the E2E system, and (b) a rescorer component that combines the ASR model recognition and the phonetic alternatives, and select a final system output. We find that our approach improves word error rate between 4.4 and 7.6% relative on benchmarks of popular movie titles over a series of competitive baselines.
Synthetic Query Generation using Large Language Models for Virtual Assistants
Jun 10, 2024

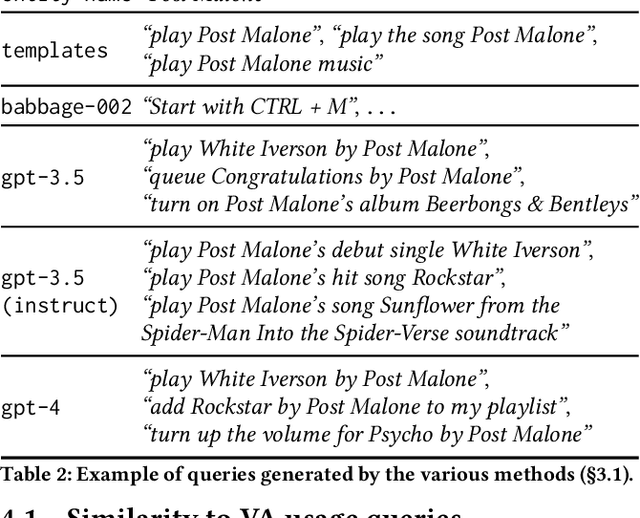
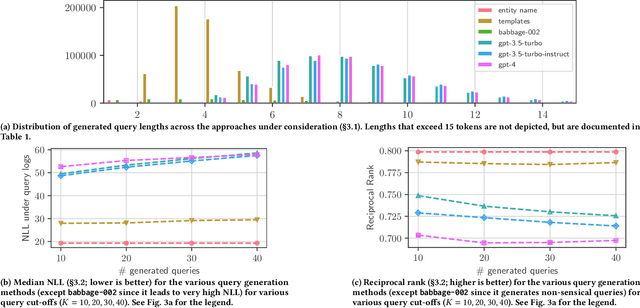
Virtual Assistants (VAs) are important Information Retrieval platforms that help users accomplish various tasks through spoken commands. The speech recognition system (speech-to-text) uses query priors, trained solely on text, to distinguish between phonetically confusing alternatives. Hence, the generation of synthetic queries that are similar to existing VA usage can greatly improve upon the VA's abilities -- especially for use-cases that do not (yet) occur in paired audio/text data. In this paper, we provide a preliminary exploration of the use of Large Language Models (LLMs) to generate synthetic queries that are complementary to template-based methods. We investigate whether the methods (a) generate queries that are similar to randomly sampled, representative, and anonymized user queries from a popular VA, and (b) whether the generated queries are specific. We find that LLMs generate more verbose queries, compared to template-based methods, and reference aspects specific to the entity. The generated queries are similar to VA user queries, and are specific enough to retrieve the relevant entity. We conclude that queries generated by LLMs and templates are complementary.
Towards a World-English Language Model for On-Device Virtual Assistants
Mar 27, 2024



Neural Network Language Models (NNLMs) for Virtual Assistants (VAs) are generally language-, region-, and in some cases, device-dependent, which increases the effort to scale and maintain them. Combining NNLMs for one or more of the categories is one way to improve scalability. In this work, we combine regional variants of English to build a ``World English'' NNLM for on-device VAs. In particular, we investigate the application of adapter bottlenecks to model dialect-specific characteristics in our existing production NNLMs {and enhance the multi-dialect baselines}. We find that adapter modules are more effective in modeling dialects than specializing entire sub-networks. Based on this insight and leveraging the design of our production models, we introduce a new architecture for World English NNLM that meets the accuracy, latency, and memory constraints of our single-dialect models.
Neural Language Model Pruning for Automatic Speech Recognition
Oct 05, 2023
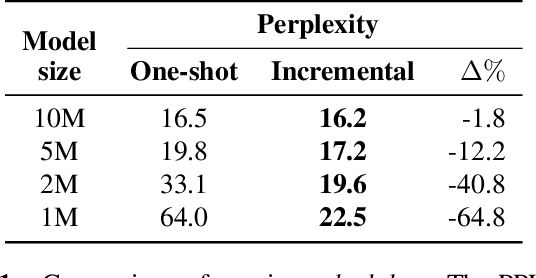


We study model pruning methods applied to Transformer-based neural network language models for automatic speech recognition. We explore three aspects of the pruning frame work, namely criterion, method and scheduler, analyzing their contribution in terms of accuracy and inference speed. To the best of our knowledge, such in-depth analyses on large-scale recognition systems has not been reported in the literature. In addition, we propose a variant of low-rank approximation suitable for incrementally compressing models, and delivering multiple models with varied target sizes. Among other results, we show that a) data-driven pruning outperforms magnitude-driven in several scenarios; b) incremental pruning achieves higher accuracy compared to one-shot pruning, especially when targeting smaller sizes; and c) low-rank approximation presents the best trade-off between size reduction and inference speed-up for moderate compression.
Application-Agnostic Language Modeling for On-Device ASR
May 16, 2023On-device automatic speech recognition systems face several challenges compared to server-based systems. They have to meet stricter constraints in terms of speed, disk size and memory while maintaining the same accuracy. Often they have to serve several applications with different distributions at once, such as communicating with a virtual assistant and speech-to-text. The simplest solution to serve multiple applications is to build application-specific (language) models, but this leads to an increase in memory. Therefore, we explore different data- and architecture-driven language modeling approaches to build a single application-agnostic model. We propose two novel feed-forward architectures that find an optimal trade off between different on-device constraints. In comparison to the application-specific solution, one of our novel approaches reduces the disk size by half, while maintaining speed and accuracy of the original model.
Space-Efficient Representation of Entity-centric Query Language Models
Jun 29, 2022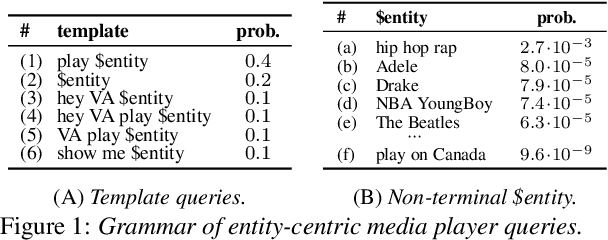

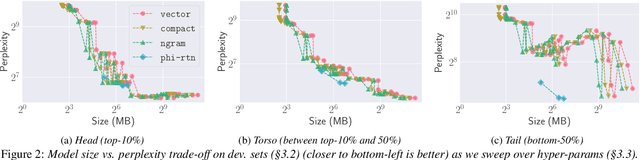
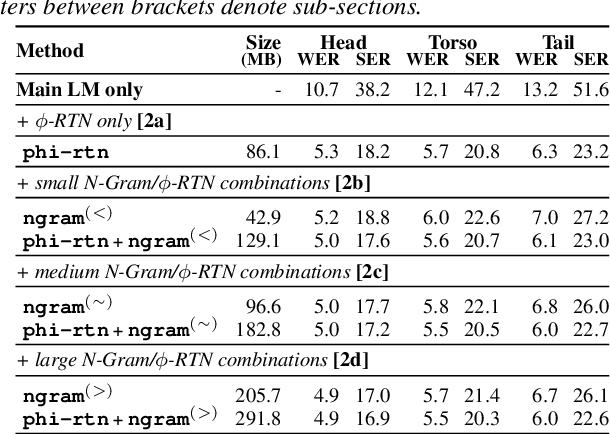
Virtual assistants make use of automatic speech recognition (ASR) to help users answer entity-centric queries. However, spoken entity recognition is a difficult problem, due to the large number of frequently-changing named entities. In addition, resources available for recognition are constrained when ASR is performed on-device. In this work, we investigate the use of probabilistic grammars as language models within the finite-state transducer (FST) framework. We introduce a deterministic approximation to probabilistic grammars that avoids the explicit expansion of non-terminals at model creation time, integrates directly with the FST framework, and is complementary to n-gram models. We obtain a 10% relative word error rate improvement on long tail entity queries compared to when a similarly-sized n-gram model is used without our method.
Connecting and Comparing Language Model Interpolation Techniques
Aug 26, 2019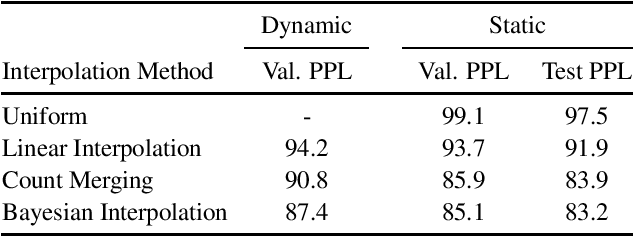
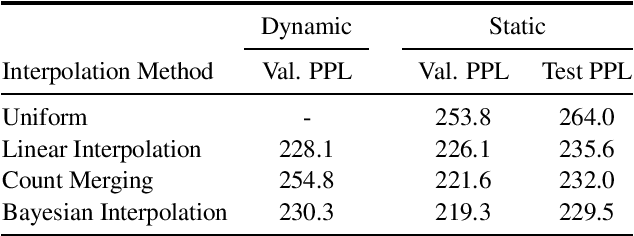
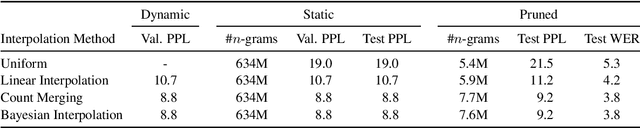
In this work, we uncover a theoretical connection between two language model interpolation techniques, count merging and Bayesian interpolation. We compare these techniques as well as linear interpolation in three scenarios with abundant training data per component model. Consistent with prior work, we show that both count merging and Bayesian interpolation outperform linear interpolation. We include the first (to our knowledge) published comparison of count merging and Bayesian interpolation, showing that the two techniques perform similarly. Finally, we argue that other considerations will make Bayesian interpolation the preferred approach in most circumstances.
A Neural Network Approach for Mixing Language Models
Aug 23, 2017



The performance of Neural Network (NN)-based language models is steadily improving due to the emergence of new architectures, which are able to learn different natural language characteristics. This paper presents a novel framework, which shows that a significant improvement can be achieved by combining different existing heterogeneous models in a single architecture. This is done through 1) a feature layer, which separately learns different NN-based models and 2) a mixture layer, which merges the resulting model features. In doing so, this architecture benefits from the learning capabilities of each model with no noticeable increase in the number of model parameters or the training time. Extensive experiments conducted on the Penn Treebank (PTB) and the Large Text Compression Benchmark (LTCB) corpus showed a significant reduction of the perplexity when compared to state-of-the-art feedforward as well as recurrent neural network architectures.
* Published at IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) 2017. arXiv admin note: text overlap with arXiv:1703.08068
Long-Short Range Context Neural Networks for Language Modeling
Aug 22, 2017

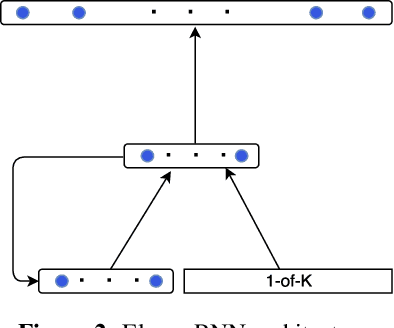
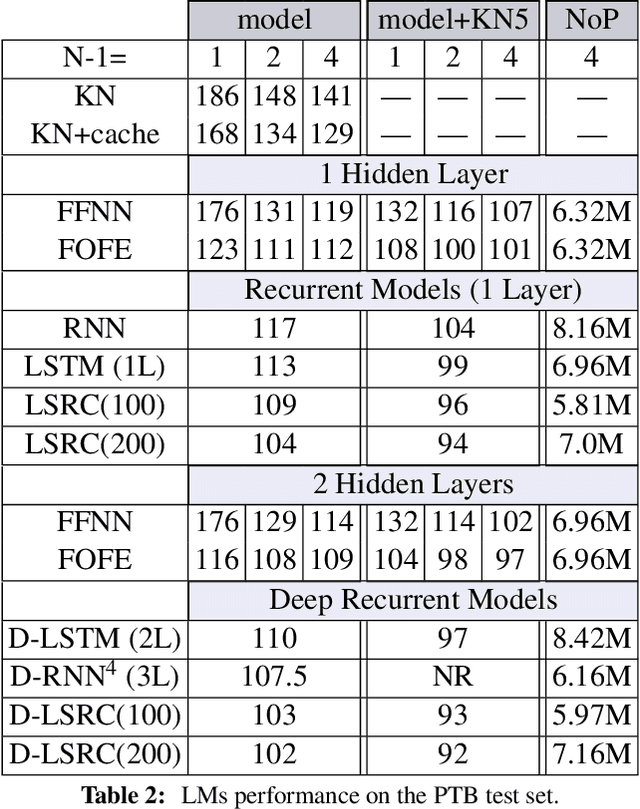
The goal of language modeling techniques is to capture the statistical and structural properties of natural languages from training corpora. This task typically involves the learning of short range dependencies, which generally model the syntactic properties of a language and/or long range dependencies, which are semantic in nature. We propose in this paper a new multi-span architecture, which separately models the short and long context information while it dynamically merges them to perform the language modeling task. This is done through a novel recurrent Long-Short Range Context (LSRC) network, which explicitly models the local (short) and global (long) context using two separate hidden states that evolve in time. This new architecture is an adaptation of the Long-Short Term Memory network (LSTM) to take into account the linguistic properties. Extensive experiments conducted on the Penn Treebank (PTB) and the Large Text Compression Benchmark (LTCB) corpus showed a significant reduction of the perplexity when compared to state-of-the-art language modeling techniques.
A Batch Noise Contrastive Estimation Approach for Training Large Vocabulary Language Models
Aug 22, 2017

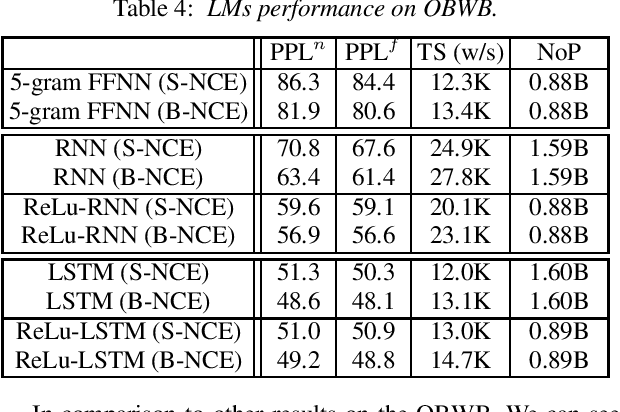
Training large vocabulary Neural Network Language Models (NNLMs) is a difficult task due to the explicit requirement of the output layer normalization, which typically involves the evaluation of the full softmax function over the complete vocabulary. This paper proposes a Batch Noise Contrastive Estimation (B-NCE) approach to alleviate this problem. This is achieved by reducing the vocabulary, at each time step, to the target words in the batch and then replacing the softmax by the noise contrastive estimation approach, where these words play the role of targets and noise samples at the same time. In doing so, the proposed approach can be fully formulated and implemented using optimal dense matrix operations. Applying B-NCE to train different NNLMs on the Large Text Compression Benchmark (LTCB) and the One Billion Word Benchmark (OBWB) shows a significant reduction of the training time with no noticeable degradation of the models performance. This paper also presents a new baseline comparative study of different standard NNLMs on the large OBWB on a single Titan-X GPU.