 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Batch Noise Contrastive Estimation Approach for Training Large Vocabulary Language Models
Paper and Code


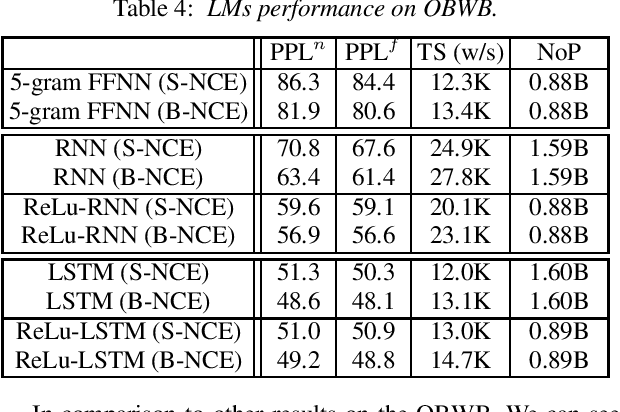
Training large vocabulary Neural Network Language Models (NNLMs) is a difficult task due to the explicit requirement of the output layer normalization, which typically involves the evaluation of the full softmax function over the complete vocabulary. This paper proposes a Batch Noise Contrastive Estimation (B-NCE) approach to alleviate this problem. This is achieved by reducing the vocabulary, at each time step, to the target words in the batch and then replacing the softmax by the noise contrastive estimation approach, where these words play the role of targets and noise samples at the same time. In doing so, the proposed approach can be fully formulated and implemented using optimal dense matrix operations. Applying B-NCE to train different NNLMs on the Large Text Compression Benchmark (LTCB) and the One Billion Word Benchmark (OBWB) shows a significant reduction of the training time with no noticeable degradation of the models performance. This paper also presents a new baseline comparative study of different standard NNLMs on the large OBWB on a single Titan-X GPU.