 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMovie Facts and Fibs (MF$^2$): A Benchmark for Long Movie Understanding
Jun 06, 2025Despite recent progress in vision-language models (VLMs), holistic understanding of long-form video content remains a significant challenge, partly due to limitations in current benchmarks. Many focus on peripheral, ``needle-in-a-haystack'' details, encouraging context-insensitive retrieval over deep comprehension. Others rely on large-scale, semi-automatically generated questions (often produced by language models themselves) that are easier for models to answer but fail to reflect genuine understanding. In this paper, we introduce MF$^2$, a new benchmark for evaluating whether models can comprehend, consolidate, and recall key narrative information from full-length movies (50-170 minutes long). MF$^2$ includes over 50 full-length, open-licensed movies, each paired with manually constructed sets of claim pairs -- one true (fact) and one plausible but false (fib), totalling over 850 pairs. These claims target core narrative elements such as character motivations and emotions, causal chains, and event order, and refer to memorable moments that humans can recall without rewatching the movie. Instead of multiple-choice formats, we adopt a binary claim evaluation protocol: for each pair, models must correctly identify both the true and false claims. This reduces biases like answer ordering and enables a more precise assessment of reasoning. Our experiments demonstrate that both open-weight and closed state-of-the-art models fall well short of human performance, underscoring the relative ease of the task for humans and their superior ability to retain and reason over critical narrative information -- an ability current VLMs lack.
From TOWER to SPIRE: Adding the Speech Modality to a Text-Only LLM
Mar 13, 2025Large language models (LLMs) have shown remarkable performance and generalization capabilities across multiple languages and tasks, making them very attractive targets for multi-modality integration (e.g., images or speech). In this work, we extend an existing LLM to the speech modality via speech discretization and continued pre-training. In particular, we are interested in multilingual LLMs, such as TOWER, as their pre-training setting allows us to treat discretized speech input as an additional translation language. The resulting open-source model, SPIRE, is able to transcribe and translate English speech input while maintaining TOWER's original performance on translation-related tasks, showcasing that discretized speech input integration as an additional language is feasible during LLM adaptation. We make our code and models available to the community.
Synthetic Query Generation using Large Language Models for Virtual Assistants
Jun 10, 2024

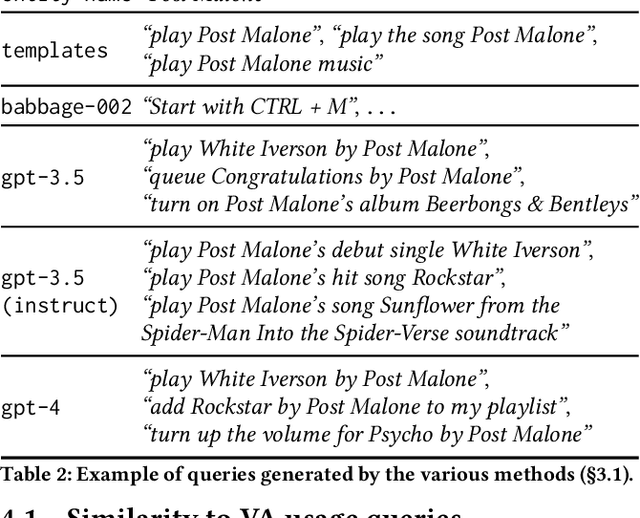
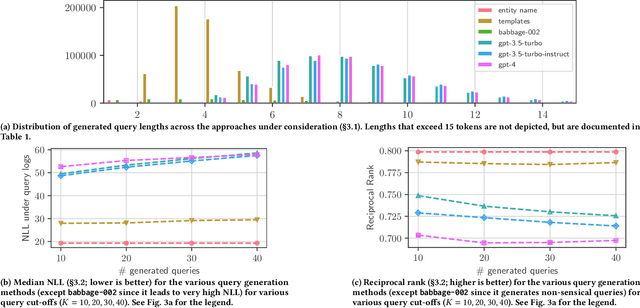
Virtual Assistants (VAs) are important Information Retrieval platforms that help users accomplish various tasks through spoken commands. The speech recognition system (speech-to-text) uses query priors, trained solely on text, to distinguish between phonetically confusing alternatives. Hence, the generation of synthetic queries that are similar to existing VA usage can greatly improve upon the VA's abilities -- especially for use-cases that do not (yet) occur in paired audio/text data. In this paper, we provide a preliminary exploration of the use of Large Language Models (LLMs) to generate synthetic queries that are complementary to template-based methods. We investigate whether the methods (a) generate queries that are similar to randomly sampled, representative, and anonymized user queries from a popular VA, and (b) whether the generated queries are specific. We find that LLMs generate more verbose queries, compared to template-based methods, and reference aspects specific to the entity. The generated queries are similar to VA user queries, and are specific enough to retrieve the relevant entity. We conclude that queries generated by LLMs and templates are complementary.
Investigating Lexical Sharing in Multilingual Machine Translation for Indian Languages
May 04, 2023

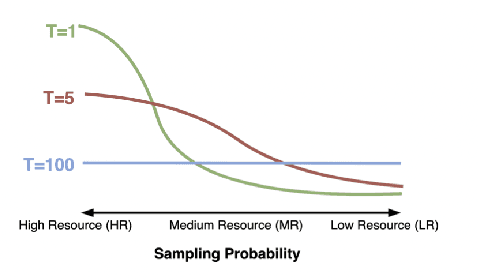
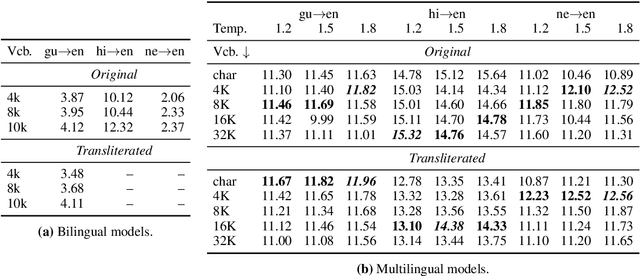
Multilingual language models have shown impressive cross-lingual transfer ability across a diverse set of languages and tasks. To improve the cross-lingual ability of these models, some strategies include transliteration and finer-grained segmentation into characters as opposed to subwords. In this work, we investigate lexical sharing in multilingual machine translation (MT) from Hindi, Gujarati, Nepali into English. We explore the trade-offs that exist in translation performance between data sampling and vocabulary size, and we explore whether transliteration is useful in encouraging cross-script generalisation. We also verify how the different settings generalise to unseen languages (Marathi and Bengali). We find that transliteration does not give pronounced improvements and our analysis suggests that our multilingual MT models trained on original scripts seem to already be robust to cross-script differences even for relatively low-resource languages
Are the Best Multilingual Document Embeddings simply Based on Sentence Embeddings?
Apr 28, 2023Dense vector representations for textual data are crucial in modern NLP. Word embeddings and sentence embeddings estimated from raw texts are key in achieving state-of-the-art results in various tasks requiring semantic understanding. However, obtaining embeddings at the document level is challenging due to computational requirements and lack of appropriate data. Instead, most approaches fall back on computing document embeddings based on sentence representations. Although there exist architectures and models to encode documents fully, they are in general limited to English and few other high-resourced languages. In this work, we provide a systematic comparison of methods to produce document-level representations from sentences based on LASER, LaBSE, and Sentence BERT pre-trained multilingual models. We compare input token number truncation, sentence averaging as well as some simple windowing and in some cases new augmented and learnable approaches, on 3 multi- and cross-lingual tasks in 8 languages belonging to 3 different language families. Our task-based extrinsic evaluations show that, independently of the language, a clever combination of sentence embeddings is usually better than encoding the full document as a single unit, even when this is possible. We demonstrate that while a simple sentence average results in a strong baseline for classification tasks, more complex combinations are necessary for semantic tasks.
Isomorphic Cross-lingual Embeddings for Low-Resource Languages
Mar 28, 2022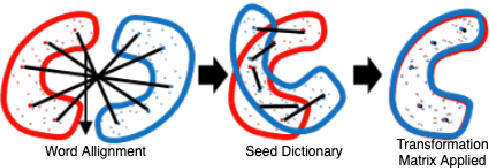
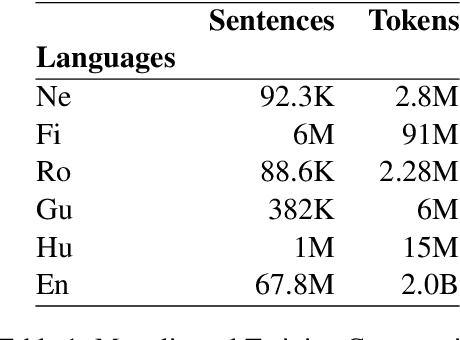
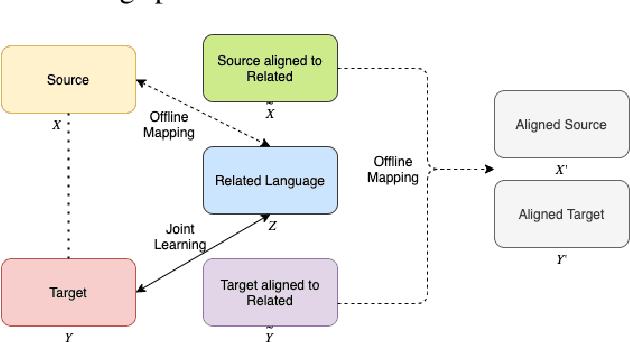

Cross-Lingual Word Embeddings (CLWEs) are a key component to transfer linguistic information learnt from higher-resource settings into lower-resource ones. Recent research in cross-lingual representation learning has focused on offline mapping approaches due to their simplicity, computational efficacy, and ability to work with minimal parallel resources. However, they crucially depend on the assumption of embedding spaces being approximately isomorphic i.e. sharing similar geometric structure, which does not hold in practice, leading to poorer performance on low-resource and distant language pairs. In this paper, we introduce a framework to learn CLWEs, without assuming isometry, for low-resource pairs via joint exploitation of a related higher-resource language. In our work, we first pre-align the low-resource and related language embedding spaces using offline methods to mitigate the assumption of isometry. Following this, we use joint training methods to develops CLWEs for the related language and the target embed-ding space. Finally, we remap the pre-aligned low-resource space and the target space to generate the final CLWEs. We show consistent gains over current methods in both quality and degree of isomorphism, as measured by bilingual lexicon induction (BLI) and eigenvalue similarity respectively, across several language pairs: {Nepali, Finnish, Romanian, Gujarati, Hungarian}-English. Lastly, our analysis also points to the relatedness as well as the amount of related language data available as being key factors in determining the quality of embeddings achieved.