 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom TOWER to SPIRE: Adding the Speech Modality to a Text-Only LLM
Mar 13, 2025Large language models (LLMs) have shown remarkable performance and generalization capabilities across multiple languages and tasks, making them very attractive targets for multi-modality integration (e.g., images or speech). In this work, we extend an existing LLM to the speech modality via speech discretization and continued pre-training. In particular, we are interested in multilingual LLMs, such as TOWER, as their pre-training setting allows us to treat discretized speech input as an additional translation language. The resulting open-source model, SPIRE, is able to transcribe and translate English speech input while maintaining TOWER's original performance on translation-related tasks, showcasing that discretized speech input integration as an additional language is feasible during LLM adaptation. We make our code and models available to the community.
Enhancing Context Through Contrast
Jan 06, 2024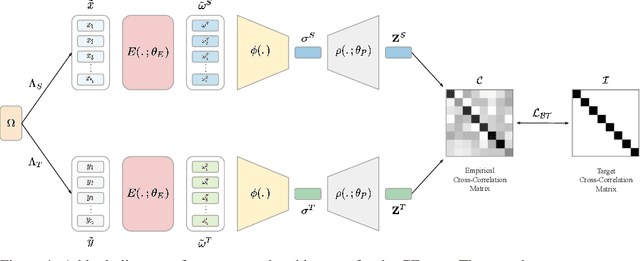
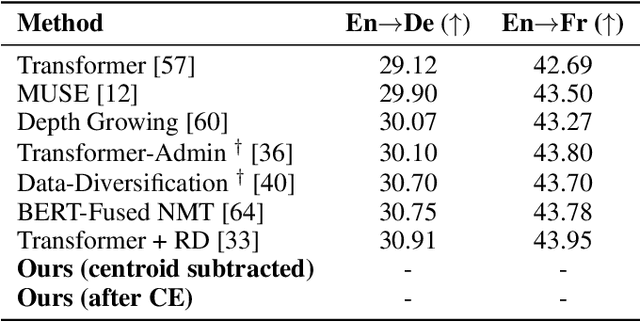
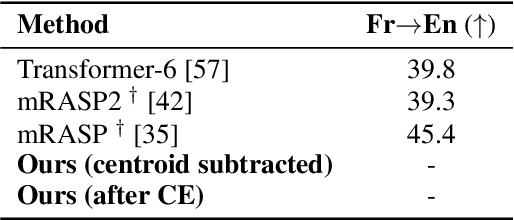
Neural machine translation benefits from semantically rich representations. Considerable progress in learning such representations has been achieved by language modelling and mutual information maximization objectives using contrastive learning. The language-dependent nature of language modelling introduces a trade-off between the universality of the learned representations and the model's performance on the language modelling tasks. Although contrastive learning improves performance, its success cannot be attributed to mutual information alone. We propose a novel Context Enhancement step to improve performance on neural machine translation by maximizing mutual information using the Barlow Twins loss. Unlike other approaches, we do not explicitly augment the data but view languages as implicit augmentations, eradicating the risk of disrupting semantic information. Further, our method does not learn embeddings from scratch and can be generalised to any set of pre-trained embeddings. Finally, we evaluate the language-agnosticism of our embeddings through language classification and use them for neural machine translation to compare with state-of-the-art approaches.