 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Context Through Contrast
Paper and Code
Jan 06, 2024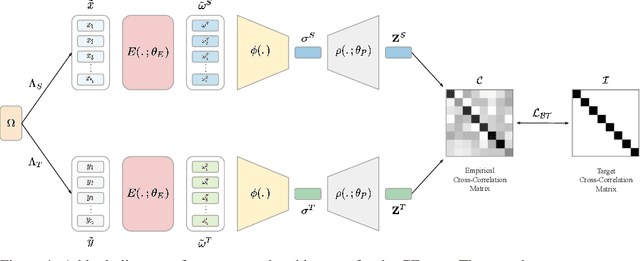
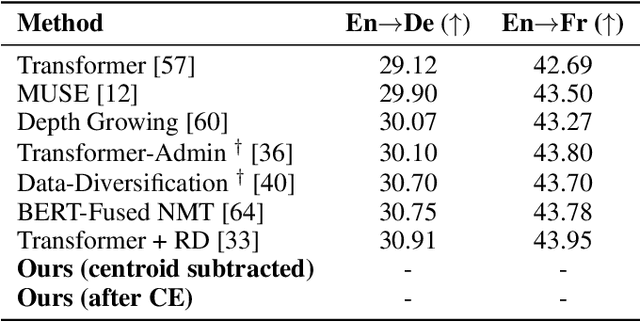
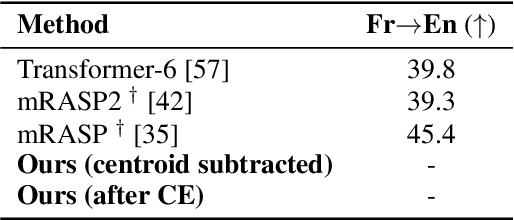
Neural machine translation benefits from semantically rich representations. Considerable progress in learning such representations has been achieved by language modelling and mutual information maximization objectives using contrastive learning. The language-dependent nature of language modelling introduces a trade-off between the universality of the learned representations and the model's performance on the language modelling tasks. Although contrastive learning improves performance, its success cannot be attributed to mutual information alone. We propose a novel Context Enhancement step to improve performance on neural machine translation by maximizing mutual information using the Barlow Twins loss. Unlike other approaches, we do not explicitly augment the data but view languages as implicit augmentations, eradicating the risk of disrupting semantic information. Further, our method does not learn embeddings from scratch and can be generalised to any set of pre-trained embeddings. Finally, we evaluate the language-agnosticism of our embeddings through language classification and use them for neural machine translation to compare with state-of-the-art approaches.