 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Context Through Contrast
Jan 06, 2024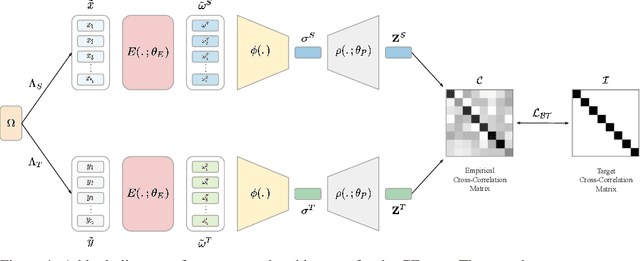
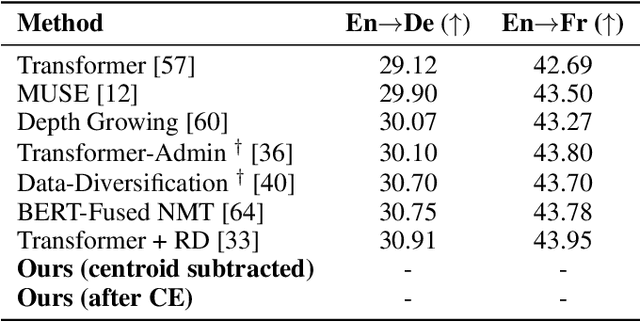
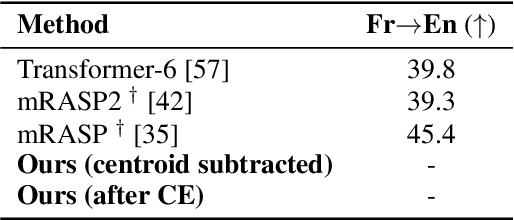
Neural machine translation benefits from semantically rich representations. Considerable progress in learning such representations has been achieved by language modelling and mutual information maximization objectives using contrastive learning. The language-dependent nature of language modelling introduces a trade-off between the universality of the learned representations and the model's performance on the language modelling tasks. Although contrastive learning improves performance, its success cannot be attributed to mutual information alone. We propose a novel Context Enhancement step to improve performance on neural machine translation by maximizing mutual information using the Barlow Twins loss. Unlike other approaches, we do not explicitly augment the data but view languages as implicit augmentations, eradicating the risk of disrupting semantic information. Further, our method does not learn embeddings from scratch and can be generalised to any set of pre-trained embeddings. Finally, we evaluate the language-agnosticism of our embeddings through language classification and use them for neural machine translation to compare with state-of-the-art approaches.
ReQuBiS -- Reconfigurable Quadrupedal-Bipedal Snake Robots
Jul 02, 2021
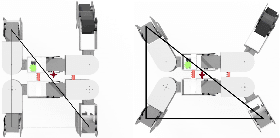
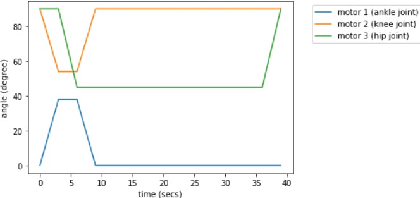
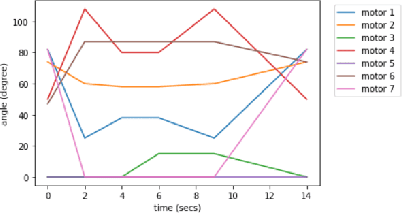
The selection of mobility modes for robot navigation consists of various trade-offs. Snake robots are ideal for traversing through constrained environments such as pipes, cluttered and rough terrain, whereas bipedal robots are more suited for structured environments such as stairs. Finally, quadruped robots are more stable than bipeds and can carry larger payloads than snakes and bipeds but struggle to navigate soft soil, sand, ice, and constrained environments. A reconfigurable robot can achieve the best of all worlds. Unfortunately, state-of-the-art reconfigurable robots rely on the rearrangement of modules through complicated mechanisms to dissemble and assemble at different places, increasing the size, weight, and power (SWaP) requirements. We propose Reconfigurable Quadrupedal-Bipedal Snake Robots (ReQuBiS), which can transform between mobility modes without rearranging modules. Hence, requiring just a single modification mechanism. Furthermore, our design allows the robot to split into two agents to perform tasks in parallel for biped and snake mobility. Experimental results demonstrate these mobility capabilities in snake, quadruped, and biped modes and transitions between them.
Design and Development of Autonomous Delivery Robot
Mar 16, 2021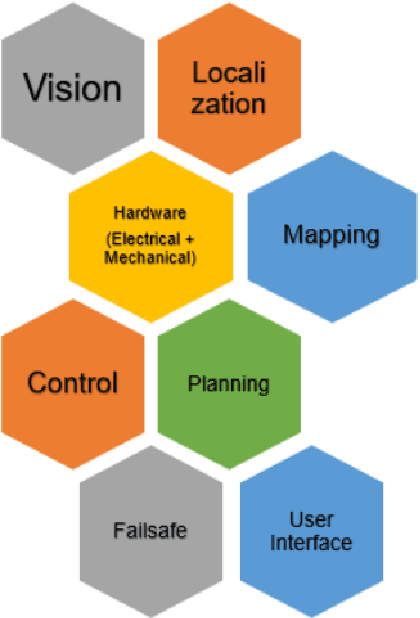
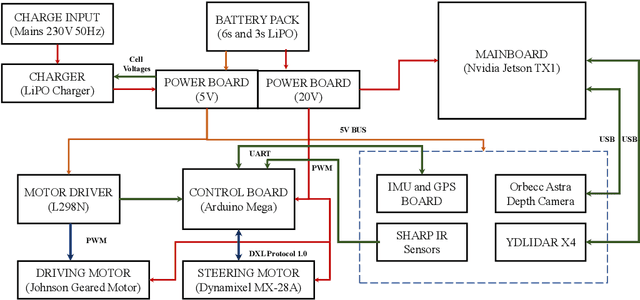
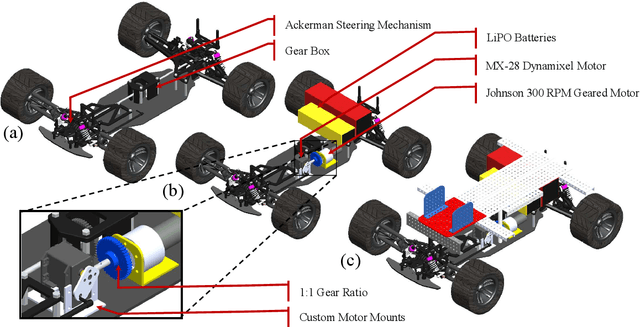

The field of autonomous robotics is growing at a rapid rate. The trend to use increasingly more sensors in vehicles is driven both by legislation and consumer demands for higher safety and reliable service. Nowadays, robots are found everywhere, ranging from homes, hospitals to industries, and military operations. Autonomous robots are developed to be robust enough to work beside humans and to carry out jobs efficiently. Humans have a natural sense of understanding of the physical forces acting around them like gravity, sense of motion, etc. which are not taught explicitly but are developed naturally. However, this is not the case with robots. To make the robot fully autonomous and competent to work with humans, the robot must be able to perceive the situation and devise a plan for smooth operation, considering all the adversities that may occur while carrying out the tasks. In this thesis, we present an autonomous mobile robot platform that delivers the package within the VNIT campus without any human intercommunication. From an initial user-supplied geographic target location, the system plans an optimized path and autonomously navigates through it. The entire pipeline of an autonomous robot working in outdoor environments is explained in detail in this thesis.
Stagewise Knowledge Distillation
Dec 10, 2019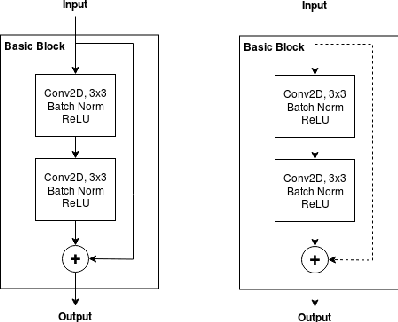
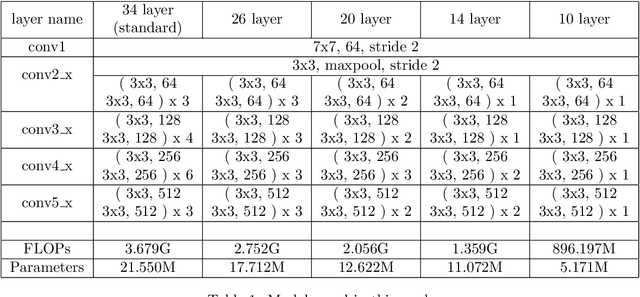
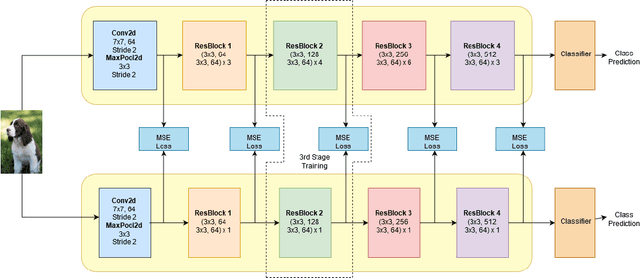
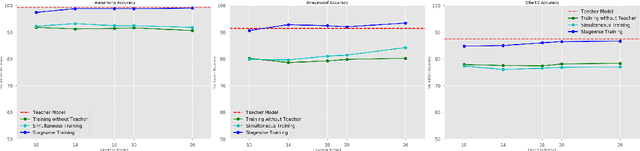
The deployment of modern Deep Learning models requires high computational power. However, many applications are targeted for embedded devices like smartphones and wearables which lack such computational abilities. This necessitates compact networks that reduce computations while preserving the performance. Knowledge Distillation is one of the methods used to achieve this. Traditional Knowledge Distillation methods transfer knowledge from teacher to student in a single stage. We propose progressive stagewise training to improve the transfer of knowledge. We also show that this method works even with a fraction of the data used for training the teacher model, without compromising on the metric. This method can complement other model compression methods and also can be viewed as a generalized model compression technique.