 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQUIDAM: A Framework for Quantization-Aware DNN Accelerator and Model Co-Exploration
Jun 30, 2022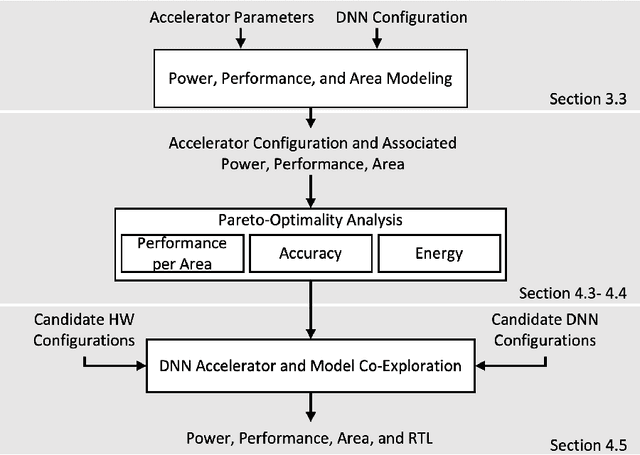
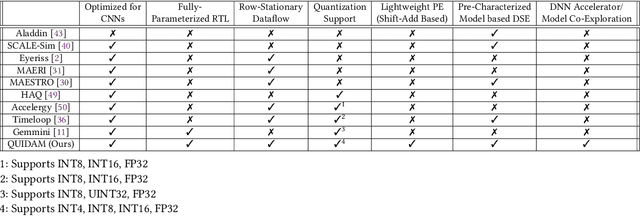
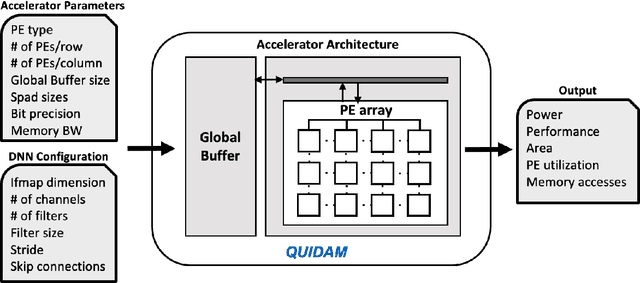
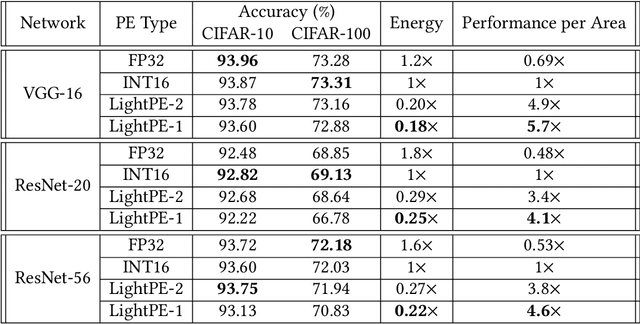
As the machine learning and systems communities strive to achieve higher energy-efficiency through custom deep neural network (DNN) accelerators, varied precision or quantization levels, and model compression techniques, there is a need for design space exploration frameworks that incorporate quantization-aware processing elements into the accelerator design space while having accurate and fast power, performance, and area models. In this work, we present QUIDAM, a highly parameterized quantization-aware DNN accelerator and model co-exploration framework. Our framework can facilitate future research on design space exploration of DNN accelerators for various design choices such as bit precision, processing element type, scratchpad sizes of processing elements, global buffer size, number of total processing elements, and DNN configurations. Our results show that different bit precisions and processing element types lead to significant differences in terms of performance per area and energy. Specifically, our framework identifies a wide range of design points where performance per area and energy varies more than 5x and 35x, respectively. With the proposed framework, we show that lightweight processing elements achieve on par accuracy results and up to 5.7x more performance per area and energy improvement when compared to the best INT16 based implementation. Finally, due to the efficiency of the pre-characterized power, performance, and area models, QUIDAM can speed up the design exploration process by 3-4 orders of magnitude as it removes the need for expensive synthesis and characterization of each design.
QADAM: Quantization-Aware DNN Accelerator Modeling for Pareto-Optimality
May 20, 2022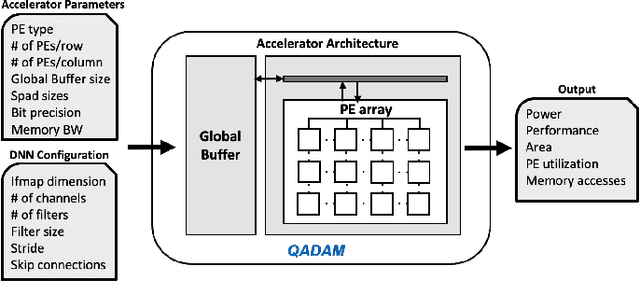
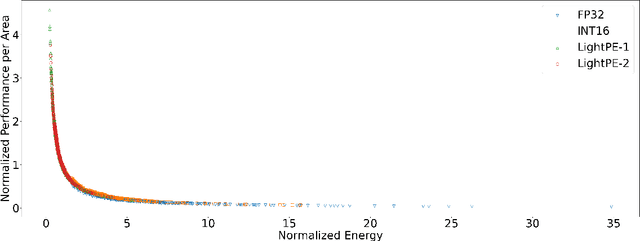
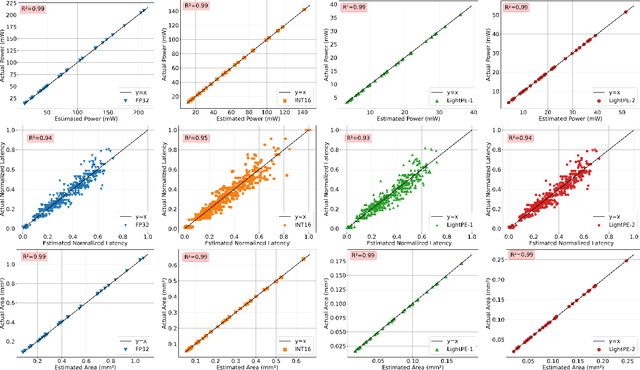
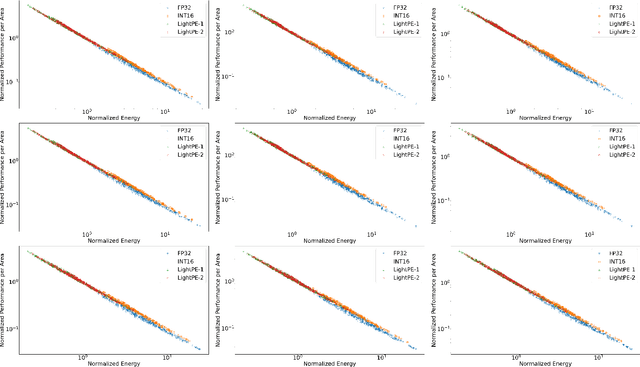
As the machine learning and systems communities strive to achieve higher energy-efficiency through custom deep neural network (DNN) accelerators, varied bit precision or quantization levels, there is a need for design space exploration frameworks that incorporate quantization-aware processing elements (PE) into the accelerator design space while having accurate and fast power, performance, and area models. In this work, we present QADAM, a highly parameterized quantization-aware power, performance, and area modeling framework for DNN accelerators. Our framework can facilitate future research on design space exploration and Pareto-efficiency of DNN accelerators for various design choices such as bit precision, PE type, scratchpad sizes of PEs, global buffer size, number of total PEs, and DNN configurations. Our results show that different bit precisions and PE types lead to significant differences in terms of performance per area and energy. Specifically, our framework identifies a wide range of design points where performance per area and energy varies more than 5x and 35x, respectively. We also show that the proposed lightweight processing elements (LightPEs) consistently achieve Pareto-optimal results in terms of accuracy and hardware-efficiency. With the proposed framework, we show that LightPEs achieve on par accuracy results and up to 5.7x more performance per area and energy improvement when compared to the best INT16 based design.
QAPPA: Quantization-Aware Power, Performance, and Area Modeling of DNN Accelerators
May 17, 2022
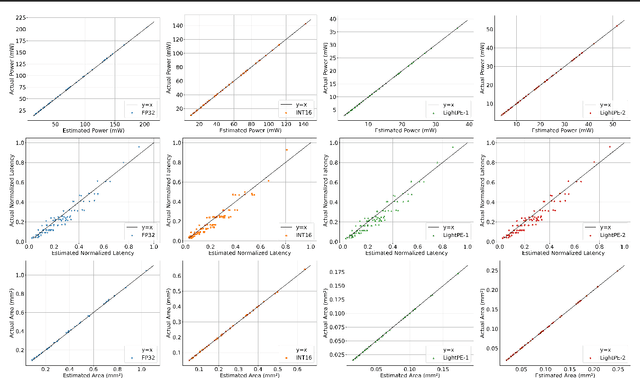
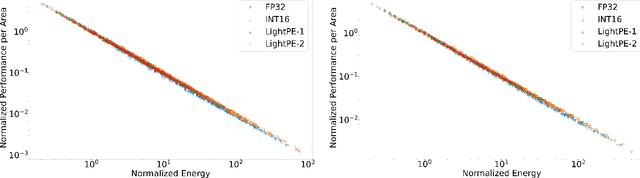

As the machine learning and systems community strives to achieve higher energy-efficiency through custom DNN accelerators and model compression techniques, there is a need for a design space exploration framework that incorporates quantization-aware processing elements into the accelerator design space while having accurate and fast power, performance, and area models. In this work, we present QAPPA, a highly parameterized quantization-aware power, performance, and area modeling framework for DNN accelerators. Our framework can facilitate the future research on design space exploration of DNN accelerators for various design choices such as bit precision, processing element type, scratchpad sizes of processing elements, global buffer size, device bandwidth, number of total processing elements in the the design, and DNN workloads. Our results show that different bit precisions and processing element types lead to significant differences in terms of performance per area and energy. Specifically, our proposed lightweight processing elements achieve up to 4.9x more performance per area and energy improvement when compared to INT16 based implementation.
Select, Substitute, Search: A New Benchmark for Knowledge-Augmented Visual Question Answering
Mar 23, 2021
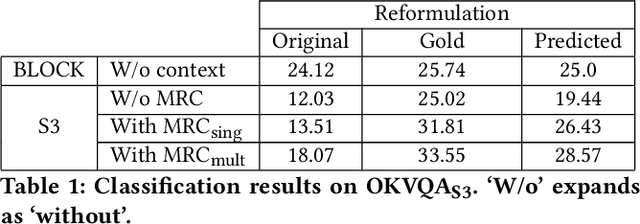


Multimodal IR, spanning text corpus, knowledge graph and images, called outside knowledge visual question answering (OKVQA), is of much recent interest. However, the popular data set has serious limitations. A surprisingly large fraction of queries do not assess the ability to integrate cross-modal information. Instead, some are independent of the image, some depend on speculation, some require OCR or are otherwise answerable from the image alone. To add to the above limitations, frequency-based guessing is very effective because of (unintended) widespread answer overlaps between the train and test folds. Overall, it is hard to determine when state-of-the-art systems exploit these weaknesses rather than really infer the answers, because they are opaque and their 'reasoning' process is uninterpretable. An equally important limitation is that the dataset is designed for the quantitative assessment only of the end-to-end answer retrieval task, with no provision for assessing the correct(semantic) interpretation of the input query. In response, we identify a key structural idiom in OKVQA ,viz., S3 (select, substitute and search), and build a new data set and challenge around it. Specifically, the questioner identifies an entity in the image and asks a question involving that entity which can be answered only by consulting a knowledge graph or corpus passage mentioning the entity. Our challenge consists of (i)OKVQAS3, a subset of OKVQA annotated based on the structural idiom and (ii)S3VQA, a new dataset built from scratch. We also present a neural but structurally transparent OKVQA system, S3, that explicitly addresses our challenge dataset, and outperforms recent competitive baselines.
Design and Development of Autonomous Delivery Robot
Mar 16, 2021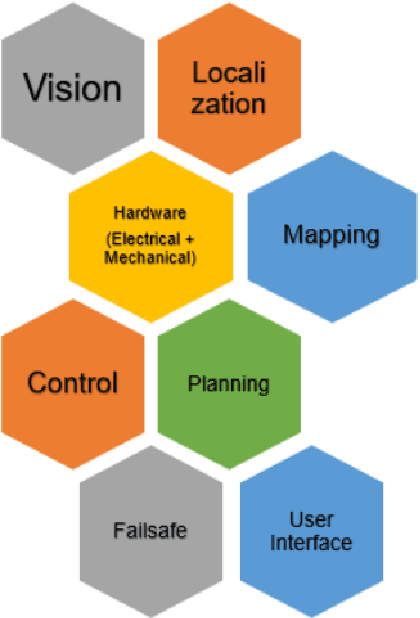
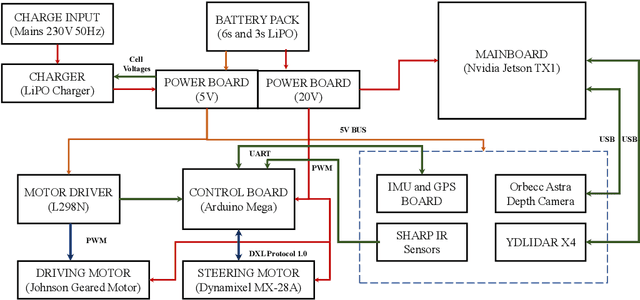
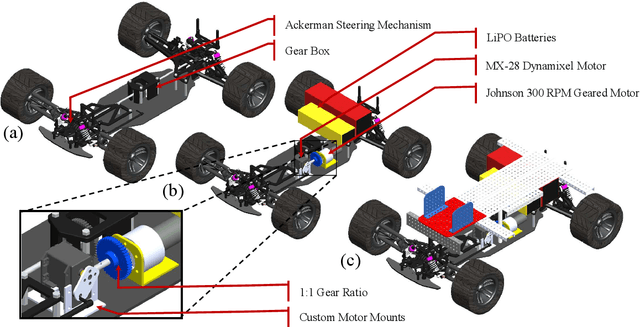

The field of autonomous robotics is growing at a rapid rate. The trend to use increasingly more sensors in vehicles is driven both by legislation and consumer demands for higher safety and reliable service. Nowadays, robots are found everywhere, ranging from homes, hospitals to industries, and military operations. Autonomous robots are developed to be robust enough to work beside humans and to carry out jobs efficiently. Humans have a natural sense of understanding of the physical forces acting around them like gravity, sense of motion, etc. which are not taught explicitly but are developed naturally. However, this is not the case with robots. To make the robot fully autonomous and competent to work with humans, the robot must be able to perceive the situation and devise a plan for smooth operation, considering all the adversities that may occur while carrying out the tasks. In this thesis, we present an autonomous mobile robot platform that delivers the package within the VNIT campus without any human intercommunication. From an initial user-supplied geographic target location, the system plans an optimized path and autonomously navigates through it. The entire pipeline of an autonomous robot working in outdoor environments is explained in detail in this thesis.