 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelect, Substitute, Search: A New Benchmark for Knowledge-Augmented Visual Question Answering
Paper and Code

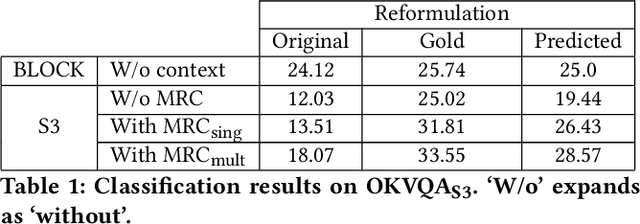


Multimodal IR, spanning text corpus, knowledge graph and images, called outside knowledge visual question answering (OKVQA), is of much recent interest. However, the popular data set has serious limitations. A surprisingly large fraction of queries do not assess the ability to integrate cross-modal information. Instead, some are independent of the image, some depend on speculation, some require OCR or are otherwise answerable from the image alone. To add to the above limitations, frequency-based guessing is very effective because of (unintended) widespread answer overlaps between the train and test folds. Overall, it is hard to determine when state-of-the-art systems exploit these weaknesses rather than really infer the answers, because they are opaque and their 'reasoning' process is uninterpretable. An equally important limitation is that the dataset is designed for the quantitative assessment only of the end-to-end answer retrieval task, with no provision for assessing the correct(semantic) interpretation of the input query. In response, we identify a key structural idiom in OKVQA ,viz., S3 (select, substitute and search), and build a new data set and challenge around it. Specifically, the questioner identifies an entity in the image and asks a question involving that entity which can be answered only by consulting a knowledge graph or corpus passage mentioning the entity. Our challenge consists of (i)OKVQAS3, a subset of OKVQA annotated based on the structural idiom and (ii)S3VQA, a new dataset built from scratch. We also present a neural but structurally transparent OKVQA system, S3, that explicitly addresses our challenge dataset, and outperforms recent competitive baselines.