 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiverse In-Context Example Selection After Decomposing Programs and Aligned Utterances Improves Semantic Parsing
Apr 04, 2025LLMs are increasingly used as seq2seq translators from natural language utterances to structured programs, a process called semantic interpretation. Unlike atomic labels or token sequences, programs are naturally represented as abstract syntax trees (ASTs). Such structured representation raises novel issues related to the design and selection of in-context examples (ICEs) presented to the LLM. We focus on decomposing the pool of available ICE trees into fragments, some of which may be better suited to solving the test instance. Next, we propose how to use (additional invocations of) an LLM with prompted syntax constraints to automatically map the fragments to corresponding utterances. Finally, we adapt and extend a recent method for diverse ICE selection to work with whole and fragmented ICE instances. We evaluate our system, SCUD4ICL, on popular diverse semantic parsing benchmarks, showing visible accuracy gains from our proposed decomposed diverse demonstration method. Benefits are particularly notable for smaller LLMs, ICE pools having larger labeled trees, and programs in lower resource languages.
CRUSH4SQL: Collective Retrieval Using Schema Hallucination For Text2SQL
Nov 02, 2023



Existing Text-to-SQL generators require the entire schema to be encoded with the user text. This is expensive or impractical for large databases with tens of thousands of columns. Standard dense retrieval techniques are inadequate for schema subsetting of a large structured database, where the correct semantics of retrieval demands that we rank sets of schema elements rather than individual elements. In response, we propose a two-stage process for effective coverage during retrieval. First, we instruct an LLM to hallucinate a minimal DB schema deemed adequate to answer the query. We use the hallucinated schema to retrieve a subset of the actual schema, by composing the results from multiple dense retrievals. Remarkably, hallucination $\unicode{x2013}$ generally considered a nuisance $\unicode{x2013}$ turns out to be actually useful as a bridging mechanism. Since no existing benchmarks exist for schema subsetting on large databases, we introduce three benchmarks. Two semi-synthetic datasets are derived from the union of schemas in two well-known datasets, SPIDER and BIRD, resulting in 4502 and 798 schema elements respectively. A real-life benchmark called SocialDB is sourced from an actual large data warehouse comprising 17844 schema elements. We show that our method1 leads to significantly higher recall than SOTA retrieval-based augmentation methods.
Personalizing ASR with limited data using targeted subset selection
Oct 29, 2021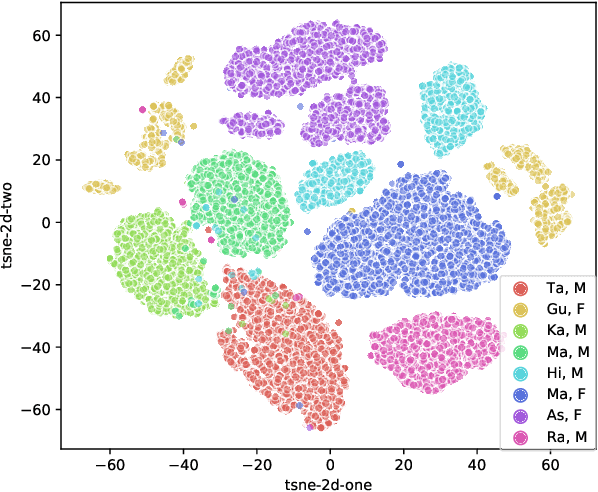
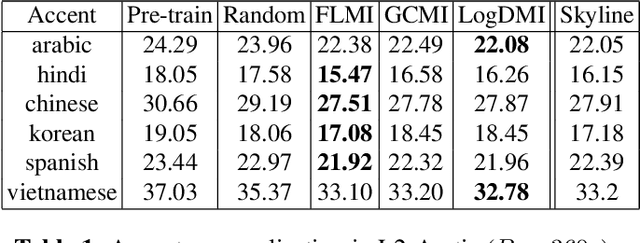

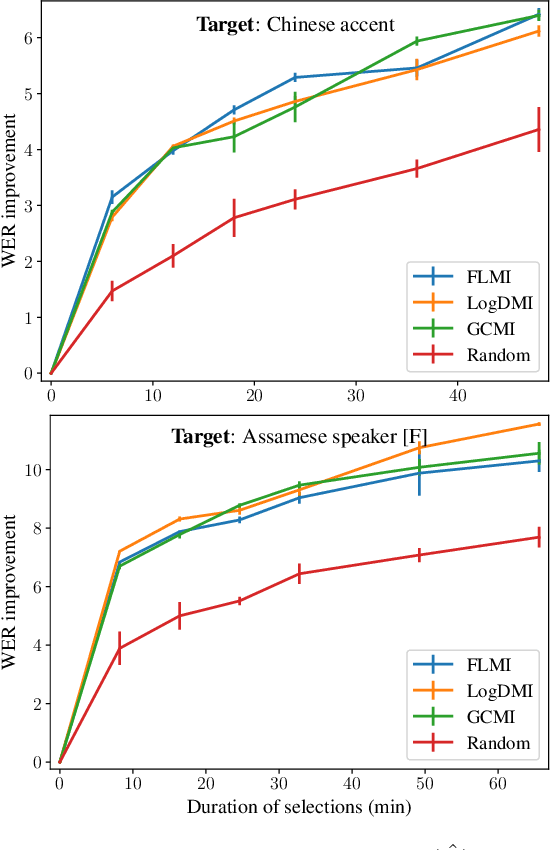
We study the task of personalizing ASR models to a target non-native speaker/accent while being constrained by a transcription budget on the duration of utterances selected from a large unlabelled corpus. We propose a subset selection approach using the recently proposed submodular mutual information functions, in which we identify a diverse set of utterances that match the target speaker/accent. This is specified through a few target utterances and achieved by modeling the relationship between the target subset and the selected subset using submodular mutual information functions. This method is applied at both the speaker and accent levels. We personalize the model by fine tuning it with utterances selected and transcribed from the unlabelled corpus. Our method is able to consistently identify utterances from the target speaker/accent using just speech features. We show that the targeted subset selection approach improves upon random sampling by as much as 2% to 5% (absolute) depending on the speaker and accent and is 2x to 4x more label-efficient compared to random sampling. We also compare with a skyline where we specifically pick from the target and our method generally outperforms the oracle in its selections.
Select, Substitute, Search: A New Benchmark for Knowledge-Augmented Visual Question Answering
Mar 23, 2021
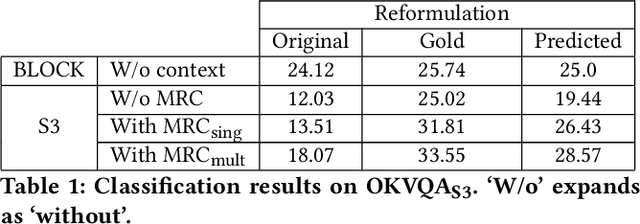


Multimodal IR, spanning text corpus, knowledge graph and images, called outside knowledge visual question answering (OKVQA), is of much recent interest. However, the popular data set has serious limitations. A surprisingly large fraction of queries do not assess the ability to integrate cross-modal information. Instead, some are independent of the image, some depend on speculation, some require OCR or are otherwise answerable from the image alone. To add to the above limitations, frequency-based guessing is very effective because of (unintended) widespread answer overlaps between the train and test folds. Overall, it is hard to determine when state-of-the-art systems exploit these weaknesses rather than really infer the answers, because they are opaque and their 'reasoning' process is uninterpretable. An equally important limitation is that the dataset is designed for the quantitative assessment only of the end-to-end answer retrieval task, with no provision for assessing the correct(semantic) interpretation of the input query. In response, we identify a key structural idiom in OKVQA ,viz., S3 (select, substitute and search), and build a new data set and challenge around it. Specifically, the questioner identifies an entity in the image and asks a question involving that entity which can be answered only by consulting a knowledge graph or corpus passage mentioning the entity. Our challenge consists of (i)OKVQAS3, a subset of OKVQA annotated based on the structural idiom and (ii)S3VQA, a new dataset built from scratch. We also present a neural but structurally transparent OKVQA system, S3, that explicitly addresses our challenge dataset, and outperforms recent competitive baselines.