 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersonalizing ASR with limited data using targeted subset selection
Oct 29, 2021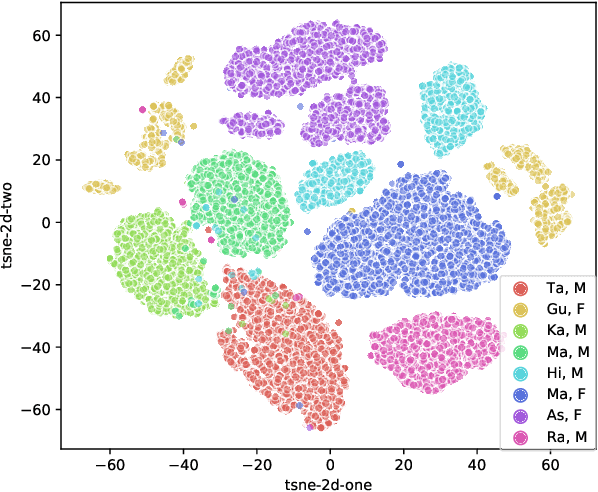
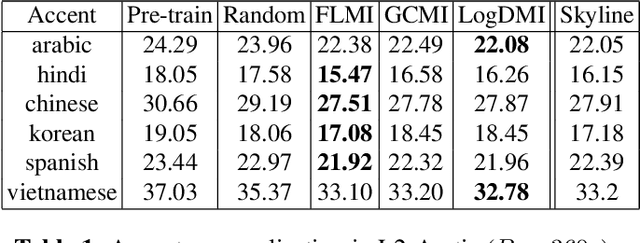

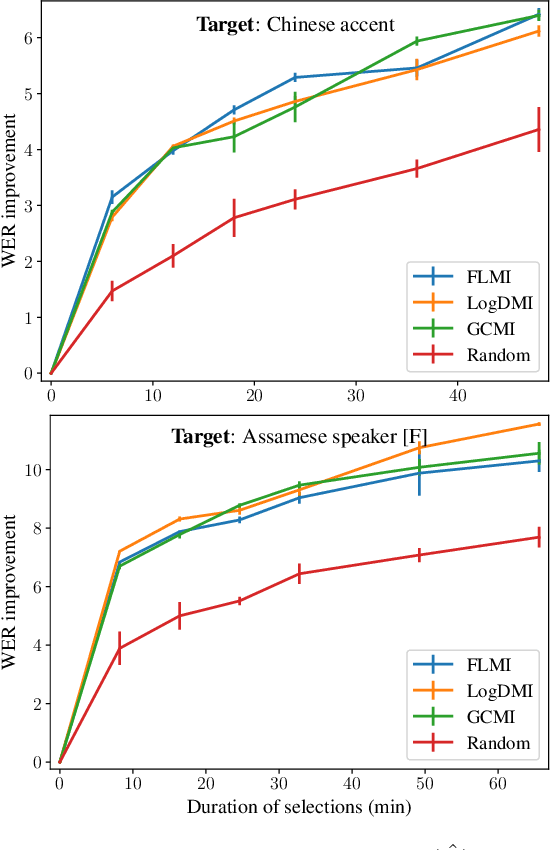
We study the task of personalizing ASR models to a target non-native speaker/accent while being constrained by a transcription budget on the duration of utterances selected from a large unlabelled corpus. We propose a subset selection approach using the recently proposed submodular mutual information functions, in which we identify a diverse set of utterances that match the target speaker/accent. This is specified through a few target utterances and achieved by modeling the relationship between the target subset and the selected subset using submodular mutual information functions. This method is applied at both the speaker and accent levels. We personalize the model by fine tuning it with utterances selected and transcribed from the unlabelled corpus. Our method is able to consistently identify utterances from the target speaker/accent using just speech features. We show that the targeted subset selection approach improves upon random sampling by as much as 2% to 5% (absolute) depending on the speaker and accent and is 2x to 4x more label-efficient compared to random sampling. We also compare with a skyline where we specifically pick from the target and our method generally outperforms the oracle in its selections.