 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiverse In-Context Example Selection After Decomposing Programs and Aligned Utterances Improves Semantic Parsing
Apr 04, 2025LLMs are increasingly used as seq2seq translators from natural language utterances to structured programs, a process called semantic interpretation. Unlike atomic labels or token sequences, programs are naturally represented as abstract syntax trees (ASTs). Such structured representation raises novel issues related to the design and selection of in-context examples (ICEs) presented to the LLM. We focus on decomposing the pool of available ICE trees into fragments, some of which may be better suited to solving the test instance. Next, we propose how to use (additional invocations of) an LLM with prompted syntax constraints to automatically map the fragments to corresponding utterances. Finally, we adapt and extend a recent method for diverse ICE selection to work with whole and fragmented ICE instances. We evaluate our system, SCUD4ICL, on popular diverse semantic parsing benchmarks, showing visible accuracy gains from our proposed decomposed diverse demonstration method. Benefits are particularly notable for smaller LLMs, ICE pools having larger labeled trees, and programs in lower resource languages.
Towards Robust Knowledge Representations in Multilingual LLMs for Equivalence and Inheritance based Consistent Reasoning
Oct 18, 2024
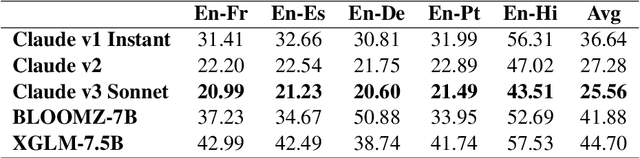


Reasoning and linguistic skills form the cornerstone of human intelligence, facilitating problem-solving and decision-making. Recent advances in Large Language Models (LLMs) have led to impressive linguistic capabilities and emergent reasoning behaviors, fueling widespread adoption across application domains. However, LLMs still struggle with complex reasoning tasks, highlighting their systemic limitations. In this work, we focus on evaluating whether LLMs have the requisite representations to reason using two foundational relationships: "equivalence" and "inheritance". We introduce novel tasks and benchmarks spanning six languages and observe that current SOTA LLMs often produce conflicting answers to the same questions across languages in 17.3-57.5% of cases and violate inheritance constraints in up to 37.2% cases. To enhance consistency across languages, we propose novel "Compositional Representations" where tokens are represented as composition of equivalent tokens across languages, with resulting conflict reduction (up to -4.7%) indicating benefits of shared LLM representations.
Intent Detection in the Age of LLMs
Oct 02, 2024



Intent detection is a critical component of task-oriented dialogue systems (TODS) which enables the identification of suitable actions to address user utterances at each dialog turn. Traditional approaches relied on computationally efficient supervised sentence transformer encoder models, which require substantial training data and struggle with out-of-scope (OOS) detection. The emergence of generative large language models (LLMs) with intrinsic world knowledge presents new opportunities to address these challenges. In this work, we adapt 7 SOTA LLMs using adaptive in-context learning and chain-of-thought prompting for intent detection, and compare their performance with contrastively fine-tuned sentence transformer (SetFit) models to highlight prediction quality and latency tradeoff. We propose a hybrid system using uncertainty based routing strategy to combine the two approaches that along with negative data augmentation results in achieving the best of both worlds ( i.e. within 2% of native LLM accuracy with 50% less latency). To better understand LLM OOS detection capabilities, we perform controlled experiments revealing that this capability is significantly influenced by the scope of intent labels and the size of the label space. We also introduce a two-step approach utilizing internal LLM representations, demonstrating empirical gains in OOS detection accuracy and F1-score by >5% for the Mistral-7B model.
SICKLE: A Multi-Sensor Satellite Imagery Dataset Annotated with Multiple Key Cropping Parameters
Nov 29, 2023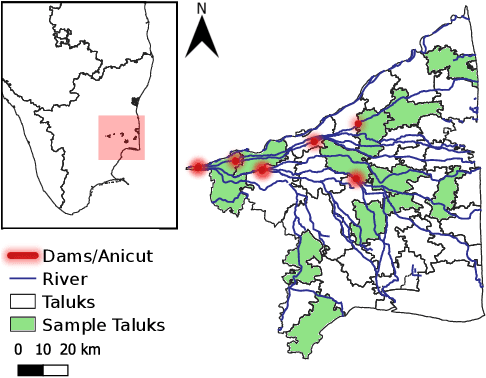
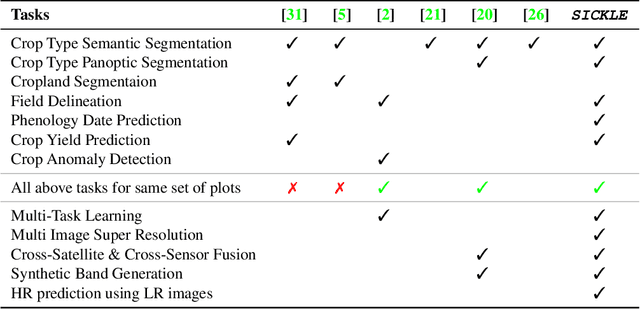
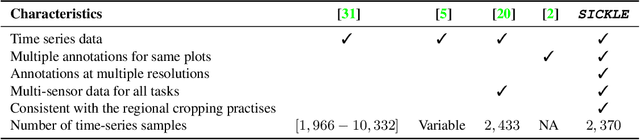
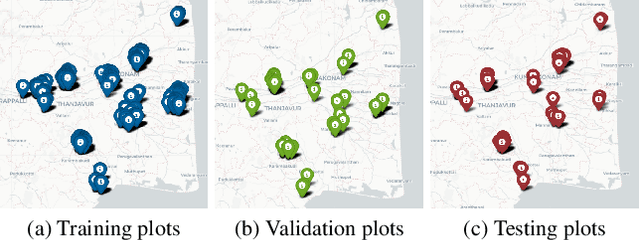
The availability of well-curated datasets has driven the success of Machine Learning (ML) models. Despite greater access to earth observation data in agriculture, there is a scarcity of curated and labelled datasets, which limits the potential of its use in training ML models for remote sensing (RS) in agriculture. To this end, we introduce a first-of-its-kind dataset called SICKLE, which constitutes a time-series of multi-resolution imagery from 3 distinct satellites: Landsat-8, Sentinel-1 and Sentinel-2. Our dataset constitutes multi-spectral, thermal and microwave sensors during January 2018 - March 2021 period. We construct each temporal sequence by considering the cropping practices followed by farmers primarily engaged in paddy cultivation in the Cauvery Delta region of Tamil Nadu, India; and annotate the corresponding imagery with key cropping parameters at multiple resolutions (i.e. 3m, 10m and 30m). Our dataset comprises 2,370 season-wise samples from 388 unique plots, having an average size of 0.38 acres, for classifying 21 crop types across 4 districts in the Delta, which amounts to approximately 209,000 satellite images. Out of the 2,370 samples, 351 paddy samples from 145 plots are annotated with multiple crop parameters; such as the variety of paddy, its growing season and productivity in terms of per-acre yields. Ours is also one among the first studies that consider the growing season activities pertinent to crop phenology (spans sowing, transplanting and harvesting dates) as parameters of interest. We benchmark SICKLE on three tasks: crop type, crop phenology (sowing, transplanting, harvesting), and yield prediction
High-Resolution Satellite Imagery for Modeling the Impact of Aridification on Crop Production
Sep 25, 2022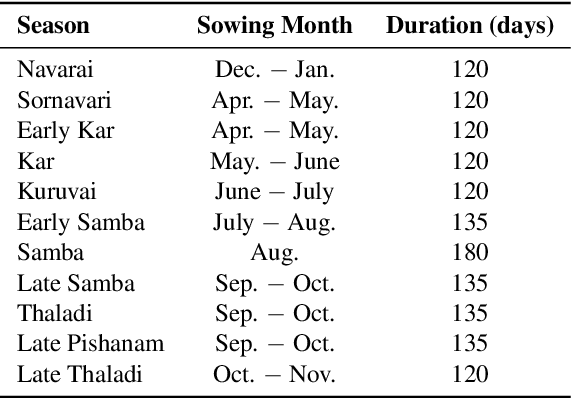
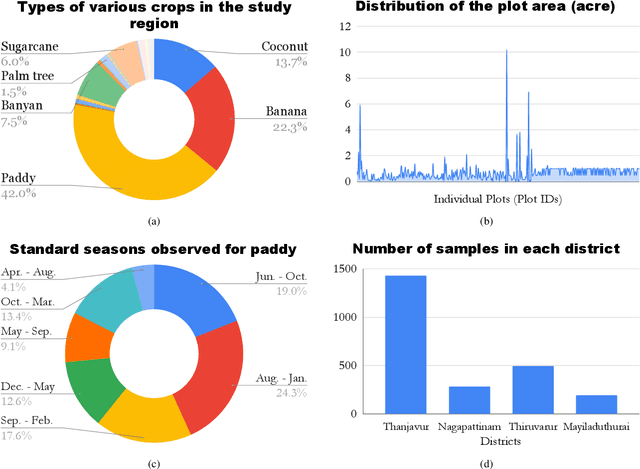

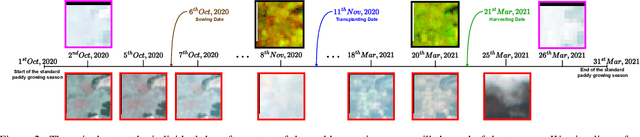
The availability of well-curated datasets has driven the success of Machine Learning (ML) models. Despite the increased access to earth observation data for agriculture, there is a scarcity of curated, labelled datasets, which limits the potential of its use in training ML models for remote sensing (RS) in agriculture. To this end, we introduce a first-of-its-kind dataset, SICKLE, having time-series images at different spatial resolutions from 3 different satellites, annotated with multiple key cropping parameters for paddy cultivation for the Cauvery Delta region in Tamil Nadu, India. The dataset comprises of 2,398 season-wise samples from 388 unique plots distributed across 4 districts of the Delta. The dataset covers multi-spectral, thermal and microwave data between the time period January 2018-March 2021. The paddy samples are annotated with 4 key cropping parameters, i.e. sowing date, transplanting date, harvesting date and crop yield. This is one of the first studies to consider the growing season (using sowing and harvesting dates) as part of a dataset. We also propose a yield prediction strategy that uses time-series data generated based on the observed growing season and the standard seasonal information obtained from Tamil Nadu Agricultural University for the region. The consequent performance improvement highlights the impact of ML techniques that leverage domain knowledge that are consistent with standard practices followed by farmers in a specific region. We benchmark the dataset on 3 separate tasks, namely crop type, phenology date (sowing, transplanting, harvesting) and yield prediction, and develop an end-to-end framework for predicting key crop parameters in a real-world setting.
Crop Type Identification for Smallholding Farms: Analyzing Spatial, Temporal and Spectral Resolutions in Satellite Imagery
May 06, 2022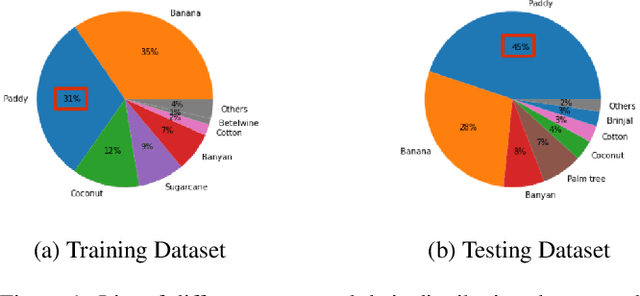
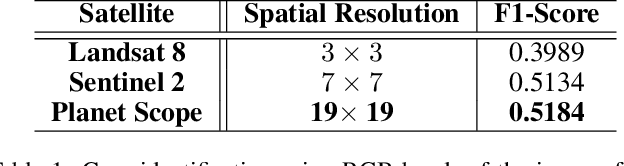
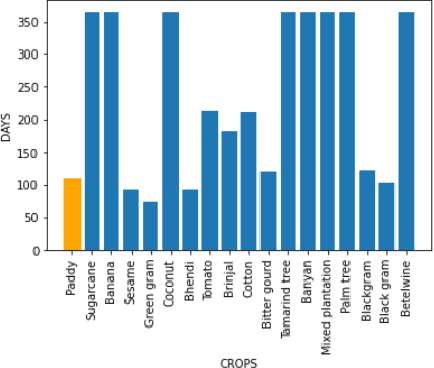
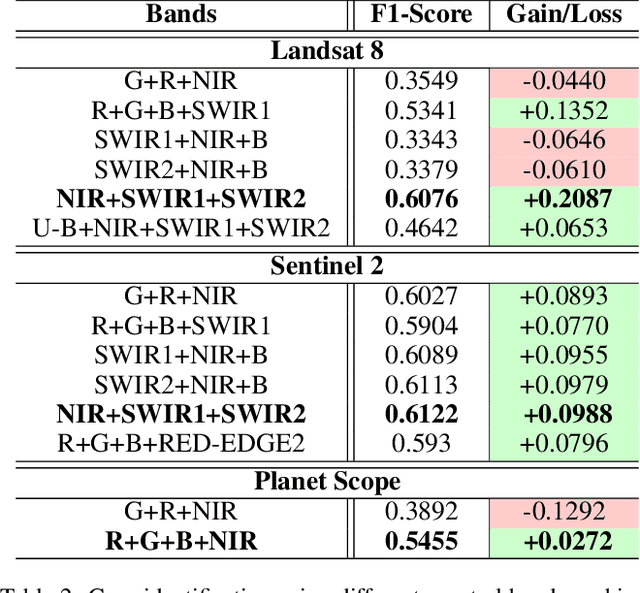
The integration of the modern Machine Learning (ML) models into remote sensing and agriculture has expanded the scope of the application of satellite images in the agriculture domain. In this paper, we present how the accuracy of crop type identification improves as we move from medium-spatiotemporal-resolution (MSTR) to high-spatiotemporal-resolution (HSTR) satellite images. We further demonstrate that high spectral resolution in satellite imagery can improve prediction performance for low spatial and temporal resolutions (LSTR) images. The F1-score is increased by 7% when using multispectral data of MSTR images as compared to the best results obtained from HSTR images. Similarly, when crop season based time series of multispectral data is used we observe an increase of 1.2% in the F1-score. The outcome motivates further advancements in the field of synthetic band generation.
Gauravarora@HASOC-Dravidian-CodeMix-FIRE2020: Pre-training ULMFiT on Synthetically Generated Code-Mixed Data for Hate Speech Detection
Oct 19, 2020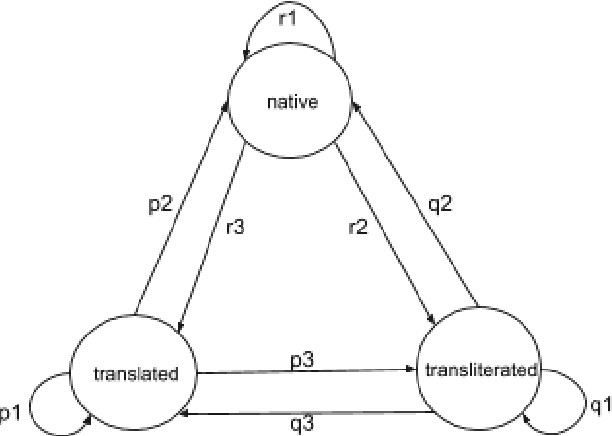
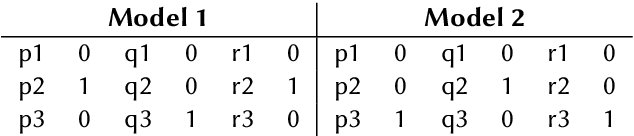
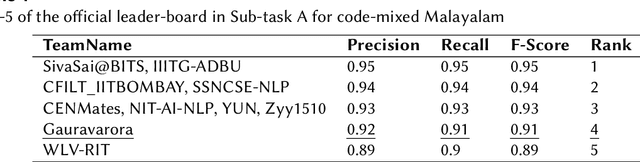
This paper describes the system submitted to Dravidian-Codemix-HASOC2020: Hate Speech and Offensive Content Identification in Dravidian languages (Tamil-English and Malayalam-English). The task aims to identify offensive language in code-mixed dataset of comments/posts in Dravidian languages collected from social media. We participated in both Sub-task A, which aims to identify offensive content in mixed-script (mixture of Native and Roman script) and Sub-task B, which aims to identify offensive content in Roman script, for Dravidian languages. In order to address these tasks, we proposed pre-training ULMFiT on synthetically generated code-mixed data, generated by modelling code-mixed data generation as a Markov process using Markov chains. Our model achieved 0.88 weighted F1-score for code-mixed Tamil-English language in Sub-task B and got 2nd rank on the leader-board. Additionally, our model achieved 0.91 weighted F1-score (4th Rank) for mixed-script Malayalam-English in Sub-task A and 0.74 weighted F1-score (5th Rank) for code-mixed Malayalam-English language in Sub-task B.
HINT3: Raising the bar for Intent Detection in the Wild
Oct 10, 2020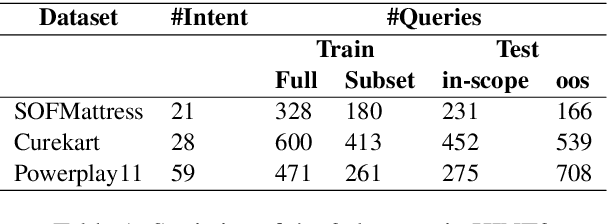
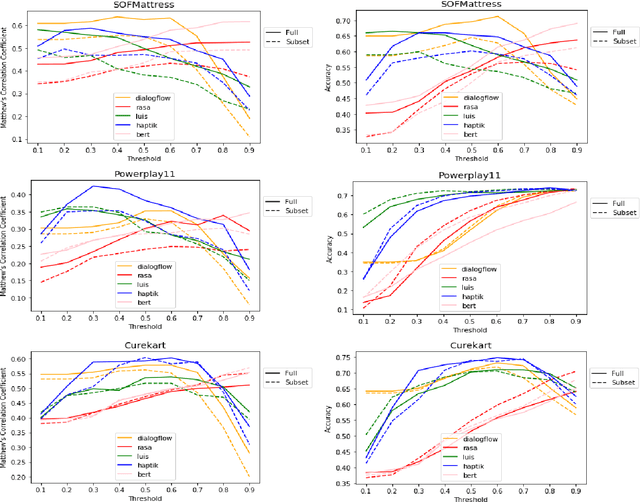
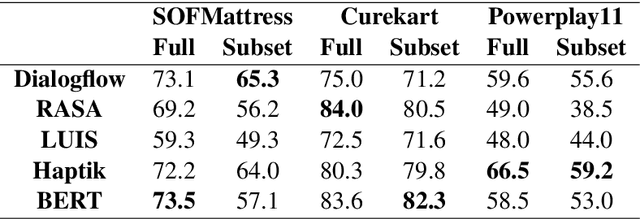
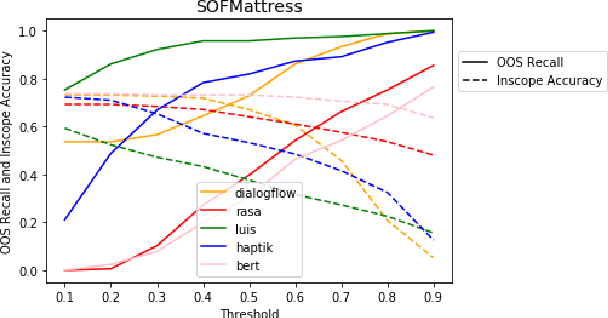
Intent Detection systems in the real world are exposed to complexities of imbalanced datasets containing varying perception of intent, unintended correlations and domain-specific aberrations. To facilitate benchmarking which can reflect near real-world scenarios, we introduce 3 new datasets created from live chatbots in diverse domains. Unlike most existing datasets that are crowdsourced, our datasets contain real user queries received by the chatbots and facilitates penalising unwanted correlations grasped during the training process. We evaluate 4 NLU platforms and a BERT based classifier and find that performance saturates at inadequate levels on test sets because all systems latch on to unintended patterns in training data.
iNLTK: Natural Language Toolkit for Indic Languages
Oct 10, 2020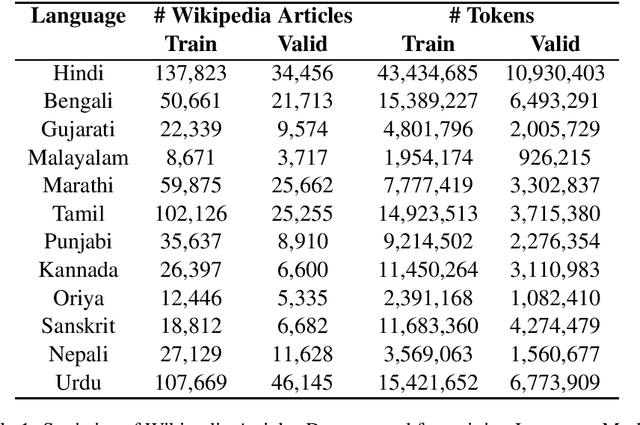

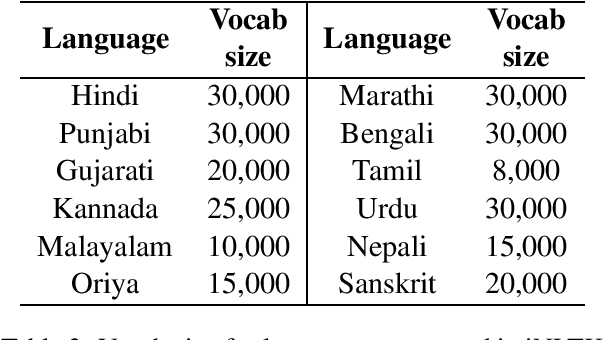
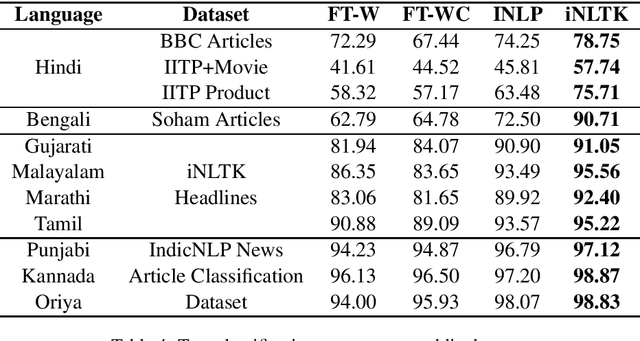
We present iNLTK, an open-source NLP library consisting of pre-trained language models and out-of-the-box support for Data Augmentation, Textual Similarity, Sentence Embeddings, Word Embeddings, Tokenization and Text Generation in 13 Indic Languages. By using pre-trained models from iNLTK for text classification on publicly available datasets, we significantly outperform previously reported results. On these datasets, we also show that by using pre-trained models and data augmentation from iNLTK, we can achieve more than 95% of the previous best performance by using less than 10% of the training data. iNLTK is already being widely used by the community and has 40,000+ downloads, 600+ stars and 100+ forks on GitHub. The library is available at https://github.com/goru001/inltk.
Attention based Sentence Extraction from Scientific Articles using Pseudo-Labeled data
Feb 13, 2018
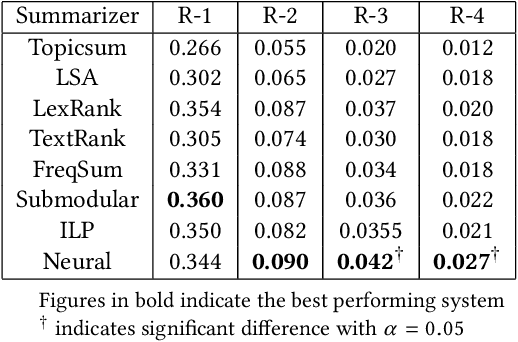
In this work, we present a weakly supervised sentence extraction technique for identifying important sentences in scientific papers that are worthy of inclusion in the abstract. We propose a new attention based deep learning architecture that jointly learns to identify important content, as well as the cue phrases that are indicative of summary worthy sentences. We propose a new context embedding technique for determining the focus of a given paper using topic models and use it jointly with an LSTM based sequence encoder to learn attention weights across the sentence words. We use a collection of articles publicly available through ACL anthology for our experiments. Our system achieves a performance that is better, in terms of several ROUGE metrics, as compared to several state of art extractive techniques. It also generates more coherent summaries and preserves the overall structure of the document.