 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Matters in Learning from Large-Scale Datasets for Robot Manipulation
Jun 16, 2025Imitation learning from large multi-task demonstration datasets has emerged as a promising path for building generally-capable robots. As a result, 1000s of hours have been spent on building such large-scale datasets around the globe. Despite the continuous growth of such efforts, we still lack a systematic understanding of what data should be collected to improve the utility of a robotics dataset and facilitate downstream policy learning. In this work, we conduct a large-scale dataset composition study to answer this question. We develop a data generation framework to procedurally emulate common sources of diversity in existing datasets (such as sensor placements and object types and arrangements), and use it to generate large-scale robot datasets with controlled compositions, enabling a suite of dataset composition studies that would be prohibitively expensive in the real world. We focus on two practical settings: (1) what types of diversity should be emphasized when future researchers collect large-scale datasets for robotics, and (2) how should current practitioners retrieve relevant demonstrations from existing datasets to maximize downstream policy performance on tasks of interest. Our study yields several critical insights -- for example, we find that camera poses and spatial arrangements are crucial dimensions for both diversity in collection and alignment in retrieval. In real-world robot learning settings, we find that not only do our insights from simulation carry over, but our retrieval strategies on existing datasets such as DROID allow us to consistently outperform existing training strategies by up to 70%. More results at https://robo-mimiclabs.github.io/
Towards Robust Knowledge Representations in Multilingual LLMs for Equivalence and Inheritance based Consistent Reasoning
Oct 18, 2024
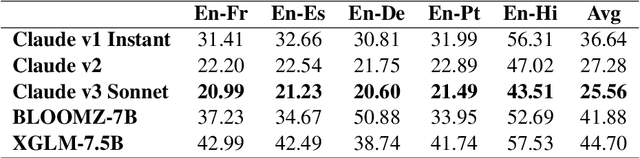


Reasoning and linguistic skills form the cornerstone of human intelligence, facilitating problem-solving and decision-making. Recent advances in Large Language Models (LLMs) have led to impressive linguistic capabilities and emergent reasoning behaviors, fueling widespread adoption across application domains. However, LLMs still struggle with complex reasoning tasks, highlighting their systemic limitations. In this work, we focus on evaluating whether LLMs have the requisite representations to reason using two foundational relationships: "equivalence" and "inheritance". We introduce novel tasks and benchmarks spanning six languages and observe that current SOTA LLMs often produce conflicting answers to the same questions across languages in 17.3-57.5% of cases and violate inheritance constraints in up to 37.2% cases. To enhance consistency across languages, we propose novel "Compositional Representations" where tokens are represented as composition of equivalent tokens across languages, with resulting conflict reduction (up to -4.7%) indicating benefits of shared LLM representations.
Scaling Granite Code Models to 128K Context
Jul 18, 2024This paper introduces long-context Granite code models that support effective context windows of up to 128K tokens. Our solution for scaling context length of Granite 3B/8B code models from 2K/4K to 128K consists of a light-weight continual pretraining by gradually increasing its RoPE base frequency with repository-level file packing and length-upsampled long-context data. Additionally, we also release instruction-tuned models with long-context support which are derived by further finetuning the long context base models on a mix of permissively licensed short and long-context instruction-response pairs. While comparing to the original short-context Granite code models, our long-context models achieve significant improvements on long-context tasks without any noticeable performance degradation on regular code completion benchmarks (e.g., HumanEval). We release all our long-context Granite code models under an Apache 2.0 license for both research and commercial use.
Constrained-Context Conditional Diffusion Models for Imitation Learning
Nov 02, 2023Offline Imitation Learning (IL) is a powerful paradigm to learn visuomotor skills, especially for high-precision manipulation tasks. However, IL methods are prone to spurious correlation - expressive models may focus on distractors that are irrelevant to action prediction - and are thus fragile in real-world deployment. Prior methods have addressed this challenge by exploring different model architectures and action representations. However, none were able to balance between sample efficiency, robustness against distractors, and solving high-precision manipulation tasks with complex action space. To this end, we present $\textbf{C}$onstrained-$\textbf{C}$ontext $\textbf{C}$onditional $\textbf{D}$iffusion $\textbf{M}$odel (C3DM), a diffusion model policy for solving 6-DoF robotic manipulation tasks with high precision and ability to ignore distractions. A key component of C3DM is a fixation step that helps the action denoiser to focus on task-relevant regions around the predicted action while ignoring distractors in the context. We empirically show that C3DM is able to consistently achieve high success rate on a wide array of tasks, ranging from table top manipulation to industrial kitting, that require varying levels of precision and robustness to distractors. For details, please visit this https://sites.google.com/view/c3dm-imitation-learning
Generalizable Pose Estimation Using Implicit Scene Representations
May 26, 2023



6-DoF pose estimation is an essential component of robotic manipulation pipelines. However, it usually suffers from a lack of generalization to new instances and object types. Most widely used methods learn to infer the object pose in a discriminative setup where the model filters useful information to infer the exact pose of the object. While such methods offer accurate poses, the model does not store enough information to generalize to new objects. In this work, we address the generalization capability of pose estimation using models that contain enough information about the object to render it in different poses. We follow the line of work that inverts neural renderers to infer the pose. We propose i-$\sigma$SRN to maximize the information flowing from the input pose to the rendered scene and invert them to infer the pose given an input image. Specifically, we extend Scene Representation Networks (SRNs) by incorporating a separate network for density estimation and introduce a new way of obtaining a weighted scene representation. We investigate several ways of initial pose estimates and losses for the neural renderer. Our final evaluation shows a significant improvement in inference performance and speed compared to existing approaches.
Clockwork Variational Autoencoders
Feb 20, 2021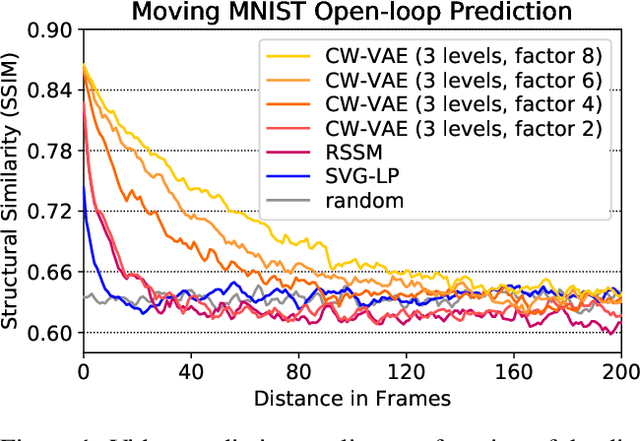
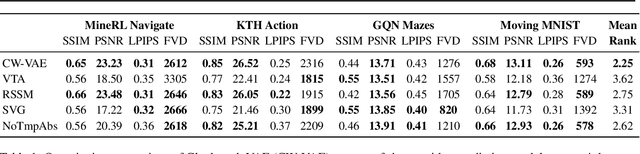
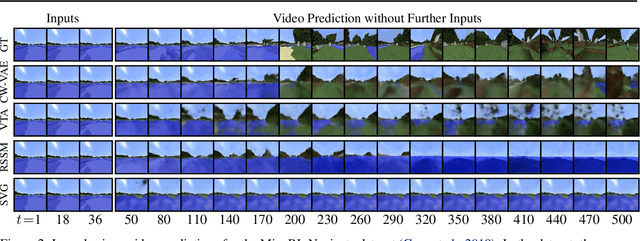
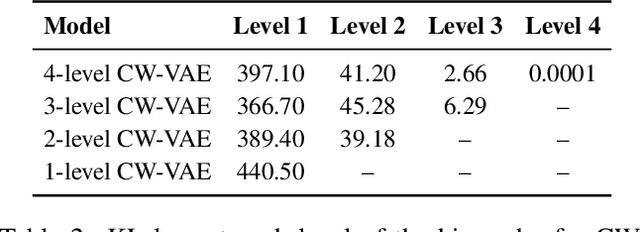
Deep learning has enabled algorithms to generate realistic images. However, accurately predicting long video sequences requires understanding long-term dependencies and remains an open challenge. While existing video prediction models succeed at generating sharp images, they tend to fail at accurately predicting far into the future. We introduce the Clockwork VAE (CW-VAE), a video prediction model that leverages a hierarchy of latent sequences, where higher levels tick at slower intervals. We demonstrate the benefits of both hierarchical latents and temporal abstraction on 4 diverse video prediction datasets with sequences of up to 1000 frames, where CW-VAE outperforms top video prediction models. Additionally, we propose a Minecraft benchmark for long-term video prediction. We conduct several experiments to gain insights into CW-VAE and confirm that slower levels learn to represent objects that change more slowly in the video, and faster levels learn to represent faster objects.
Effective Elastic Scaling of Deep Learning Workloads
Jun 24, 2020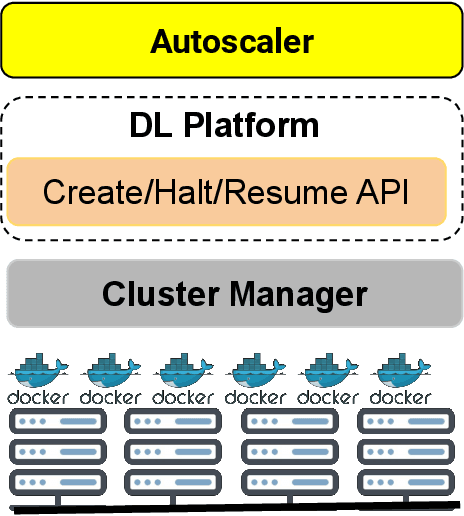
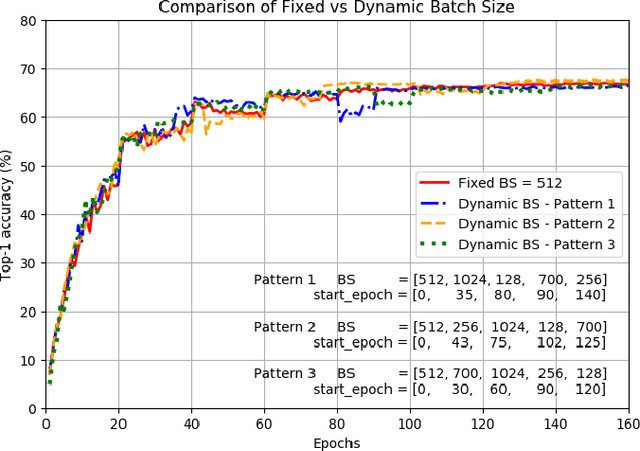
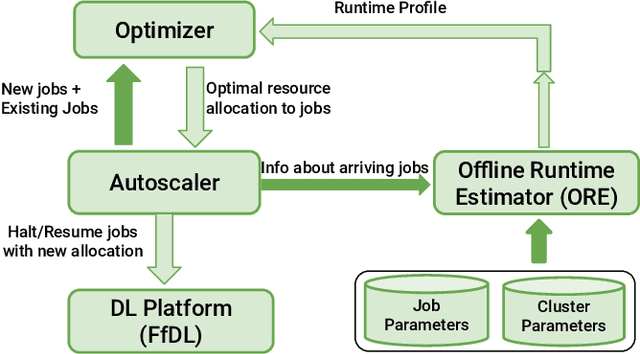

The increased use of deep learning (DL) in academia, government and industry has, in turn, led to the popularity of on-premise and cloud-hosted deep learning platforms, whose goals are to enable organizations utilize expensive resources effectively, and to share said resources among multiple teams in a fair and effective manner. In this paper, we examine the elastic scaling of Deep Learning (DL) jobs over large-scale training platforms and propose a novel resource allocation strategy for DL training jobs, resulting in improved job run time performance as well as increased cluster utilization. We begin by analyzing DL workloads and exploit the fact that DL jobs can be run with a range of batch sizes without affecting their final accuracy. We formulate an optimization problem that explores a dynamic batch size allocation to individual DL jobs based on their scaling efficiency, when running on multiple nodes. We design a fast dynamic programming based optimizer to solve this problem in real-time to determine jobs that can be scaled up/down, and use this optimizer in an autoscaler to dynamically change the allocated resources and batch sizes of individual DL jobs. We demonstrate empirically that our elastic scaling algorithm can complete up to $\approx 2 \times$ as many jobs as compared to a strong baseline algorithm that also scales the number of GPUs but does not change the batch size. We also demonstrate that the average completion time with our algorithm is up to $\approx 10 \times$ faster than that of the baseline.
Dyna-AIL : Adversarial Imitation Learning by Planning
Mar 08, 2019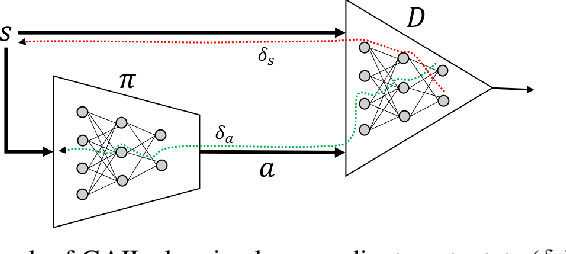
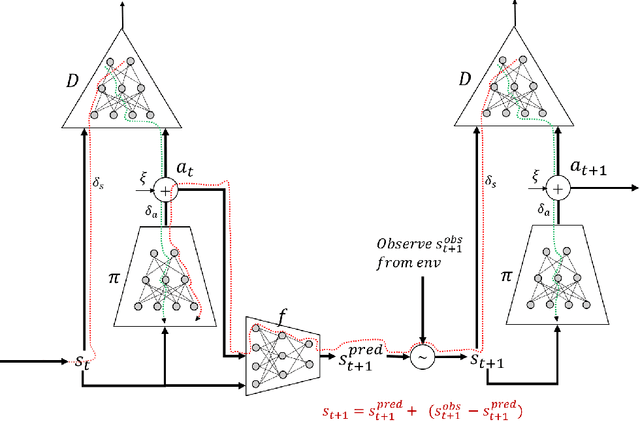
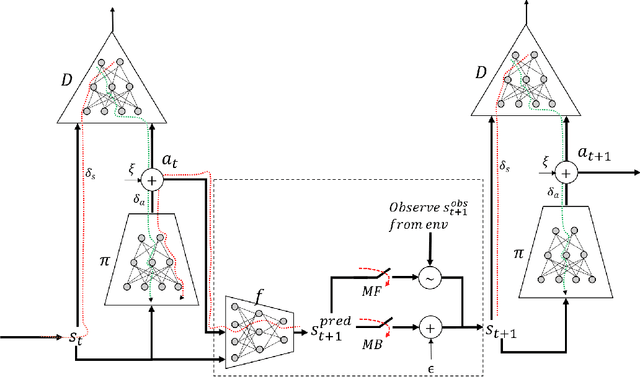
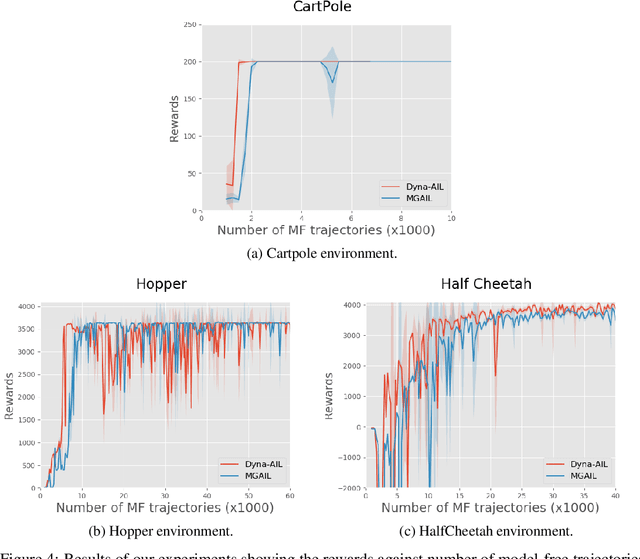
Adversarial methods for imitation learning have been shown to perform well on various control tasks. However, they require a large number of environment interactions for convergence. In this paper, we propose an end-to-end differentiable adversarial imitation learning algorithm in a Dyna-like framework for switching between model-based planning and model-free learning from expert data. Our results on both discrete and continuous environments show that our approach of using model-based planning along with model-free learning converges to an optimal policy with fewer number of environment interactions in comparison to the state-of-the-art learning methods.
PowerAI DDL
Aug 07, 2017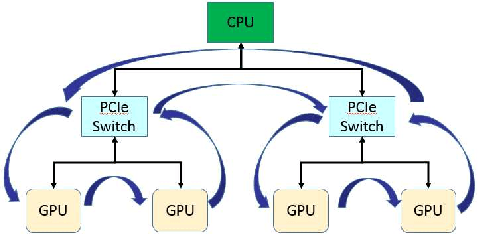
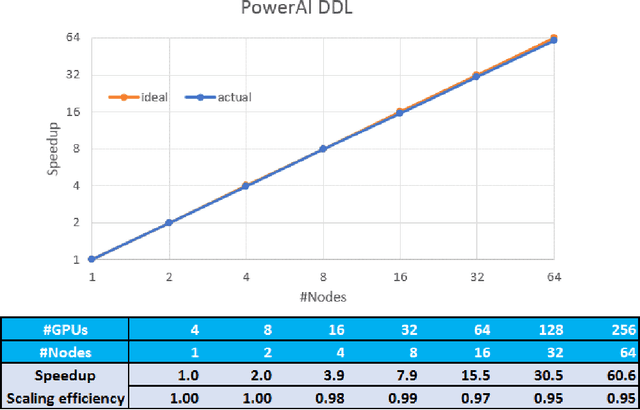
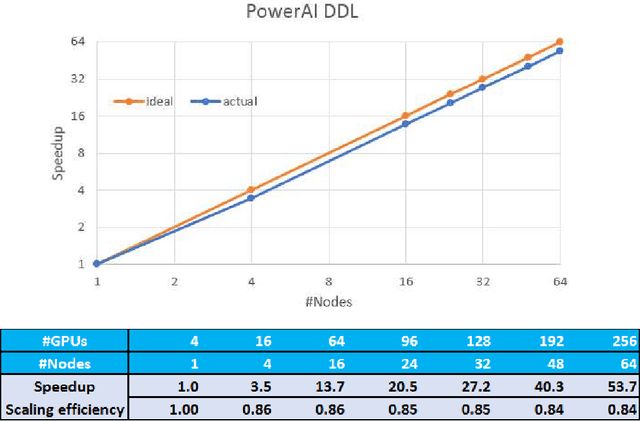
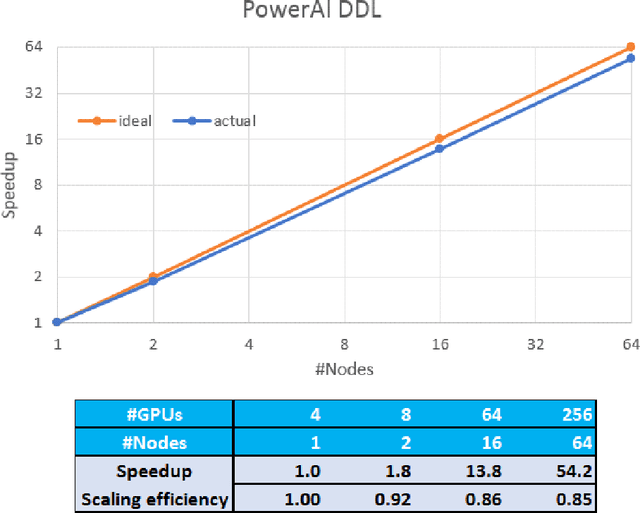
As deep neural networks become more complex and input datasets grow larger, it can take days or even weeks to train a deep neural network to the desired accuracy. Therefore, distributed Deep Learning at a massive scale is a critical capability, since it offers the potential to reduce the training time from weeks to hours. In this paper, we present a software-hardware co-optimized distributed Deep Learning system that can achieve near-linear scaling up to hundreds of GPUs. The core algorithm is a multi-ring communication pattern that provides a good tradeoff between latency and bandwidth and adapts to a variety of system configurations. The communication algorithm is implemented as a library for easy use. This library has been integrated into Tensorflow, Caffe, and Torch. We train Resnet-101 on Imagenet 22K with 64 IBM Power8 S822LC servers (256 GPUs) in about 7 hours to an accuracy of 33.8 % validation accuracy. Microsoft's ADAM and Google's DistBelief results did not reach 30 % validation accuracy for Imagenet 22K. Compared to Facebook AI Research's recent paper on 256 GPU training, we use a different communication algorithm, and our combined software and hardware system offers better communication overhead for Resnet-50. A PowerAI DDL enabled version of Torch completed 90 epochs of training on Resnet 50 for 1K classes in 50 minutes using 64 IBM Power8 S822LC servers (256 GPUs).