 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDesigning Effective Sparse Expert Models
Feb 17, 2022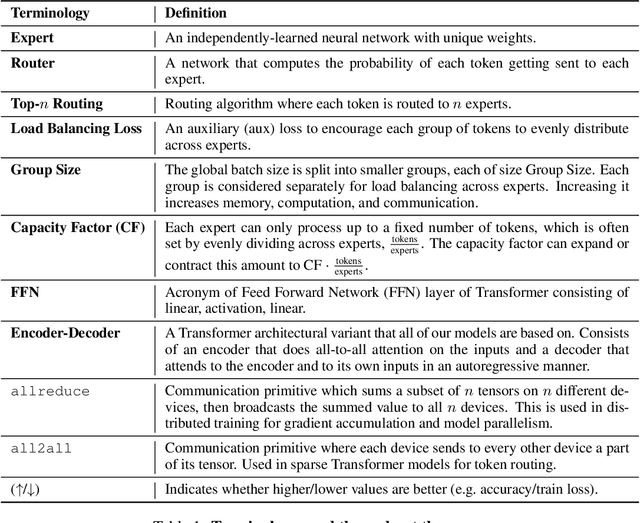
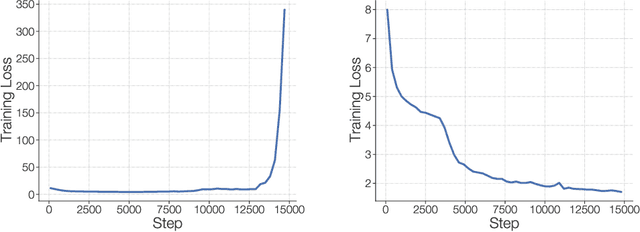

Scale has opened new frontiers in natural language processing -- but at a high cost. In response, Mixture-of-Experts (MoE) and Switch Transformers have been proposed as an energy efficient path to even larger and more capable language models. But advancing the state-of-the-art across a broad set of natural language tasks has been hindered by training instabilities and uncertain quality during fine-tuning. Our work focuses on these issues and acts as a design guide. We conclude by scaling a sparse model to 269B parameters, with a computational cost comparable to a 32B dense encoder-decoder Transformer (Stable and Transferable Mixture-of-Experts or ST-MoE-32B). For the first time, a sparse model achieves state-of-the-art performance in transfer learning, across a diverse set of tasks including reasoning (SuperGLUE, ARC Easy, ARC Challenge), summarization (XSum, CNN-DM), closed book question answering (WebQA, Natural Questions), and adversarially constructed tasks (Winogrande, ANLI R3).
Exploring the limits of Concurrency in ML Training on Google TPUs
Nov 07, 2020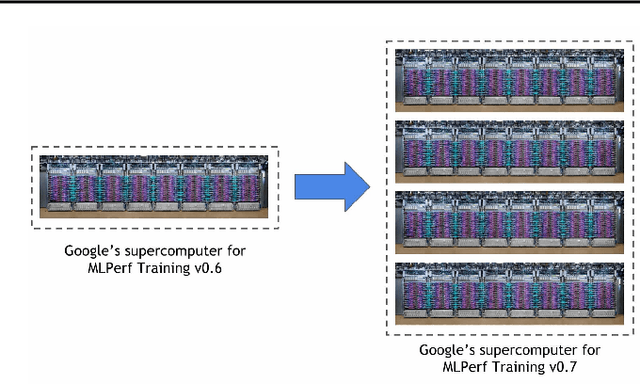
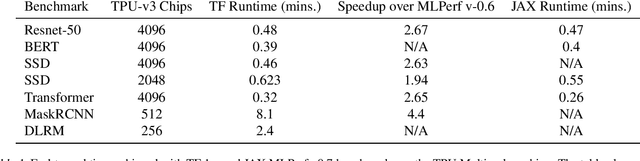
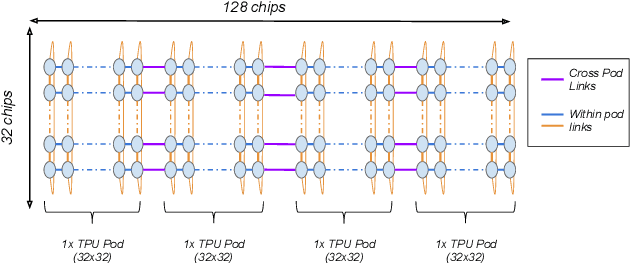
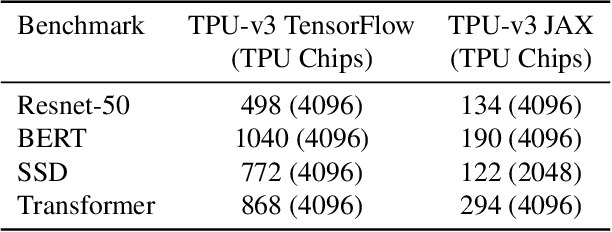
Recent results in language understanding using neural networks have required training hardware of unprecedentedscale, with thousands of chips cooperating on a single training run. This paper presents techniques to scaleML models on the Google TPU Multipod, a mesh with 4096 TPU-v3 chips. We discuss model parallelism toovercome scaling limitations from the fixed batch size in data parallelism, communication/collective optimizations,distributed evaluation of training metrics, and host input processing scaling optimizations. These techniques aredemonstrated in both the TensorFlow and JAX programming frameworks. We also present performance resultsfrom the recent Google submission to the MLPerf-v0.7 benchmark contest, achieving record training times from16 to 28 seconds in four MLPerf models on the Google TPU-v3 Multipod machine.
Highly Available Data Parallel ML training on Mesh Networks
Nov 06, 2020

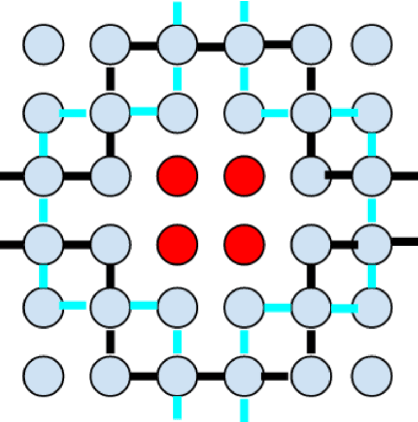
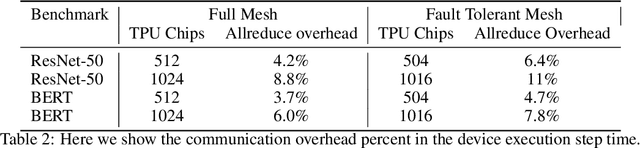
Data parallel ML models can take several days or weeks to train on several accelerators. The long duration of training relies on the cluster of resources to be available for the job to keep running for the entire duration. On a mesh network this is challenging because failures will create holes in the mesh. Packets must be routed around the failed chips for full connectivity. In this paper, we present techniques to route gradient summation allreduce traffic around failed chips on 2-D meshes. We evaluate performance of our fault tolerant allreduce techniques via the MLPerf-v0.7 ResNet-50 and BERT benchmarks. Performance results show minimal impact to training throughput on 512 and 1024 TPU-v3 chips.
Training EfficientNets at Supercomputer Scale: 83% ImageNet Top-1 Accuracy in One Hour
Nov 05, 2020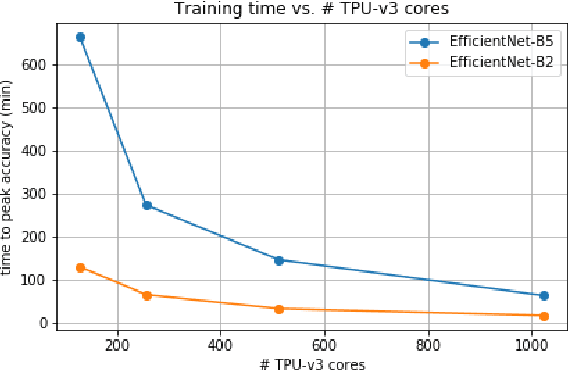
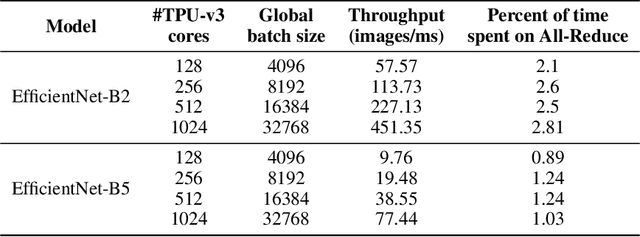
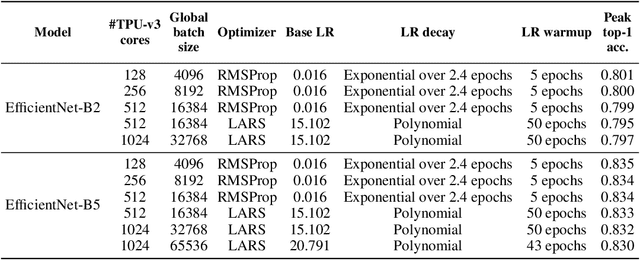
EfficientNets are a family of state-of-the-art image classification models based on efficiently scaled convolutional neural networks. Currently, EfficientNets can take on the order of days to train; for example, training an EfficientNet-B0 model takes 23 hours on a Cloud TPU v2-8 node. In this paper, we explore techniques to scale up the training of EfficientNets on TPU-v3 Pods with 2048 cores, motivated by speedups that can be achieved when training at such scales. We discuss optimizations required to scale training to a batch size of 65536 on 1024 TPU-v3 cores, such as selecting large batch optimizers and learning rate schedules as well as utilizing distributed evaluation and batch normalization techniques. Additionally, we present timing and performance benchmarks for EfficientNet models trained on the ImageNet dataset in order to analyze the behavior of EfficientNets at scale. With our optimizations, we are able to train EfficientNet on ImageNet to an accuracy of 83% in 1 hour and 4 minutes.
Scale MLPerf-0.6 models on Google TPU-v3 Pods
Oct 02, 2019
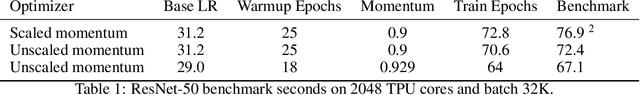

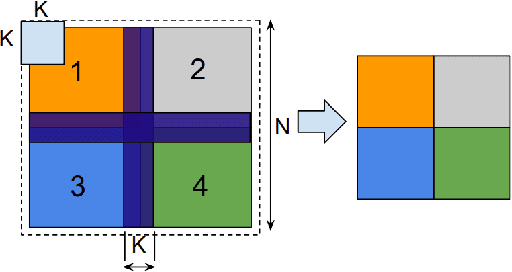
The recent submission of Google TPU-v3 Pods to the industry wide MLPerf v0.6 training benchmark demonstrates the scalability of a suite of industry relevant ML models. MLPerf defines a suite of models, datasets and rules to follow when benchmarking to ensure results are comparable across hardware, frameworks and companies. Using this suite of models, we discuss the optimizations and techniques including choice of optimizer, spatial partitioning and weight update sharding necessary to scale to 1024 TPU chips. Furthermore, we identify properties of models that make scaling them challenging, such as limited data parallelism and unscaled weights. These optimizations contribute to record performance in transformer, Resnet-50 and SSD in the Google MLPerf-0.6 submission.
Image Classification at Supercomputer Scale
Dec 02, 2018
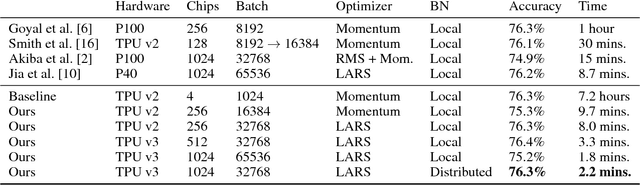

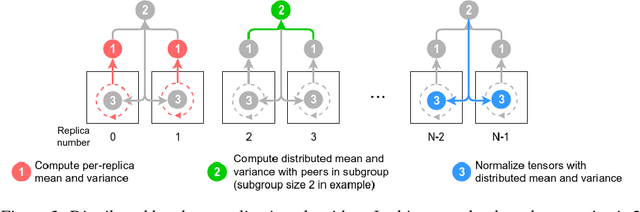
Deep learning is extremely computationally intensive, and hardware vendors have responded by building faster accelerators in large clusters. Training deep learning models at petaFLOPS scale requires overcoming both algorithmic and systems software challenges. In this paper, we discuss three systems-related optimizations: (1) distributed batch normalization to control per-replica batch sizes, (2) input pipeline optimizations to sustain model throughput, and (3) 2-D torus all-reduce to speed up gradient summation. We combine these optimizations to train ResNet-50 on ImageNet to 76.3% accuracy in 2.2 minutes on a 1024-chip TPU v3 Pod with a training throughput of over 1.05 million images/second and no accuracy drop.
PowerAI DDL
Aug 07, 2017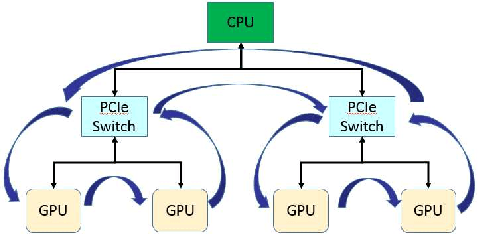
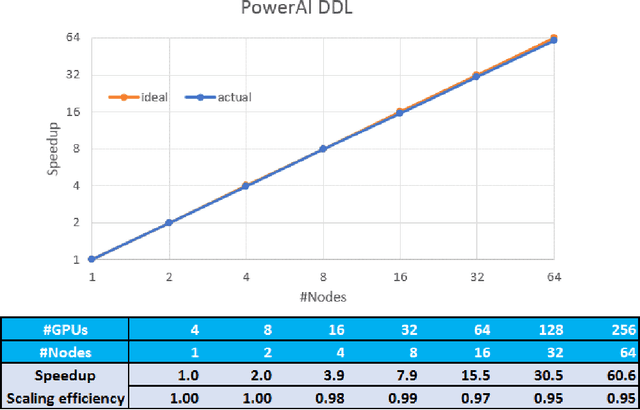
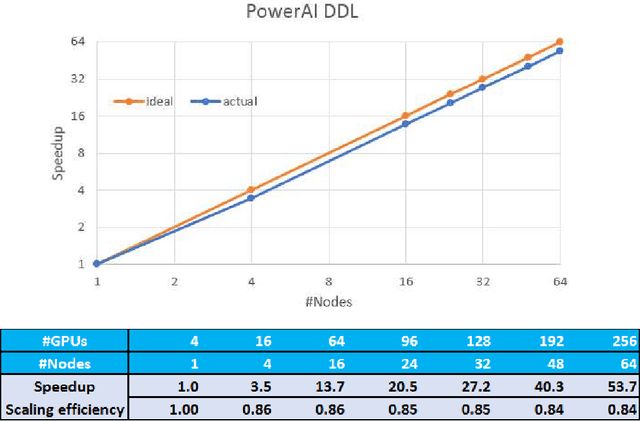
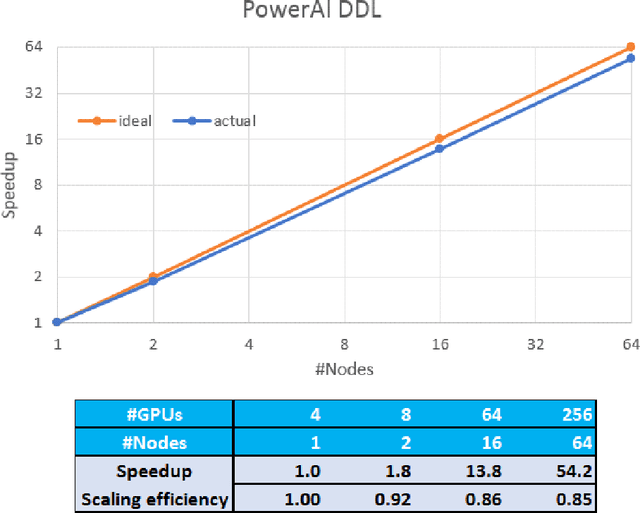
As deep neural networks become more complex and input datasets grow larger, it can take days or even weeks to train a deep neural network to the desired accuracy. Therefore, distributed Deep Learning at a massive scale is a critical capability, since it offers the potential to reduce the training time from weeks to hours. In this paper, we present a software-hardware co-optimized distributed Deep Learning system that can achieve near-linear scaling up to hundreds of GPUs. The core algorithm is a multi-ring communication pattern that provides a good tradeoff between latency and bandwidth and adapts to a variety of system configurations. The communication algorithm is implemented as a library for easy use. This library has been integrated into Tensorflow, Caffe, and Torch. We train Resnet-101 on Imagenet 22K with 64 IBM Power8 S822LC servers (256 GPUs) in about 7 hours to an accuracy of 33.8 % validation accuracy. Microsoft's ADAM and Google's DistBelief results did not reach 30 % validation accuracy for Imagenet 22K. Compared to Facebook AI Research's recent paper on 256 GPU training, we use a different communication algorithm, and our combined software and hardware system offers better communication overhead for Resnet-50. A PowerAI DDL enabled version of Torch completed 90 epochs of training on Resnet 50 for 1K classes in 50 minutes using 64 IBM Power8 S822LC servers (256 GPUs).