 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine Learning Fleet Efficiency: Analyzing and Optimizing Large-Scale Google TPU Systems with ML Productivity Goodput
Feb 10, 2025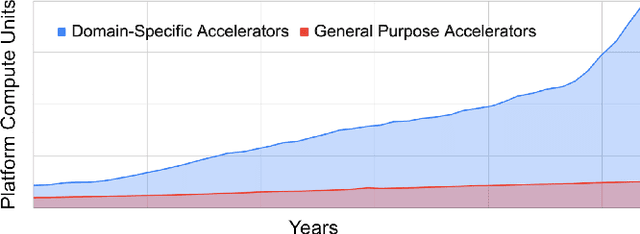

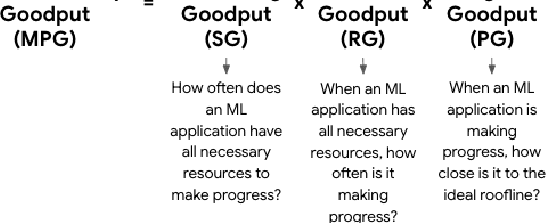

Recent years have seen the emergence of machine learning (ML) workloads deployed in warehouse-scale computing (WSC) settings, also known as ML fleets. As the computational demands placed on ML fleets have increased due to the rise of large models and growing demand for ML applications, it has become increasingly critical to measure and improve the efficiency of such systems. However, there is not yet an established methodology to characterize ML fleet performance and identify potential performance optimizations accordingly. This paper presents a large-scale analysis of an ML fleet based on Google's TPUs, introducing a framework to capture fleet-wide efficiency, systematically evaluate performance characteristics, and identify optimization strategies for the fleet. We begin by defining an ML fleet, outlining its components, and analyzing an example Google ML fleet in production comprising thousands of accelerators running diverse workloads. Our study reveals several critical insights: first, ML fleets extend beyond the hardware layer, with model, data, framework, compiler, and scheduling layers significantly impacting performance; second, the heterogeneous nature of ML fleets poses challenges in characterizing individual workload performance; and third, traditional utilization-based metrics prove insufficient for ML fleet characterization. To address these challenges, we present the "ML Productivity Goodput" (MPG) metric to measure ML fleet efficiency. We show how to leverage this metric to characterize the fleet across the ML system stack. We also present methods to identify and optimize performance bottlenecks using MPG, providing strategies for managing warehouse-scale ML systems in general. Lastly, we demonstrate quantitative evaluations from applying these methods to a real ML fleet for internal-facing Google TPU workloads, where we observed tangible improvements.
Hadamard Domain Training with Integers for Class Incremental Quantized Learning
Oct 05, 2023



Continual learning is a desirable feature in many modern machine learning applications, which allows in-field adaptation and updating, ranging from accommodating distribution shift, to fine-tuning, and to learning new tasks. For applications with privacy and low latency requirements, the compute and memory demands imposed by continual learning can be cost-prohibitive for resource-constraint edge platforms. Reducing computational precision through fully quantized training (FQT) simultaneously reduces memory footprint and increases compute efficiency for both training and inference. However, aggressive quantization especially integer FQT typically degrades model accuracy to unacceptable levels. In this paper, we propose a technique that leverages inexpensive Hadamard transforms to enable low-precision training with only integer matrix multiplications. We further determine which tensors need stochastic rounding and propose tiled matrix multiplication to enable low-bit width accumulators. We demonstrate the effectiveness of our technique on several human activity recognition datasets and CIFAR100 in a class incremental learning setting. We achieve less than 0.5% and 3% accuracy degradation while we quantize all matrix multiplications inputs down to 4-bits with 8-bit accumulators.
Augmenting Hessians with Inter-Layer Dependencies for Mixed-Precision Post-Training Quantization
Jun 08, 2023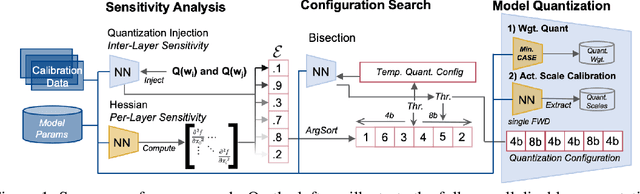
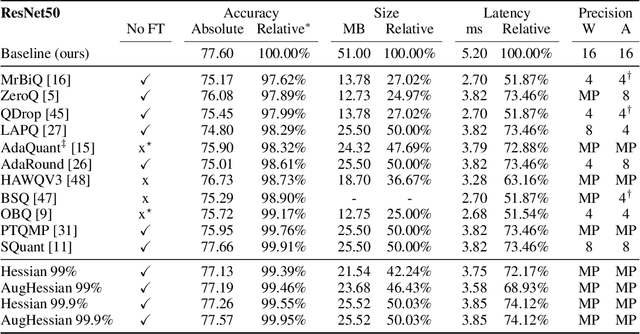
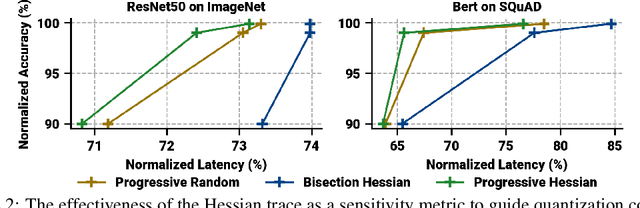
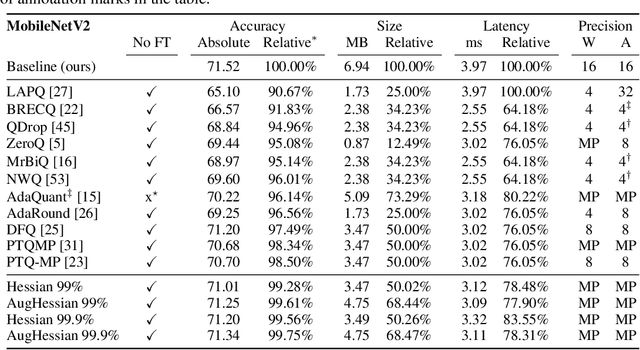
Efficiently serving neural network models with low latency is becoming more challenging due to increasing model complexity and parameter count. Model quantization offers a solution which simultaneously reduces memory footprint and compute requirements. However, aggressive quantization may lead to an unacceptable loss in model accuracy owing to differences in sensitivity to numerical imperfection across different layers in the model. To address this challenge, we propose a mixed-precision post training quantization (PTQ) approach that assigns different numerical precisions to tensors in a network based on their specific needs, for a reduced memory footprint and improved latency while preserving model accuracy. Previous works rely on layer-wise Hessian information to determine numerical precision, but as we demonstrate, Hessian estimation is typically insufficient in determining an effective ordering of layer sensitivities. We address this by augmenting the estimated Hessian with additional information to capture inter-layer dependencies. We demonstrate that this consistently improves PTQ performance along the accuracy-latency Pareto frontier across multiple models. Our method combines second-order information and inter-layer dependencies to guide a bisection search, finding quantization configurations within a user-configurable model accuracy degradation range. We evaluate the effectiveness of our method on the ResNet50, MobileNetV2, and BERT models. Our experiments demonstrate latency reductions compared to a 16-bit baseline of $25.48\%$, $21.69\%$, and $33.28\%$ respectively, while maintaining model accuracy to within $99.99\%$ of the baseline model.
Mixed Precision Post Training Quantization of Neural Networks with Sensitivity Guided Search
Feb 07, 2023



Serving large-scale machine learning (ML) models efficiently and with low latency has become challenging owing to increasing model size and complexity. Quantizing models can simultaneously reduce memory and compute requirements, facilitating their widespread access. However, for large models not all layers are equally amenable to the same numerical precision and aggressive quantization can lead to unacceptable loss in model accuracy. One approach to prevent this accuracy degradation is mixed-precision quantization, which allows different tensors to be quantized to varying levels of numerical precision, leveraging the capabilities of modern hardware. Such mixed-precision quantiztaion can more effectively allocate numerical precision to different tensors `as needed' to preserve model accuracy while reducing footprint and compute latency. In this paper, we propose a method to efficiently determine quantization configurations of different tensors in ML models using post-training mixed precision quantization. We analyze three sensitivity metrics and evaluate them for guiding configuration search of two algorithms. We evaluate our method for computer vision and natural language processing and demonstrate latency reductions of up to 27.59% and 34.31% compared to the baseline 16-bit floating point model while guaranteeing no more than 1% accuracy degradation.
AutoDistill: an End-to-End Framework to Explore and Distill Hardware-Efficient Language Models
Jan 21, 2022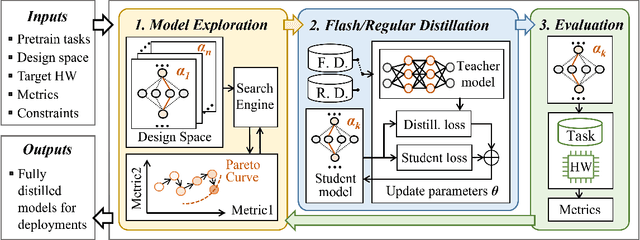
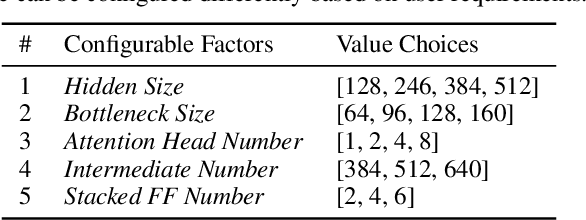
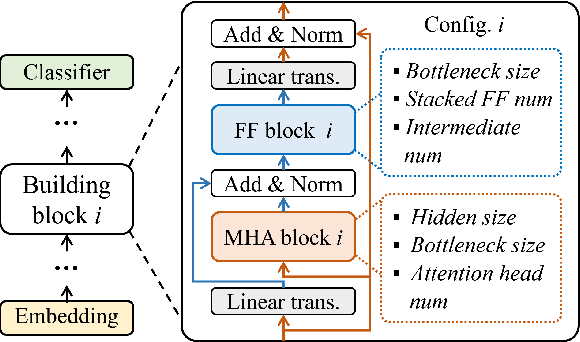
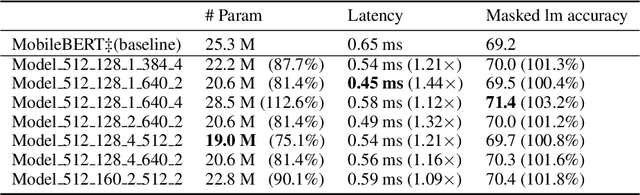
Recently, large pre-trained models have significantly improved the performance of various Natural LanguageProcessing (NLP) tasks but they are expensive to serve due to long serving latency and large memory usage. To compress these models, knowledge distillation has attracted an increasing amount of interest as one of the most effective methods for model compression. However, existing distillation methods have not yet addressed the unique challenges of model serving in datacenters, such as handling fast evolving models, considering serving performance, and optimizing for multiple objectives. To solve these problems, we propose AutoDistill, an end-to-end model distillation framework integrating model architecture exploration and multi-objective optimization for building hardware-efficient NLP pre-trained models. We use Bayesian Optimization to conduct multi-objective Neural Architecture Search for selecting student model architectures. The proposed search comprehensively considers both prediction accuracy and serving latency on target hardware. The experiments on TPUv4i show the finding of seven model architectures with better pre-trained accuracy (up to 3.2% higher) and lower inference latency (up to 1.44x faster) than MobileBERT. By running downstream NLP tasks in the GLUE benchmark, the model distilled for pre-training by AutoDistill with 28.5M parameters achieves an 81.69 average score, which is higher than BERT_BASE, DistillBERT, TinyBERT, NAS-BERT, and MobileBERT. The most compact model found by AutoDistill contains only 20.6M parameters but still outperform BERT_BASE(109M), DistillBERT(67M), TinyBERT(67M), and MobileBERT(25.3M) regarding the average GLUE score. By evaluating on SQuAD, a model found by AutoDistill achieves an 88.4% F1 score with 22.8M parameters, which reduces parameters by more than 62% while maintaining higher accuracy than DistillBERT, TinyBERT, and NAS-BERT.
GLaM: Efficient Scaling of Language Models with Mixture-of-Experts
Dec 13, 2021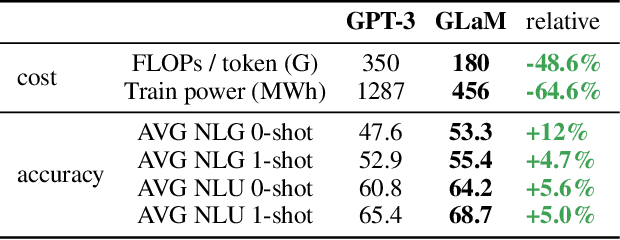
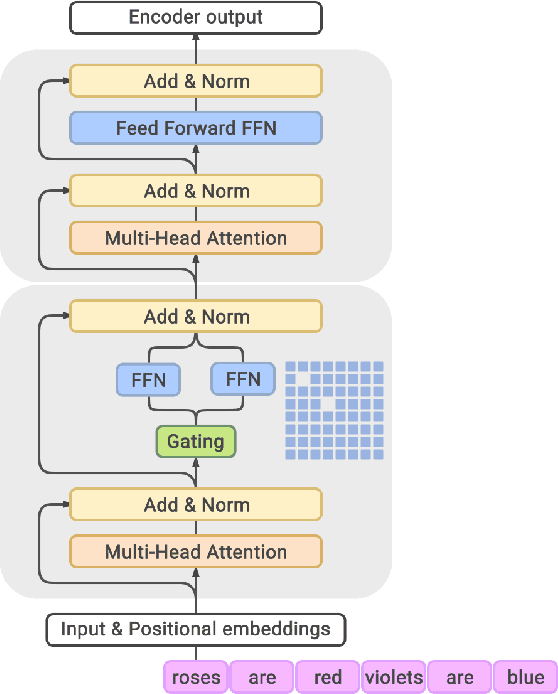
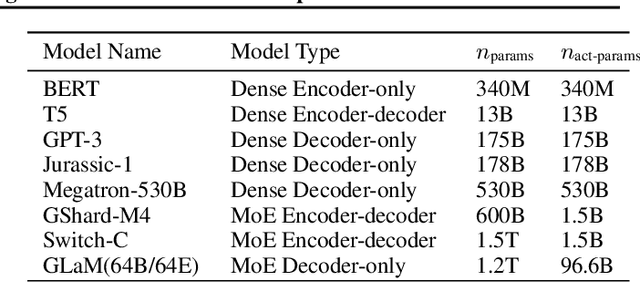
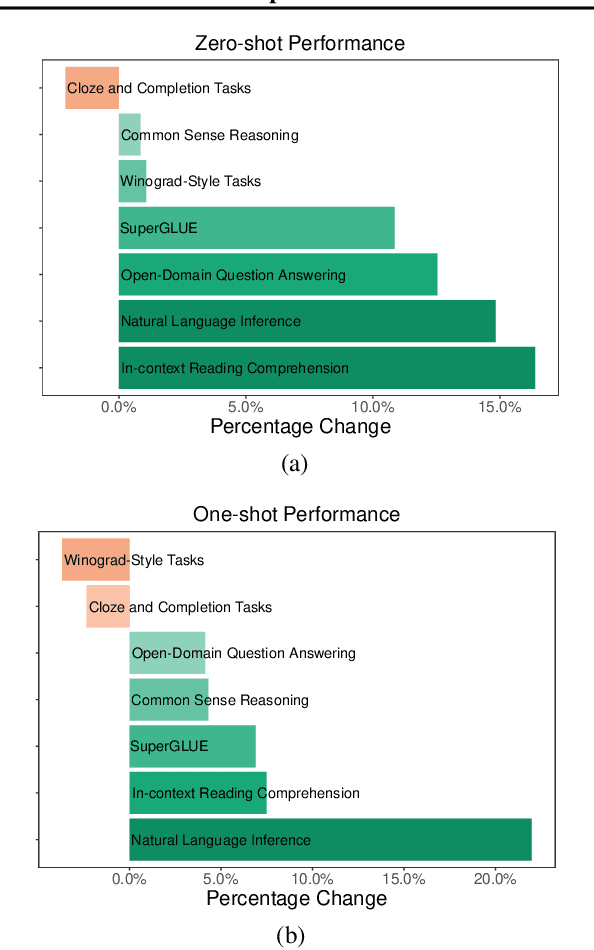
Scaling language models with more data, compute and parameters has driven significant progress in natural language processing. For example, thanks to scaling, GPT-3 was able to achieve strong results on in-context learning tasks. However, training these large dense models requires significant amounts of computing resources. In this paper, we propose and develop a family of language models named GLaM (Generalist Language Model), which uses a sparsely activated mixture-of-experts architecture to scale the model capacity while also incurring substantially less training cost compared to dense variants. The largest GLaM has 1.2 trillion parameters, which is approximately 7x larger than GPT-3. It consumes only 1/3 of the energy used to train GPT-3 and requires half of the computation flops for inference, while still achieving better overall zero-shot and one-shot performance across 29 NLP tasks.
Exploring the limits of Concurrency in ML Training on Google TPUs
Nov 07, 2020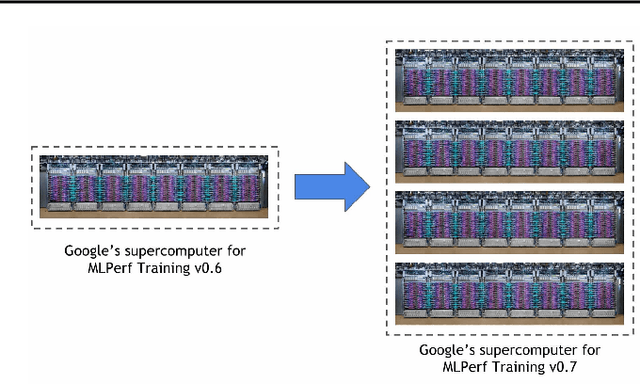
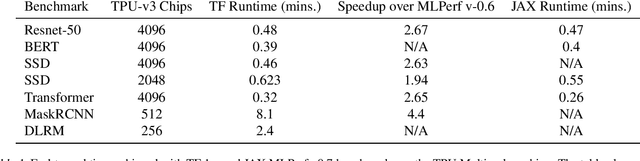
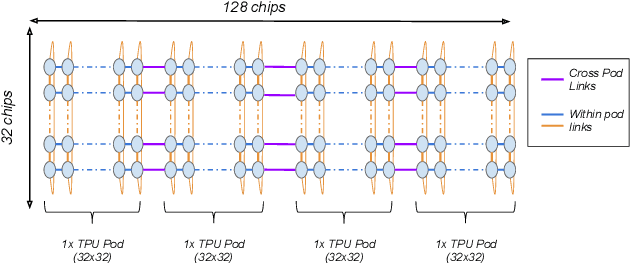
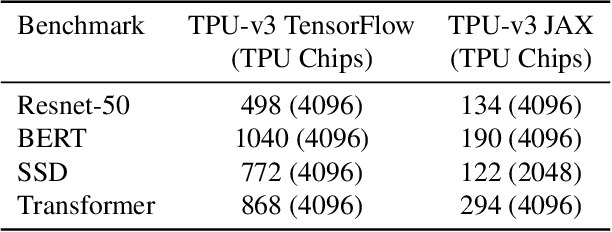
Recent results in language understanding using neural networks have required training hardware of unprecedentedscale, with thousands of chips cooperating on a single training run. This paper presents techniques to scaleML models on the Google TPU Multipod, a mesh with 4096 TPU-v3 chips. We discuss model parallelism toovercome scaling limitations from the fixed batch size in data parallelism, communication/collective optimizations,distributed evaluation of training metrics, and host input processing scaling optimizations. These techniques aredemonstrated in both the TensorFlow and JAX programming frameworks. We also present performance resultsfrom the recent Google submission to the MLPerf-v0.7 benchmark contest, achieving record training times from16 to 28 seconds in four MLPerf models on the Google TPU-v3 Multipod machine.
Exploiting Parallelism Opportunities with Deep Learning Frameworks
Aug 13, 2019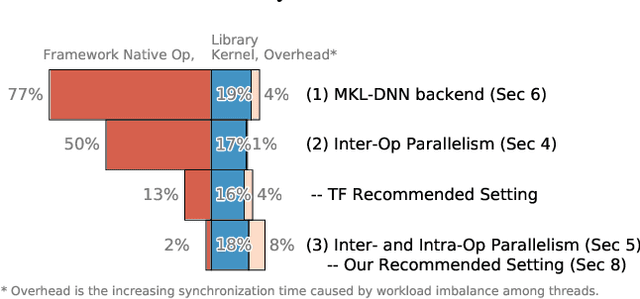
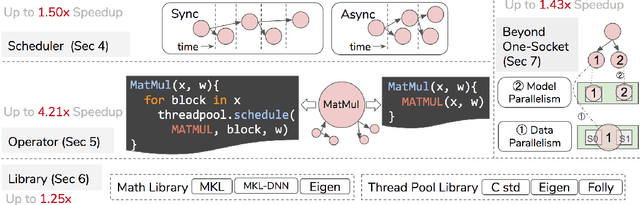
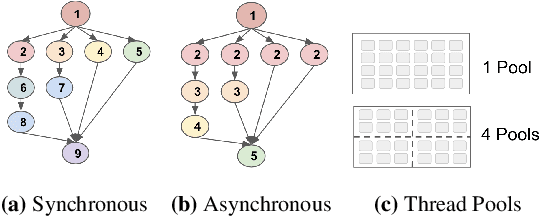
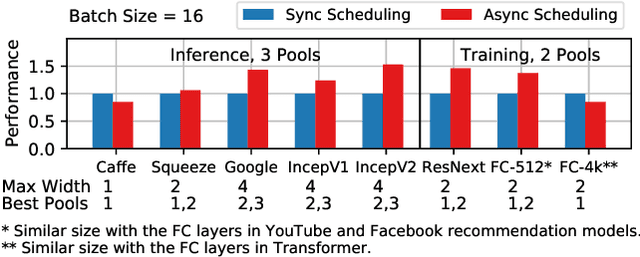
State-of-the-art machine learning frameworks support a wide variety of design features to enable a flexible machine learning programming interface and to ease the programmability burden on machine learning developers. Identifying and using a performance-optimal setting in feature-rich frameworks, however, involves a non-trivial amount of performance characterization and domain-specific knowledge. This paper takes a deep dive into analyzing the performance impact of key design features and the role of parallelism. The observations and insights distill into a simple set of guidelines that one can use to achieve much higher training and inference speedup. The evaluation results show that our proposed performance tuning guidelines outperform both the Intel and TensorFlow recommended settings by 1.29x and 1.34x, respectively, across a diverse set of real-world deep learning models.
Benchmarking TPU, GPU, and CPU Platforms for Deep Learning
Aug 06, 2019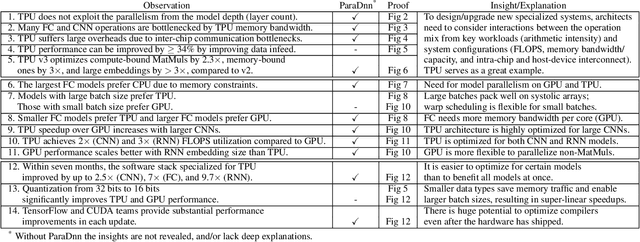
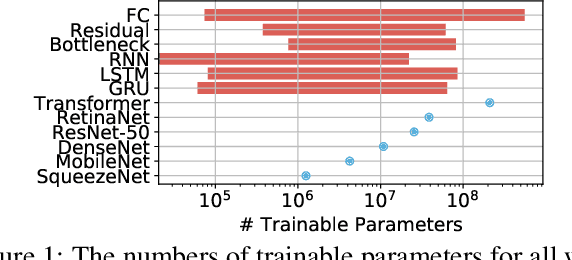
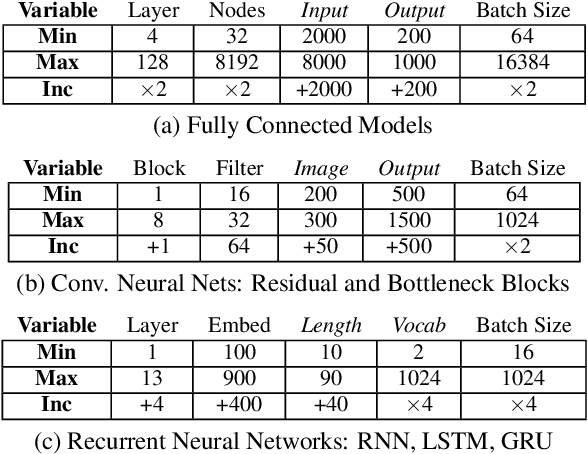
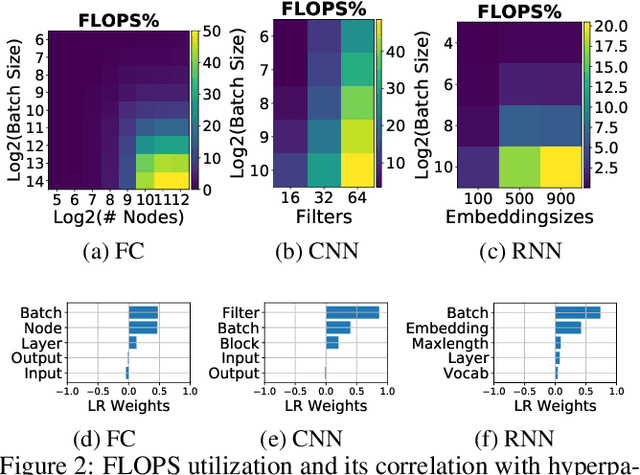
Training deep learning models is compute-intensive and there is an industry-wide trend towards hardware specialization to improve performance. To systematically benchmark deep learning platforms, we introduce ParaDnn, a parameterized benchmark suite for deep learning that generates end-to-end models for fully connected (FC), convolutional (CNN), and recurrent (RNN) neural networks. Along with six real-world models, we benchmark Google's Cloud TPU v2/v3, NVIDIA's V100 GPU, and an Intel Skylake CPU platform. We take a deep dive into TPU architecture, reveal its bottlenecks, and highlight valuable lessons learned for future specialized system design. We also provide a thorough comparison of the platforms and find that each has unique strengths for some types of models. Finally, we quantify the rapid performance improvements that specialized software stacks provide for the TPU and GPU platforms.