 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRewriteLM: An Instruction-Tuned Large Language Model for Text Rewriting
May 25, 2023



Large Language Models (LLMs) have demonstrated impressive zero-shot capabilities in long-form text generation tasks expressed through natural language instructions. However, user expectations for long-form text rewriting is high, and unintended rewrites (''hallucinations'') produced by the model can negatively impact its overall performance. Existing evaluation benchmarks primarily focus on limited rewriting styles and sentence-level rewriting rather than long-form open-ended rewriting.We introduce OpenRewriteEval, a novel benchmark that covers a wide variety of rewriting types expressed through natural language instructions. It is specifically designed to facilitate the evaluation of open-ended rewriting of long-form texts. In addition, we propose a strong baseline model, RewriteLM, an instruction-tuned large language model for long-form text rewriting. We develop new strategies that facilitate the generation of diverse instructions and preference data with minimal human intervention. We conduct empirical experiments and demonstrate that our model outperforms the current state-of-the-art LLMs in text rewriting. Specifically, it excels in preserving the essential content and meaning of the source text, minimizing the generation of ''hallucinated'' content, while showcasing the ability to generate rewrites with diverse wording and structures.
GLaM: Efficient Scaling of Language Models with Mixture-of-Experts
Dec 13, 2021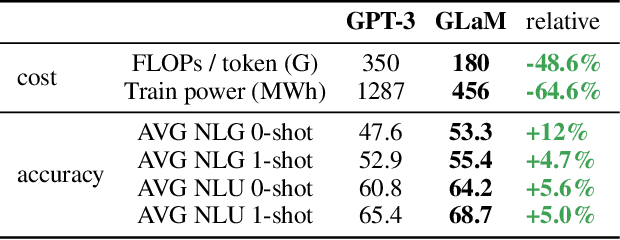
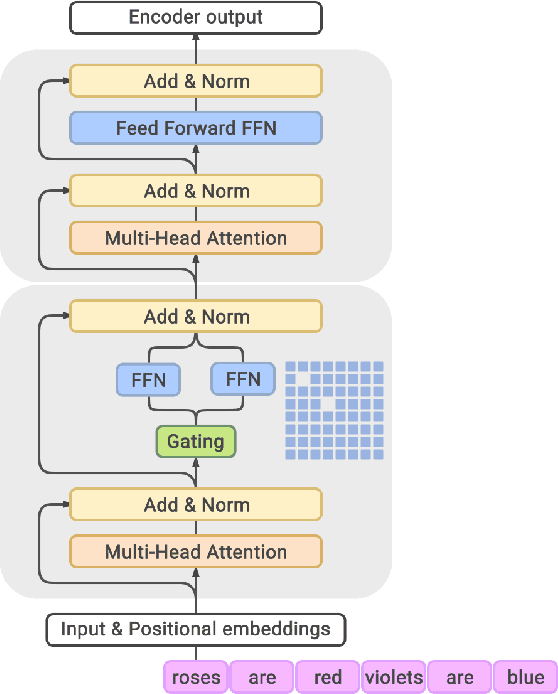
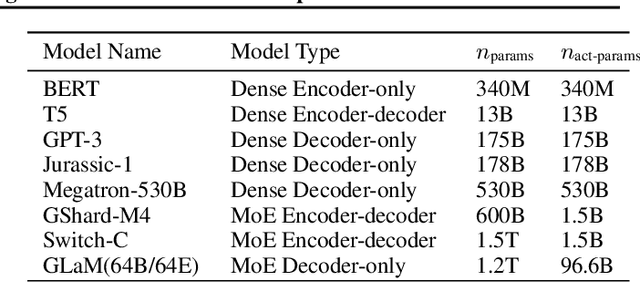
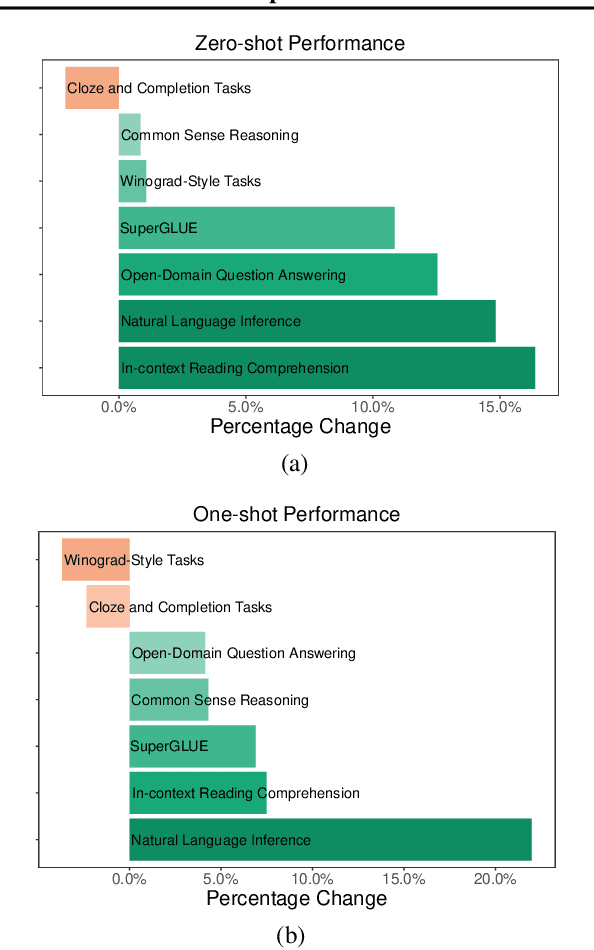
Scaling language models with more data, compute and parameters has driven significant progress in natural language processing. For example, thanks to scaling, GPT-3 was able to achieve strong results on in-context learning tasks. However, training these large dense models requires significant amounts of computing resources. In this paper, we propose and develop a family of language models named GLaM (Generalist Language Model), which uses a sparsely activated mixture-of-experts architecture to scale the model capacity while also incurring substantially less training cost compared to dense variants. The largest GLaM has 1.2 trillion parameters, which is approximately 7x larger than GPT-3. It consumes only 1/3 of the energy used to train GPT-3 and requires half of the computation flops for inference, while still achieving better overall zero-shot and one-shot performance across 29 NLP tasks.
Corpora Generation for Grammatical Error Correction
Apr 10, 2019



Grammatical Error Correction (GEC) has been recently modeled using the sequence-to-sequence framework. However, unlike sequence transduction problems such as machine translation, GEC suffers from the lack of plentiful parallel data. We describe two approaches for generating large parallel datasets for GEC using publicly available Wikipedia data. The first method extracts source-target pairs from Wikipedia edit histories with minimal filtration heuristics, while the second method introduces noise into Wikipedia sentences via round-trip translation through bridge languages. Both strategies yield similar sized parallel corpora containing around 4B tokens. We employ an iterative decoding strategy that is tailored to the loosely supervised nature of our constructed corpora. We demonstrate that neural GEC models trained using either type of corpora give similar performance. Fine-tuning these models on the Lang-8 corpus and ensembling allows us to surpass the state of the art on both the CoNLL-2014 benchmark and the JFLEG task. We provide systematic analysis that compares the two approaches to data generation and highlights the effectiveness of ensembling.