 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoder Denoising Pretraining for Semantic Segmentation
May 23, 2022
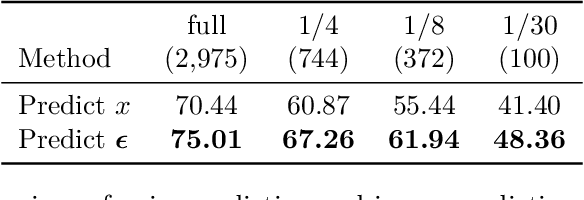
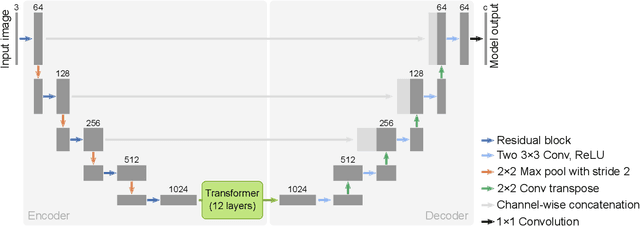
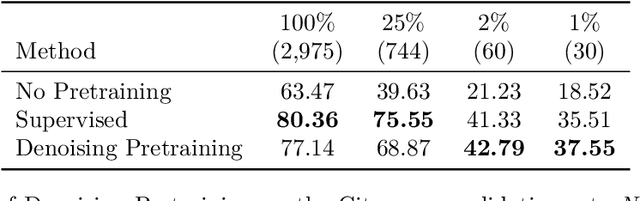
Semantic segmentation labels are expensive and time consuming to acquire. Hence, pretraining is commonly used to improve the label-efficiency of segmentation models. Typically, the encoder of a segmentation model is pretrained as a classifier and the decoder is randomly initialized. Here, we argue that random initialization of the decoder can be suboptimal, especially when few labeled examples are available. We propose a decoder pretraining approach based on denoising, which can be combined with supervised pretraining of the encoder. We find that decoder denoising pretraining on the ImageNet dataset strongly outperforms encoder-only supervised pretraining. Despite its simplicity, decoder denoising pretraining achieves state-of-the-art results on label-efficient semantic segmentation and offers considerable gains on the Cityscapes, Pascal Context, and ADE20K datasets.
Simple and Efficient ways to Improve REALM
Apr 18, 2021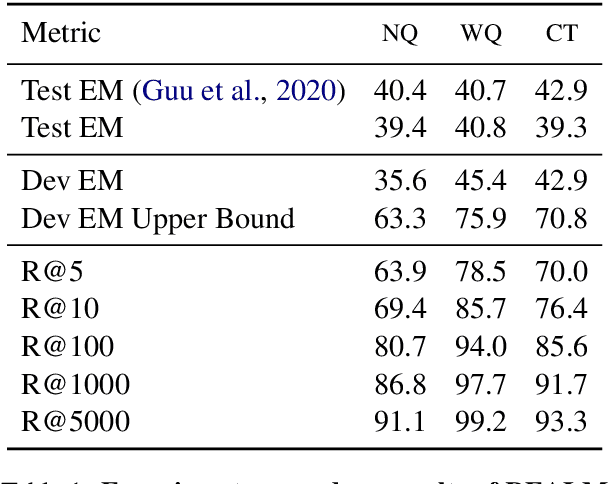



Dense retrieval has been shown to be effective for retrieving relevant documents for Open Domain QA, surpassing popular sparse retrieval methods like BM25. REALM (Guu et al., 2020) is an end-to-end dense retrieval system that relies on MLM based pretraining for improved downstream QA efficiency across multiple datasets. We study the finetuning of REALM on various QA tasks and explore the limits of various hyperparameter and supervision choices. We find that REALM was significantly undertrained when finetuning and simple improvements in the training, supervision, and inference setups can significantly benefit QA results and exceed the performance of other models published post it. Our best model, REALM++, incorporates all the best working findings and achieves significant QA accuracy improvements over baselines (~5.5% absolute accuracy) without any model design changes. Additionally, REALM++ matches the performance of large Open Domain QA models which have 3x more parameters demonstrating the efficiency of the setup.
Scaling Local Self-Attention for Parameter Efficient Visual Backbones
Mar 30, 2021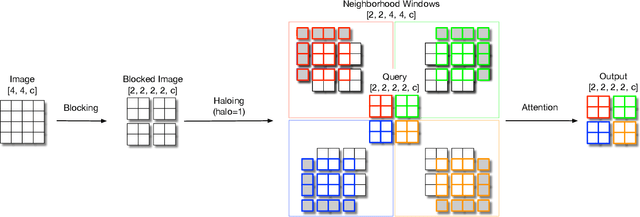
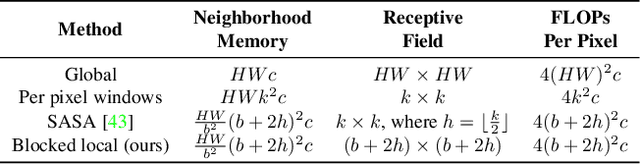
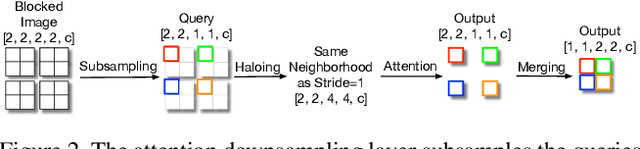

Self-attention has the promise of improving computer vision systems due to parameter-independent scaling of receptive fields and content-dependent interactions, in contrast to parameter-dependent scaling and content-independent interactions of convolutions. Self-attention models have recently been shown to have encouraging improvements on accuracy-parameter trade-offs compared to baseline convolutional models such as ResNet-50. In this work, we aim to develop self-attention models that can outperform not just the canonical baseline models, but even the high-performing convolutional models. We propose two extensions to self-attention that, in conjunction with a more efficient implementation of self-attention, improve the speed, memory usage, and accuracy of these models. We leverage these improvements to develop a new self-attention model family, HaloNets, which reach state-of-the-art accuracies on the parameter-limited setting of the ImageNet classification benchmark. In preliminary transfer learning experiments, we find that HaloNet models outperform much larger models and have better inference performance. On harder tasks such as object detection and instance segmentation, our simple local self-attention and convolutional hybrids show improvements over very strong baselines. These results mark another step in demonstrating the efficacy of self-attention models on settings traditionally dominated by convolutional models.
Bottleneck Transformers for Visual Recognition
Jan 27, 2021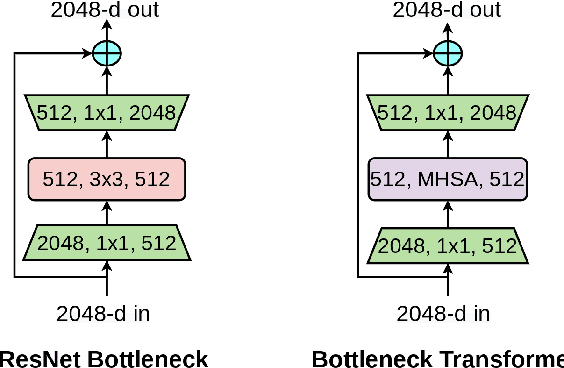
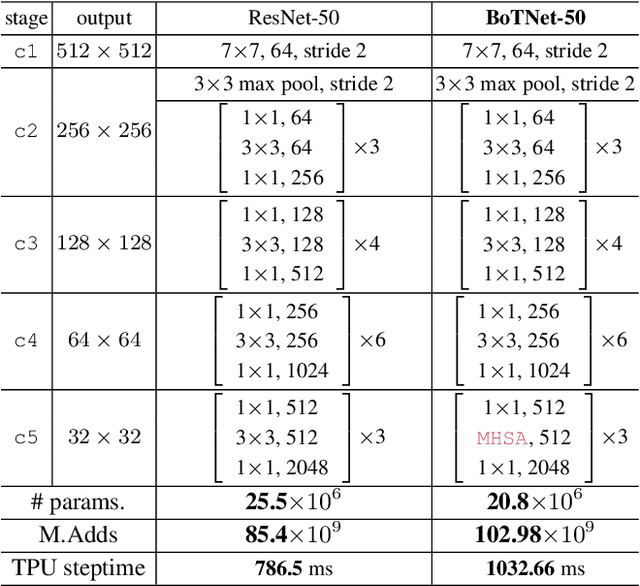
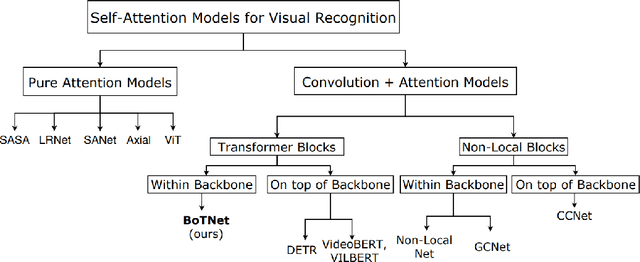
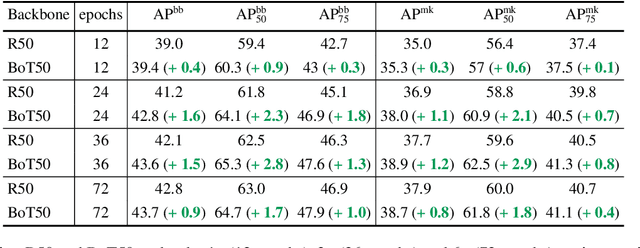
We present BoTNet, a conceptually simple yet powerful backbone architecture that incorporates self-attention for multiple computer vision tasks including image classification, object detection and instance segmentation. By just replacing the spatial convolutions with global self-attention in the final three bottleneck blocks of a ResNet and no other changes, our approach improves upon the baselines significantly on instance segmentation and object detection while also reducing the parameters, with minimal overhead in latency. Through the design of BoTNet, we also point out how ResNet bottleneck blocks with self-attention can be viewed as Transformer blocks. Without any bells and whistles, BoTNet achieves 44.4% Mask AP and 49.7% Box AP on the COCO Instance Segmentation benchmark using the Mask R-CNN framework; surpassing the previous best published single model and single scale results of ResNeSt evaluated on the COCO validation set. Finally, we present a simple adaptation of the BoTNet design for image classification, resulting in models that achieve a strong performance of 84.7% top-1 accuracy on the ImageNet benchmark while being up to 2.33x faster in compute time than the popular EfficientNet models on TPU-v3 hardware. We hope our simple and effective approach will serve as a strong baseline for future research in self-attention models for vision.
Conformer: Convolution-augmented Transformer for Speech Recognition
May 16, 2020
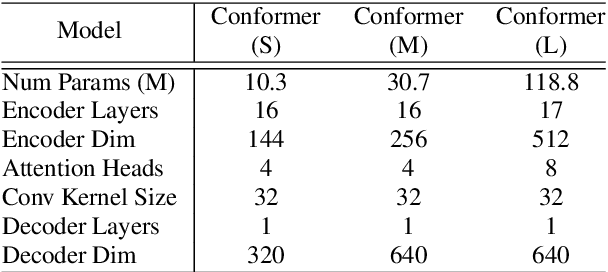

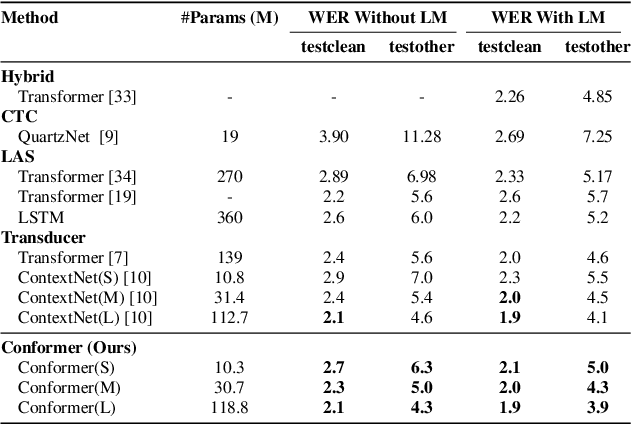
Recently Transformer and Convolution neural network (CNN) based models have shown promising results in Automatic Speech Recognition (ASR), outperforming Recurrent neural networks (RNNs). Transformer models are good at capturing content-based global interactions, while CNNs exploit local features effectively. In this work, we achieve the best of both worlds by studying how to combine convolution neural networks and transformers to model both local and global dependencies of an audio sequence in a parameter-efficient way. To this regard, we propose the convolution-augmented transformer for speech recognition, named Conformer. Conformer significantly outperforms the previous Transformer and CNN based models achieving state-of-the-art accuracies. On the widely used LibriSpeech benchmark, our model achieves WER of 2.1%/4.3% without using a language model and 1.9%/3.9% with an external language model on test/testother. We also observe competitive performance of 2.7%/6.3% with a small model of only 10M parameters.
High Resolution Medical Image Analysis with Spatial Partitioning
Sep 12, 2019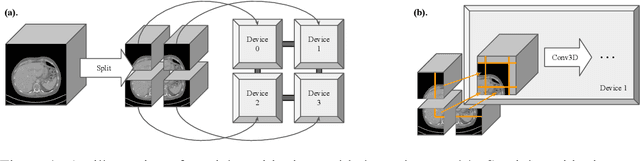
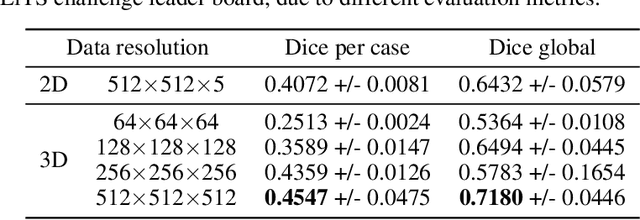

Medical images such as 3D computerized tomography (CT) scans and pathology images, have hundreds of millions or billions of voxels/pixels. It is infeasible to train CNN models directly on such high resolution images, because neural activations of a single image do not fit in the memory of a single GPU/TPU, and naive data and model parallelism approaches do not work. Existing image analysis approaches alleviate this problem by cropping or down-sampling input images, which leads to complicated implementation and sub-optimal performance due to information loss. In this paper, we implement spatial partitioning, which internally distributes the input and output of convolutional layers across GPUs/TPUs. Our implementation is based on the Mesh-TensorFlow framework and the computation distribution is transparent to end users. With this technique, we train a 3D Unet on up to 512 by 512 by 512 resolution data. To the best of our knowledge, this is the first work for handling such high resolution images end-to-end.
Stand-Alone Self-Attention in Vision Models
Jun 13, 2019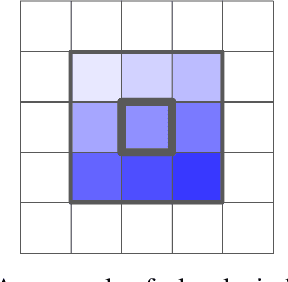
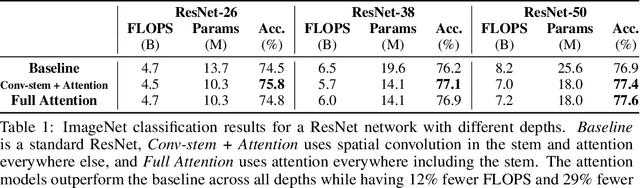
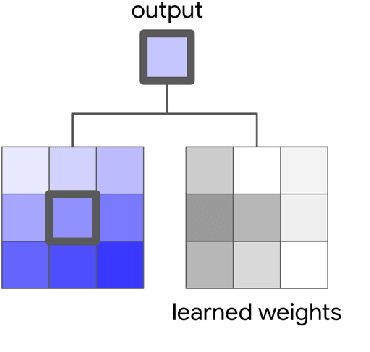
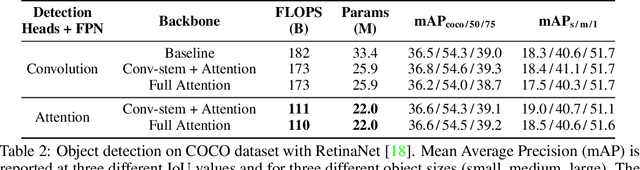
Convolutions are a fundamental building block of modern computer vision systems. Recent approaches have argued for going beyond convolutions in order to capture long-range dependencies. These efforts focus on augmenting convolutional models with content-based interactions, such as self-attention and non-local means, to achieve gains on a number of vision tasks. The natural question that arises is whether attention can be a stand-alone primitive for vision models instead of serving as just an augmentation on top of convolutions. In developing and testing a pure self-attention vision model, we verify that self-attention can indeed be an effective stand-alone layer. A simple procedure of replacing all instances of spatial convolutions with a form of self-attention applied to ResNet model produces a fully self-attentional model that outperforms the baseline on ImageNet classification with 12% fewer FLOPS and 29% fewer parameters. On COCO object detection, a pure self-attention model matches the mAP of a baseline RetinaNet while having 39% fewer FLOPS and 34% fewer parameters. Detailed ablation studies demonstrate that self-attention is especially impactful when used in later layers. These results establish that stand-alone self-attention is an important addition to the vision practitioner's toolbox.
Corpora Generation for Grammatical Error Correction
Apr 10, 2019



Grammatical Error Correction (GEC) has been recently modeled using the sequence-to-sequence framework. However, unlike sequence transduction problems such as machine translation, GEC suffers from the lack of plentiful parallel data. We describe two approaches for generating large parallel datasets for GEC using publicly available Wikipedia data. The first method extracts source-target pairs from Wikipedia edit histories with minimal filtration heuristics, while the second method introduces noise into Wikipedia sentences via round-trip translation through bridge languages. Both strategies yield similar sized parallel corpora containing around 4B tokens. We employ an iterative decoding strategy that is tailored to the loosely supervised nature of our constructed corpora. We demonstrate that neural GEC models trained using either type of corpora give similar performance. Fine-tuning these models on the Lang-8 corpus and ensembling allows us to surpass the state of the art on both the CoNLL-2014 benchmark and the JFLEG task. We provide systematic analysis that compares the two approaches to data generation and highlights the effectiveness of ensembling.
Mesh-TensorFlow: Deep Learning for Supercomputers
Nov 05, 2018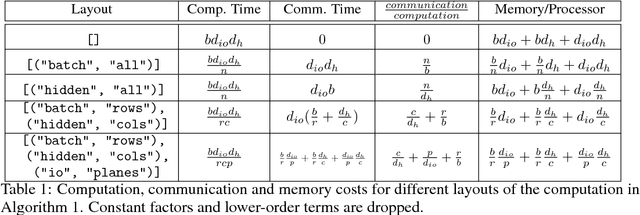
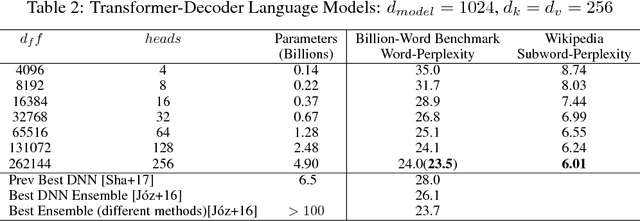
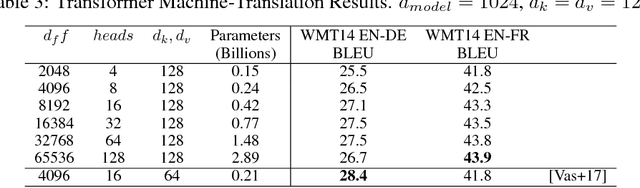
Batch-splitting (data-parallelism) is the dominant distributed Deep Neural Network (DNN) training strategy, due to its universal applicability and its amenability to Single-Program-Multiple-Data (SPMD) programming. However, batch-splitting suffers from problems including the inability to train very large models (due to memory constraints), high latency, and inefficiency at small batch sizes. All of these can be solved by more general distribution strategies (model-parallelism). Unfortunately, efficient model-parallel algorithms tend to be complicated to discover, describe, and to implement, particularly on large clusters. We introduce Mesh-TensorFlow, a language for specifying a general class of distributed tensor computations. Where data-parallelism can be viewed as splitting tensors and operations along the "batch" dimension, in Mesh-TensorFlow, the user can specify any tensor-dimensions to be split across any dimensions of a multi-dimensional mesh of processors. A Mesh-TensorFlow graph compiles into a SPMD program consisting of parallel operations coupled with collective communication primitives such as Allreduce. We use Mesh-TensorFlow to implement an efficient data-parallel, model-parallel version of the Transformer sequence-to-sequence model. Using TPU meshes of up to 512 cores, we train Transformer models with up to 5 billion parameters, surpassing state of the art results on WMT'14 English-to-French translation task and the one-billion-word language modeling benchmark. Mesh-Tensorflow is available at https://github.com/tensorflow/mesh .
Weakly Supervised Grammatical Error Correction using Iterative Decoding
Oct 31, 2018
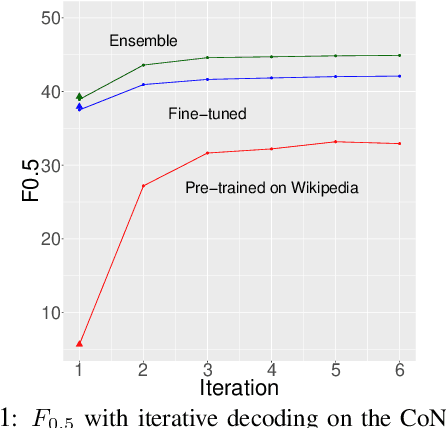
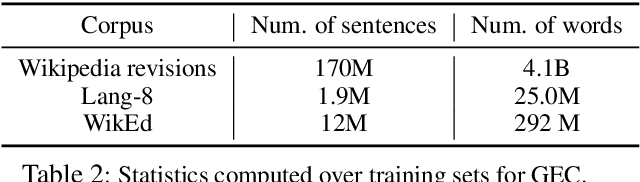

We describe an approach to Grammatical Error Correction (GEC) that is effective at making use of models trained on large amounts of weakly supervised bitext. We train the Transformer sequence-to-sequence model on 4B tokens of Wikipedia revisions and employ an iterative decoding strategy that is tailored to the loosely-supervised nature of the Wikipedia training corpus. Finetuning on the Lang-8 corpus and ensembling yields an F0.5 of 58.3 on the CoNLL'14 benchmark and a GLEU of 62.4 on JFLEG. The combination of weakly supervised training and iterative decoding obtains an F0.5 of 48.2 on CoNLL'14 even without using any labeled GEC data.