 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Local Self-Attention for Parameter Efficient Visual Backbones
Mar 30, 2021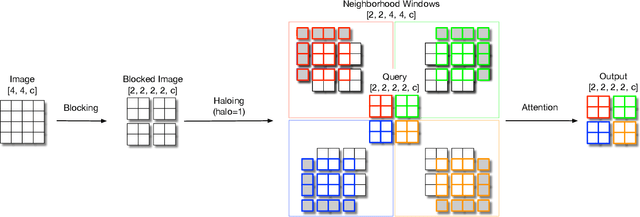
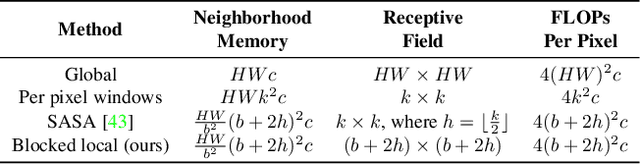
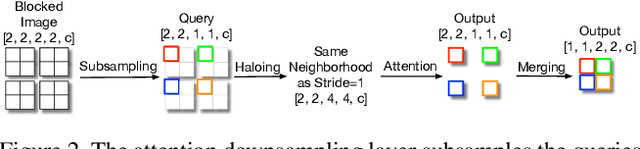

Self-attention has the promise of improving computer vision systems due to parameter-independent scaling of receptive fields and content-dependent interactions, in contrast to parameter-dependent scaling and content-independent interactions of convolutions. Self-attention models have recently been shown to have encouraging improvements on accuracy-parameter trade-offs compared to baseline convolutional models such as ResNet-50. In this work, we aim to develop self-attention models that can outperform not just the canonical baseline models, but even the high-performing convolutional models. We propose two extensions to self-attention that, in conjunction with a more efficient implementation of self-attention, improve the speed, memory usage, and accuracy of these models. We leverage these improvements to develop a new self-attention model family, HaloNets, which reach state-of-the-art accuracies on the parameter-limited setting of the ImageNet classification benchmark. In preliminary transfer learning experiments, we find that HaloNet models outperform much larger models and have better inference performance. On harder tasks such as object detection and instance segmentation, our simple local self-attention and convolutional hybrids show improvements over very strong baselines. These results mark another step in demonstrating the efficacy of self-attention models on settings traditionally dominated by convolutional models.
Revisiting Fundamentals of Experience Replay
Jul 13, 2020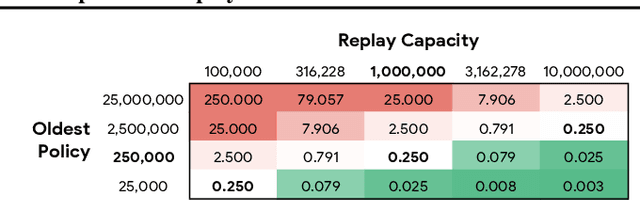

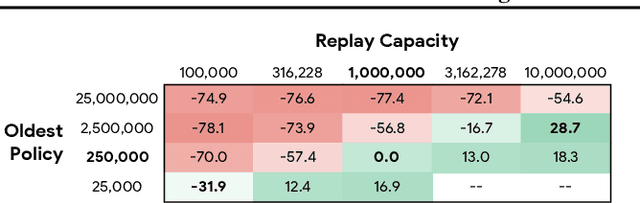
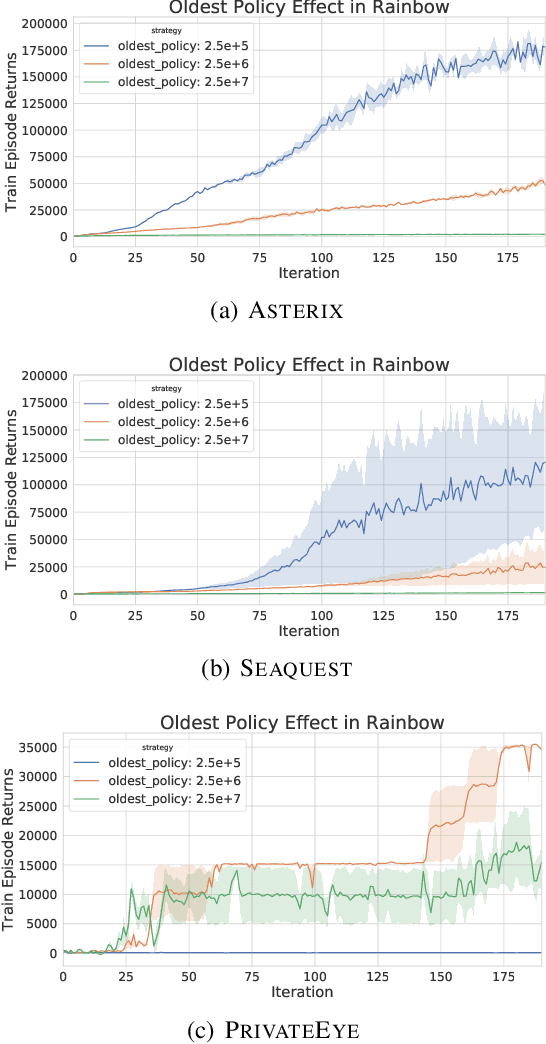
Experience replay is central to off-policy algorithms in deep reinforcement learning (RL), but there remain significant gaps in our understanding. We therefore present a systematic and extensive analysis of experience replay in Q-learning methods, focusing on two fundamental properties: the replay capacity and the ratio of learning updates to experience collected (replay ratio). Our additive and ablative studies upend conventional wisdom around experience replay -- greater capacity is found to substantially increase the performance of certain algorithms, while leaving others unaffected. Counterintuitively we show that theoretically ungrounded, uncorrected n-step returns are uniquely beneficial while other techniques confer limited benefit for sifting through larger memory. Separately, by directly controlling the replay ratio we contextualize previous observations in the literature and empirically measure its importance across a variety of deep RL algorithms. Finally, we conclude by testing a set of hypotheses on the nature of these performance benefits.
Revisiting Spatial Invariance with Low-Rank Local Connectivity
Feb 07, 2020



Convolutional neural networks are among the most successful architectures in deep learning. This success is at least partially attributable to the efficacy of spatial invariance as an inductive bias. Locally connected layers, which differ from convolutional layers in their lack of spatial invariance, usually perform poorly in practice. However, these observations still leave open the possibility that some degree of relaxation of spatial invariance may yield a better inductive bias than either convolution or local connectivity. To test this hypothesis, we design a method to relax the spatial invariance of a network layer in a controlled manner. In particular, we create a \textit{low-rank} locally connected layer, where the filter bank applied at each position is constructed as a linear combination of basis set of filter banks. By varying the number of filter banks in the basis set, we can control the degree of departure from spatial invariance. In our experiments, we find that relaxing spatial invariance improves classification accuracy over both convolution and locally connected layers across MNIST, CIFAR-10, and CelebA datasets. These results suggest that spatial invariance in convolution layers may be overly restrictive.
Stand-Alone Self-Attention in Vision Models
Jun 13, 2019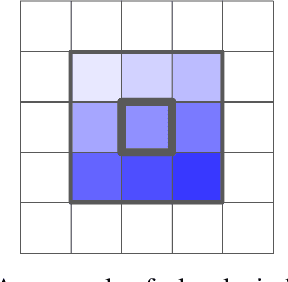
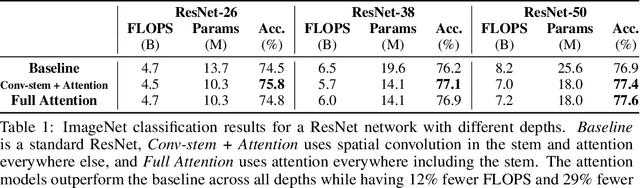
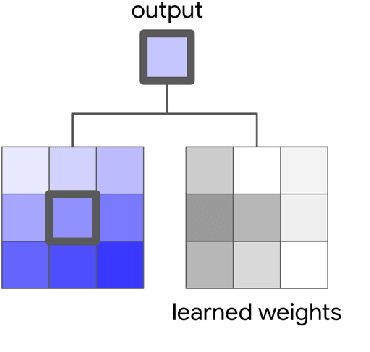
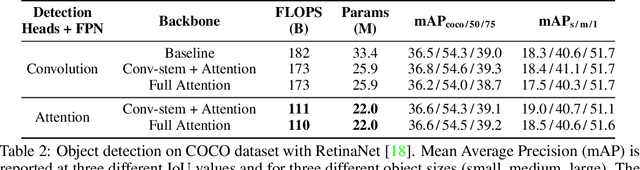
Convolutions are a fundamental building block of modern computer vision systems. Recent approaches have argued for going beyond convolutions in order to capture long-range dependencies. These efforts focus on augmenting convolutional models with content-based interactions, such as self-attention and non-local means, to achieve gains on a number of vision tasks. The natural question that arises is whether attention can be a stand-alone primitive for vision models instead of serving as just an augmentation on top of convolutions. In developing and testing a pure self-attention vision model, we verify that self-attention can indeed be an effective stand-alone layer. A simple procedure of replacing all instances of spatial convolutions with a form of self-attention applied to ResNet model produces a fully self-attentional model that outperforms the baseline on ImageNet classification with 12% fewer FLOPS and 29% fewer parameters. On COCO object detection, a pure self-attention model matches the mAP of a baseline RetinaNet while having 39% fewer FLOPS and 34% fewer parameters. Detailed ablation studies demonstrate that self-attention is especially impactful when used in later layers. These results establish that stand-alone self-attention is an important addition to the vision practitioner's toolbox.
Backprop Evolution
Aug 08, 2018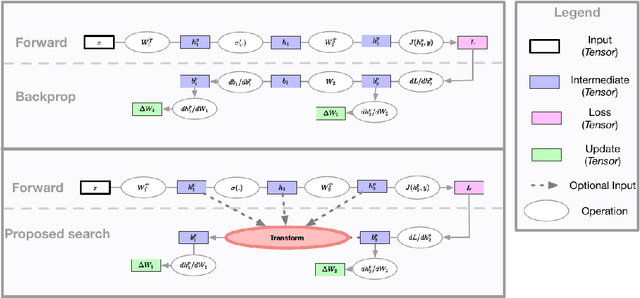
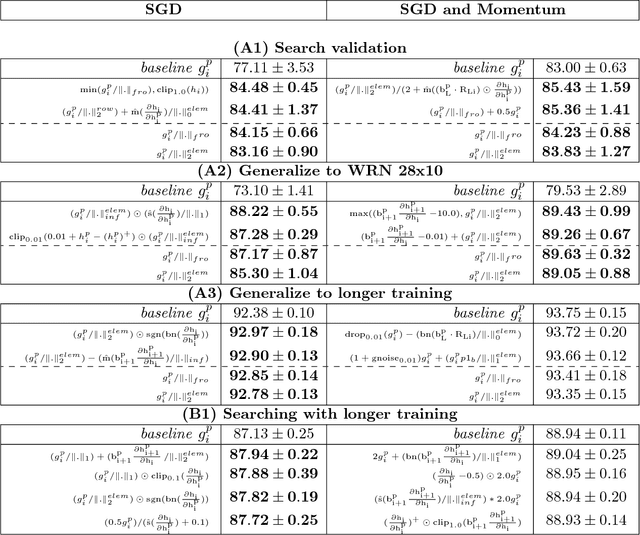
The back-propagation algorithm is the cornerstone of deep learning. Despite its importance, few variations of the algorithm have been attempted. This work presents an approach to discover new variations of the back-propagation equation. We use a domain specific lan- guage to describe update equations as a list of primitive functions. An evolution-based method is used to discover new propagation rules that maximize the generalization per- formance after a few epochs of training. We find several update equations that can train faster with short training times than standard back-propagation, and perform similar as standard back-propagation at convergence.
Unsupervised Pretraining for Sequence to Sequence Learning
Feb 22, 2018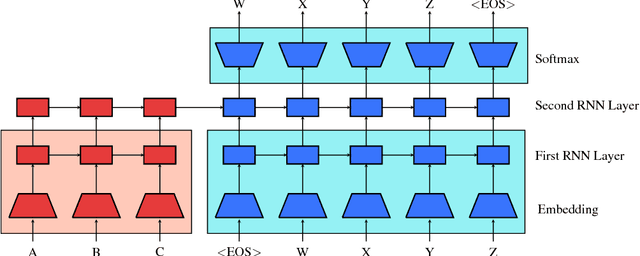

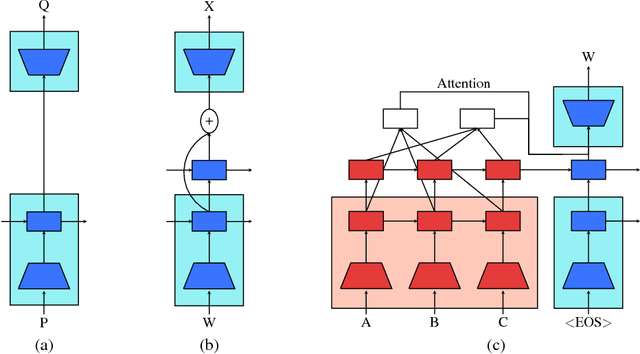

This work presents a general unsupervised learning method to improve the accuracy of sequence to sequence (seq2seq) models. In our method, the weights of the encoder and decoder of a seq2seq model are initialized with the pretrained weights of two language models and then fine-tuned with labeled data. We apply this method to challenging benchmarks in machine translation and abstractive summarization and find that it significantly improves the subsequent supervised models. Our main result is that pretraining improves the generalization of seq2seq models. We achieve state-of-the art results on the WMT English$\rightarrow$German task, surpassing a range of methods using both phrase-based machine translation and neural machine translation. Our method achieves a significant improvement of 1.3 BLEU from the previous best models on both WMT'14 and WMT'15 English$\rightarrow$German. We also conduct human evaluations on abstractive summarization and find that our method outperforms a purely supervised learning baseline in a statistically significant manner.
Searching for Activation Functions
Oct 27, 2017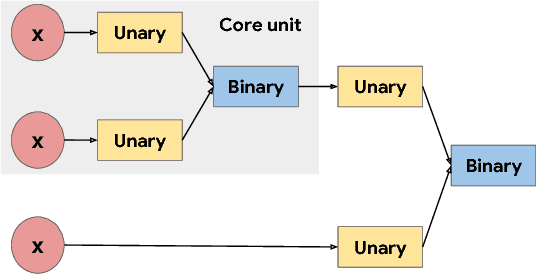
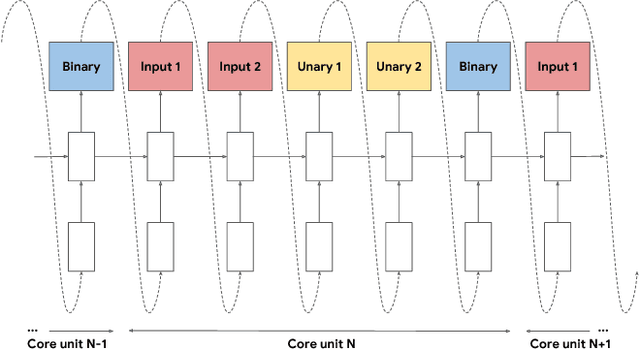
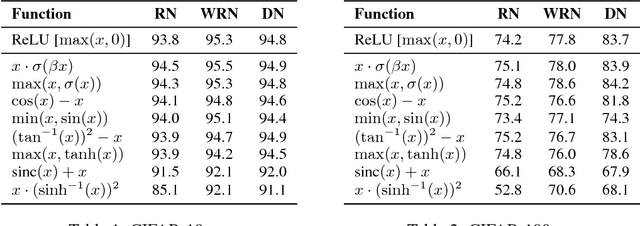
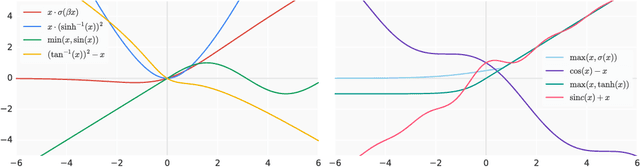
The choice of activation functions in deep networks has a significant effect on the training dynamics and task performance. Currently, the most successful and widely-used activation function is the Rectified Linear Unit (ReLU). Although various hand-designed alternatives to ReLU have been proposed, none have managed to replace it due to inconsistent gains. In this work, we propose to leverage automatic search techniques to discover new activation functions. Using a combination of exhaustive and reinforcement learning-based search, we discover multiple novel activation functions. We verify the effectiveness of the searches by conducting an empirical evaluation with the best discovered activation function. Our experiments show that the best discovered activation function, $f(x) = x \cdot \text{sigmoid}(\beta x)$, which we name Swish, tends to work better than ReLU on deeper models across a number of challenging datasets. For example, simply replacing ReLUs with Swish units improves top-1 classification accuracy on ImageNet by 0.9\% for Mobile NASNet-A and 0.6\% for Inception-ResNet-v2. The simplicity of Swish and its similarity to ReLU make it easy for practitioners to replace ReLUs with Swish units in any neural network.
Fast Generation for Convolutional Autoregressive Models
Apr 20, 2017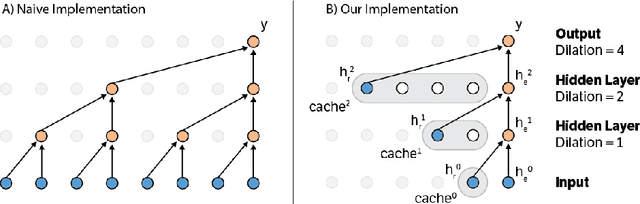
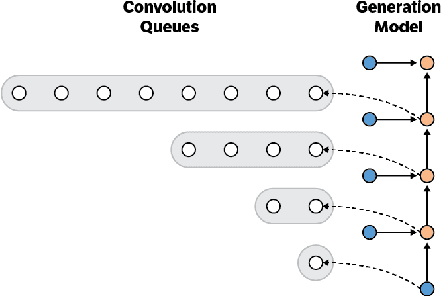
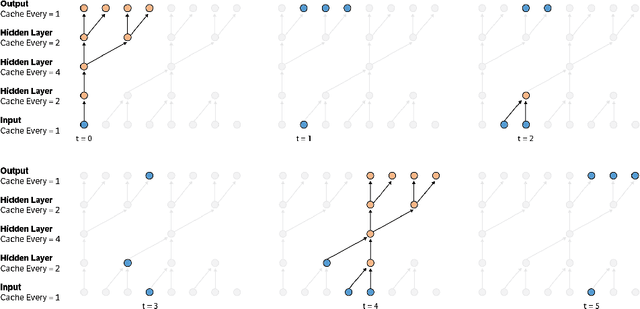
Convolutional autoregressive models have recently demonstrated state-of-the-art performance on a number of generation tasks. While fast, parallel training methods have been crucial for their success, generation is typically implemented in a na\"{i}ve fashion where redundant computations are unnecessarily repeated. This results in slow generation, making such models infeasible for production environments. In this work, we describe a method to speed up generation in convolutional autoregressive models. The key idea is to cache hidden states to avoid redundant computation. We apply our fast generation method to the Wavenet and PixelCNN++ models and achieve up to $21\times$ and $183\times$ speedups respectively.
Stein Variational Policy Gradient
Apr 07, 2017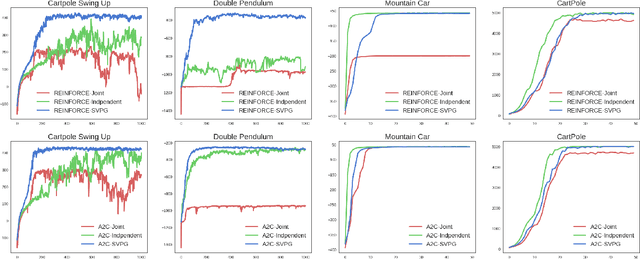
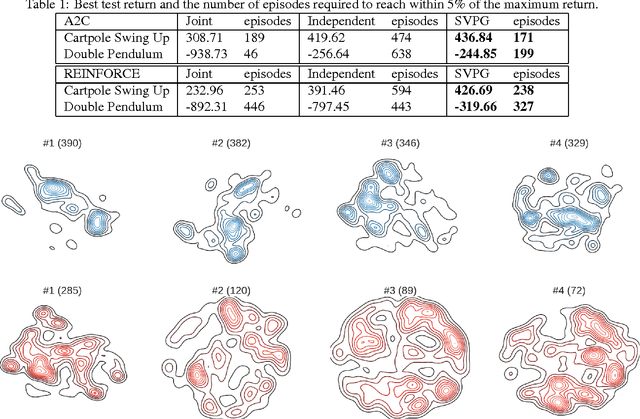
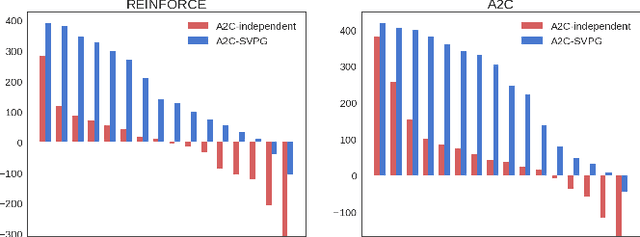
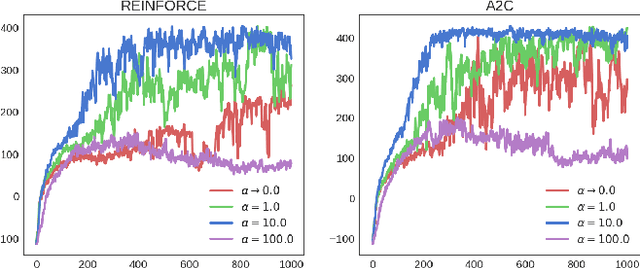
Policy gradient methods have been successfully applied to many complex reinforcement learning problems. However, policy gradient methods suffer from high variance, slow convergence, and inefficient exploration. In this work, we introduce a maximum entropy policy optimization framework which explicitly encourages parameter exploration, and show that this framework can be reduced to a Bayesian inference problem. We then propose a novel Stein variational policy gradient method (SVPG) which combines existing policy gradient methods and a repulsive functional to generate a set of diverse but well-behaved policies. SVPG is robust to initialization and can easily be implemented in a parallel manner. On continuous control problems, we find that implementing SVPG on top of REINFORCE and advantage actor-critic algorithms improves both average return and data efficiency.
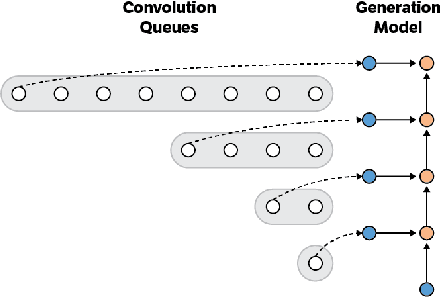
Fast Wavenet Generation Algorithm
Nov 29, 2016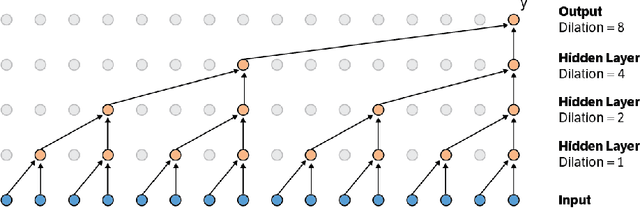
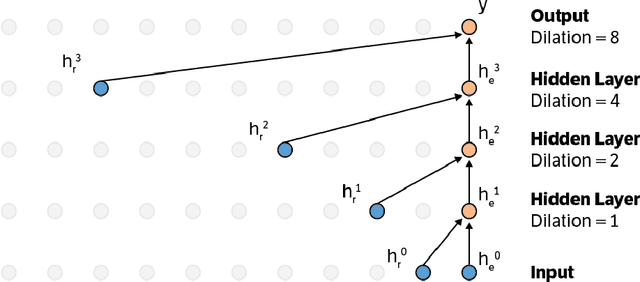
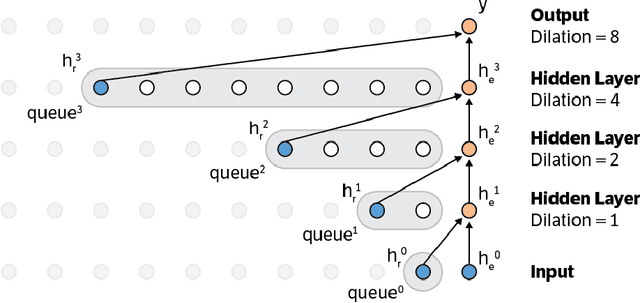
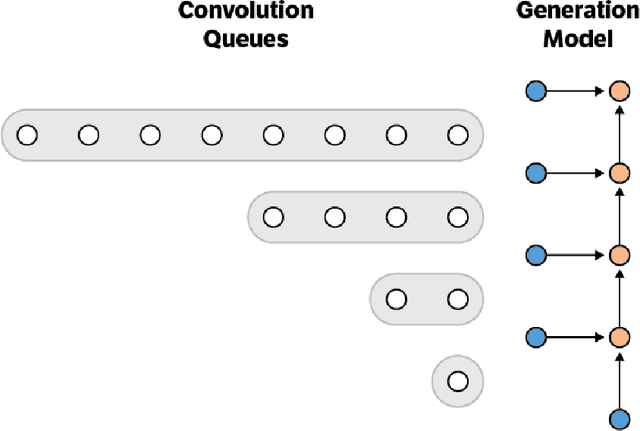
This paper presents an efficient implementation of the Wavenet generation process called Fast Wavenet. Compared to a naive implementation that has complexity O(2^L) (L denotes the number of layers in the network), our proposed approach removes redundant convolution operations by caching previous calculations, thereby reducing the complexity to O(L) time. Timing experiments show significant advantages of our fast implementation over a naive one. While this method is presented for Wavenet, the same scheme can be applied anytime one wants to perform autoregressive generation or online prediction using a model with dilated convolution layers. The code for our method is publicly available.