 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Sustainable Investment Policies Informed by Opponent Shaping
Feb 12, 2026Addressing climate change requires global coordination, yet rational economic actors often prioritize immediate gains over collective welfare, resulting in social dilemmas. InvestESG is a recently proposed multi-agent simulation that captures the dynamic interplay between investors and companies under climate risk. We provide a formal characterization of the conditions under which InvestESG exhibits an intertemporal social dilemma, deriving theoretical thresholds at which individual incentives diverge from collective welfare. Building on this, we apply Advantage Alignment, a scalable opponent shaping algorithm shown to be effective in general-sum games, to influence agent learning in InvestESG. We offer theoretical insights into why Advantage Alignment systematically favors socially beneficial equilibria by biasing learning dynamics toward cooperative outcomes. Our results demonstrate that strategically shaping the learning processes of economic agents can result in better outcomes that could inform policy mechanisms to better align market incentives with long-term sustainability goals.
BRIDGE: Predicting Human Task Completion Time From Model Performance
Feb 06, 2026Evaluating the real-world capabilities of AI systems requires grounding benchmark performance in human-interpretable measures of task difficulty. Existing approaches that rely on direct human task completion time annotations are costly, noisy, and difficult to scale across benchmarks. In this work, we propose BRIDGE, a unified psychometric framework that learns the latent difficulty scale from model responses and anchors it to human task completion time. Using a two-parameter logistic Item Response Theory model, we jointly estimate latent task difficulty and model capability from model performance data across multiple benchmarks. We demonstrate that latent task difficulty varies linearly with the logarithm of human completion time, allowing human task completion time to be inferred for new benchmarks from model performance alone. Leveraging this alignment, we forecast frontier model capabilities in terms of human task length and independently reproduce METR's exponential scaling results, with the 50% solvable task horizon doubling approximately every 6 months.
Bringing SAM to new heights: Leveraging elevation data for tree crown segmentation from drone imagery
Jun 05, 2025Information on trees at the individual level is crucial for monitoring forest ecosystems and planning forest management. Current monitoring methods involve ground measurements, requiring extensive cost, time and labor. Advances in drone remote sensing and computer vision offer great potential for mapping individual trees from aerial imagery at broad-scale. Large pre-trained vision models, such as the Segment Anything Model (SAM), represent a particularly compelling choice given limited labeled data. In this work, we compare methods leveraging SAM for the task of automatic tree crown instance segmentation in high resolution drone imagery in three use cases: 1) boreal plantations, 2) temperate forests and 3) tropical forests. We also study the integration of elevation data into models, in the form of Digital Surface Model (DSM) information, which can readily be obtained at no additional cost from RGB drone imagery. We present BalSAM, a model leveraging SAM and DSM information, which shows potential over other methods, particularly in the context of plantations. We find that methods using SAM out-of-the-box do not outperform a custom Mask R-CNN, even with well-designed prompts. However, efficiently tuning SAM end-to-end and integrating DSM information are both promising avenues for tree crown instance segmentation models.
The Search for Squawk: Agile Modeling in Bioacoustics
May 07, 2025Passive acoustic monitoring (PAM) has shown great promise in helping ecologists understand the health of animal populations and ecosystems. However, extracting insights from millions of hours of audio recordings requires the development of specialized recognizers. This is typically a challenging task, necessitating large amounts of training data and machine learning expertise. In this work, we introduce a general, scalable and data-efficient system for developing recognizers for novel bioacoustic problems in under an hour. Our system consists of several key components that tackle problems in previous bioacoustic workflows: 1) highly generalizable acoustic embeddings pre-trained for birdsong classification minimize data hunger; 2) indexed audio search allows the efficient creation of classifier training datasets, and 3) precomputation of embeddings enables an efficient active learning loop, improving classifier quality iteratively with minimal wait time. Ecologists employed our system in three novel case studies: analyzing coral reef health through unidentified sounds; identifying juvenile Hawaiian bird calls to quantify breeding success and improve endangered species monitoring; and Christmas Island bird occupancy modeling. We augment the case studies with simulated experiments which explore the range of design decisions in a structured way and help establish best practices. Altogether these experiments showcase our system's scalability, efficiency, and generalizability, enabling scientists to quickly address new bioacoustic challenges.
Assessing SAM for Tree Crown Instance Segmentation from Drone Imagery
Mar 26, 2025The potential of tree planting as a natural climate solution is often undermined by inadequate monitoring of tree planting projects. Current monitoring methods involve measuring trees by hand for each species, requiring extensive cost, time, and labour. Advances in drone remote sensing and computer vision offer great potential for mapping and characterizing trees from aerial imagery, and large pre-trained vision models, such as the Segment Anything Model (SAM), may be a particularly compelling choice given limited labeled data. In this work, we compare SAM methods for the task of automatic tree crown instance segmentation in high resolution drone imagery of young tree plantations. We explore the potential of SAM for this task, and find that methods using SAM out-of-the-box do not outperform a custom Mask R-CNN, even with well-designed prompts, but that there is potential for methods which tune SAM further. We also show that predictions can be improved by adding Digital Surface Model (DSM) information as an input.
Capturing Individual Human Preferences with Reward Features
Mar 21, 2025



Reinforcement learning from human feedback usually models preferences using a reward model that does not distinguish between people. We argue that this is unlikely to be a good design choice in contexts with high potential for disagreement, like in the training of large language models. We propose a method to specialise a reward model to a person or group of people. Our approach builds on the observation that individual preferences can be captured as a linear combination of a set of general reward features. We show how to learn such features and subsequently use them to quickly adapt the reward model to a specific individual, even if their preferences are not reflected in the training data. We present experiments with large language models comparing the proposed architecture with a non-adaptive reward model and also adaptive counterparts, including models that do in-context personalisation. Depending on how much disagreement there is in the training data, our model either significantly outperforms the baselines or matches their performance with a simpler architecture and more stable training.
Don't flatten, tokenize! Unlocking the key to SoftMoE's efficacy in deep RL
Oct 02, 2024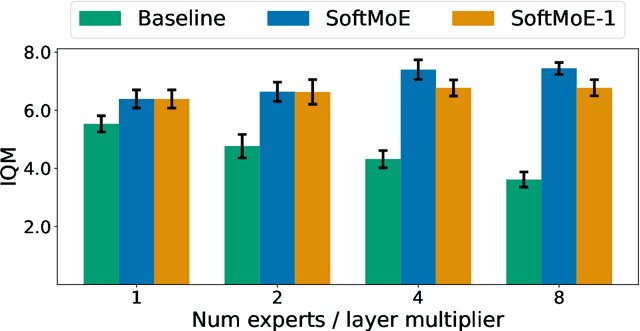
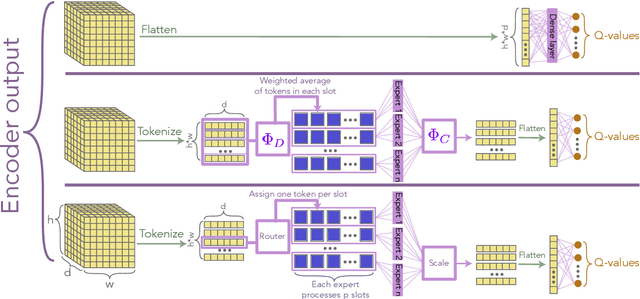
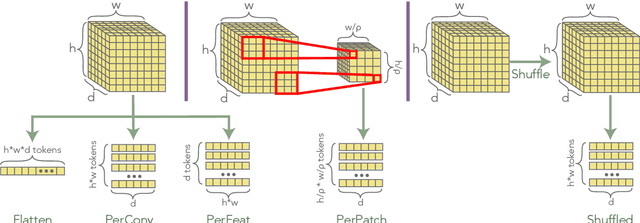
The use of deep neural networks in reinforcement learning (RL) often suffers from performance degradation as model size increases. While soft mixtures of experts (SoftMoEs) have recently shown promise in mitigating this issue for online RL, the reasons behind their effectiveness remain largely unknown. In this work we provide an in-depth analysis identifying the key factors driving this performance gain. We discover the surprising result that tokenizing the encoder output, rather than the use of multiple experts, is what is behind the efficacy of SoftMoEs. Indeed, we demonstrate that even with an appropriately scaled single expert, we are able to maintain the performance gains, largely thanks to tokenization.
Many-Shot In-Context Learning
Apr 17, 2024



Large language models (LLMs) excel at few-shot in-context learning (ICL) -- learning from a few examples provided in context at inference, without any weight updates. Newly expanded context windows allow us to investigate ICL with hundreds or thousands of examples -- the many-shot regime. Going from few-shot to many-shot, we observe significant performance gains across a wide variety of generative and discriminative tasks. While promising, many-shot ICL can be bottlenecked by the available amount of human-generated examples. To mitigate this limitation, we explore two new settings: Reinforced and Unsupervised ICL. Reinforced ICL uses model-generated chain-of-thought rationales in place of human examples. Unsupervised ICL removes rationales from the prompt altogether, and prompts the model only with domain-specific questions. We find that both Reinforced and Unsupervised ICL can be quite effective in the many-shot regime, particularly on complex reasoning tasks. Finally, we demonstrate that, unlike few-shot learning, many-shot learning is effective at overriding pretraining biases and can learn high-dimensional functions with numerical inputs. Our analysis also reveals the limitations of next-token prediction loss as an indicator of downstream ICL performance.
A density estimation perspective on learning from pairwise human preferences
Nov 30, 2023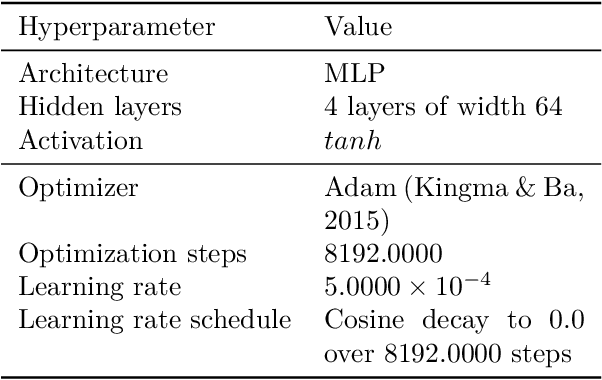


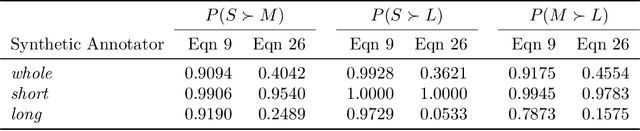
Learning from human feedback (LHF) -- and in particular learning from pairwise preferences -- has recently become a crucial ingredient in training large language models (LLMs), and has been the subject of much research. Most recent works frame it as a reinforcement learning problem, where a reward function is learned from pairwise preference data and the LLM is treated as a policy which is adapted to maximize the rewards, often under additional regularization constraints. We propose an alternative interpretation which centers on the generative process for pairwise preferences and treats LHF as a density estimation problem. We provide theoretical and empirical results showing that for a family of generative processes defined via preference behavior distribution equations, training a reward function on pairwise preferences effectively models an annotator's implicit preference distribution. Finally, we discuss and present findings on "annotator misspecification" -- failure cases where wrong modeling assumptions are made about annotator behavior, resulting in poorly-adapted models -- suggesting that approaches that learn from pairwise human preferences could have trouble learning from a population of annotators with diverse viewpoints.
Unlearning via Sparse Representations
Nov 26, 2023Machine \emph{unlearning}, which involves erasing knowledge about a \emph{forget set} from a trained model, can prove to be costly and infeasible by existing techniques. We propose a nearly compute-free zero-shot unlearning technique based on a discrete representational bottleneck. We show that the proposed technique efficiently unlearns the forget set and incurs negligible damage to the model's performance on the rest of the data set. We evaluate the proposed technique on the problem of \textit{class unlearning} using three datasets: CIFAR-10, CIFAR-100, and LACUNA-100. We compare the proposed technique to SCRUB, a state-of-the-art approach which uses knowledge distillation for unlearning. Across all three datasets, the proposed technique performs as well as, if not better than SCRUB while incurring almost no computational cost.