 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMany-Shot In-Context Learning
Apr 17, 2024



Large language models (LLMs) excel at few-shot in-context learning (ICL) -- learning from a few examples provided in context at inference, without any weight updates. Newly expanded context windows allow us to investigate ICL with hundreds or thousands of examples -- the many-shot regime. Going from few-shot to many-shot, we observe significant performance gains across a wide variety of generative and discriminative tasks. While promising, many-shot ICL can be bottlenecked by the available amount of human-generated examples. To mitigate this limitation, we explore two new settings: Reinforced and Unsupervised ICL. Reinforced ICL uses model-generated chain-of-thought rationales in place of human examples. Unsupervised ICL removes rationales from the prompt altogether, and prompts the model only with domain-specific questions. We find that both Reinforced and Unsupervised ICL can be quite effective in the many-shot regime, particularly on complex reasoning tasks. Finally, we demonstrate that, unlike few-shot learning, many-shot learning is effective at overriding pretraining biases and can learn high-dimensional functions with numerical inputs. Our analysis also reveals the limitations of next-token prediction loss as an indicator of downstream ICL performance.
Guided Evolution with Binary Discriminators for ML Program Search
Feb 08, 2024How to automatically design better machine learning programs is an open problem within AutoML. While evolution has been a popular tool to search for better ML programs, using learning itself to guide the search has been less successful and less understood on harder problems but has the promise to dramatically increase the speed and final performance of the optimization process. We propose guiding evolution with a binary discriminator, trained online to distinguish which program is better given a pair of programs. The discriminator selects better programs without having to perform a costly evaluation and thus speed up the convergence of evolution. Our method can encode a wide variety of ML components including symbolic optimizers, neural architectures, RL loss functions, and symbolic regression equations with the same directed acyclic graph representation. By combining this representation with modern GNNs and an adaptive mutation strategy, we demonstrate our method can speed up evolution across a set of diverse problems including a 3.7x speedup on the symbolic search for ML optimizers and a 4x speedup for RL loss functions.
Beyond Human Data: Scaling Self-Training for Problem-Solving with Language Models
Dec 22, 2023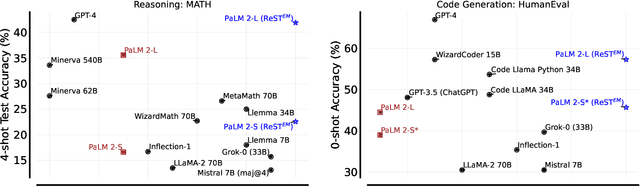
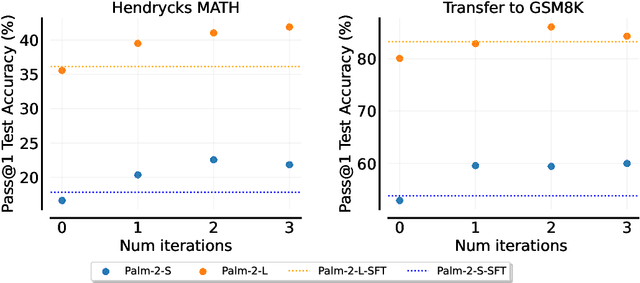
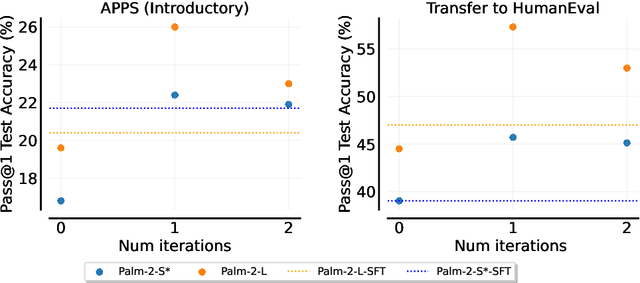
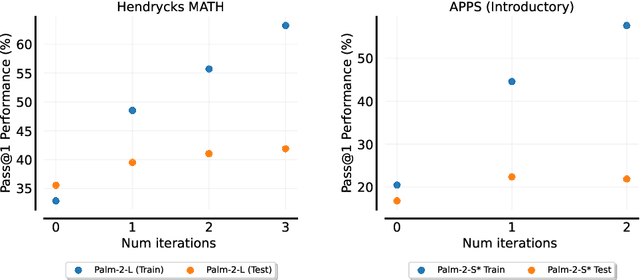
Fine-tuning language models~(LMs) on human-generated data remains a prevalent practice. However, the performance of such models is often limited by the quantity and diversity of high-quality human data. In this paper, we explore whether we can go beyond human data on tasks where we have access to scalar feedback, for example, on math problems where one can verify correctness. To do so, we investigate a simple self-training method based on expectation-maximization, which we call ReST$^{EM}$, where we (1) generate samples from the model and filter them using binary feedback, (2) fine-tune the model on these samples, and (3) repeat this process a few times. Testing on advanced MATH reasoning and APPS coding benchmarks using PaLM-2 models, we find that ReST$^{EM}$ scales favorably with model size and significantly surpasses fine-tuning only on human data. Overall, our findings suggest self-training with feedback can substantially reduce dependence on human-generated data.
Improving Large Language Model Fine-tuning for Solving Math Problems
Oct 16, 2023Despite their success in many natural language tasks, solving math problems remains a significant challenge for large language models (LLMs). A large gap exists between LLMs' pass-at-one and pass-at-N performance in solving math problems, suggesting LLMs might be close to finding correct solutions, motivating our exploration of fine-tuning methods to unlock LLMs' performance. Using the challenging MATH dataset, we investigate three fine-tuning strategies: (1) solution fine-tuning, where we fine-tune to generate a detailed solution for a given math problem; (2) solution-cluster re-ranking, where the LLM is fine-tuned as a solution verifier/evaluator to choose among generated candidate solution clusters; (3) multi-task sequential fine-tuning, which integrates both solution generation and evaluation tasks together efficiently to enhance the LLM performance. With these methods, we present a thorough empirical study on a series of PaLM 2 models and find: (1) The quality and style of the step-by-step solutions used for fine-tuning can make a significant impact on the model performance; (2) While solution re-ranking and majority voting are both effective for improving the model performance when used separately, they can also be used together for an even greater performance boost; (3) Multi-task fine-tuning that sequentially separates the solution generation and evaluation tasks can offer improved performance compared with the solution fine-tuning baseline. Guided by these insights, we design a fine-tuning recipe that yields approximately 58.8% accuracy on the MATH dataset with fine-tuned PaLM 2-L models, an 11.2% accuracy improvement over the few-shot performance of pre-trained PaLM 2-L model with majority voting.
Waymax: An Accelerated, Data-Driven Simulator for Large-Scale Autonomous Driving Research
Oct 12, 2023
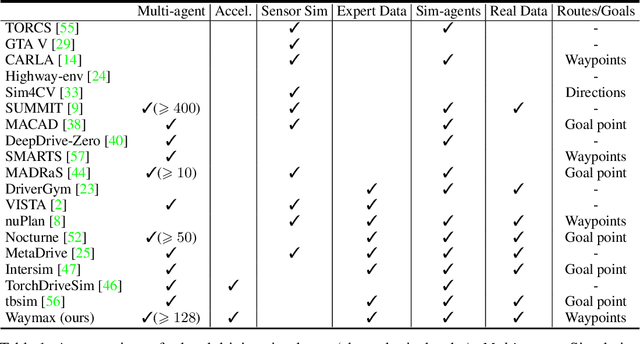
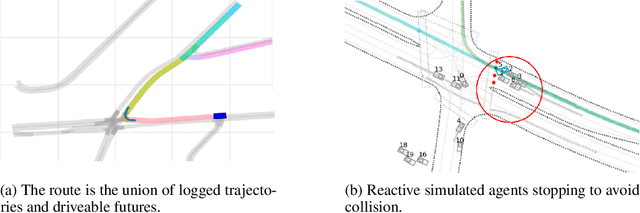
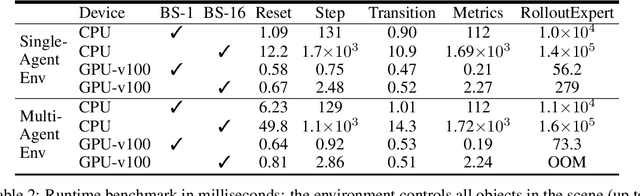
Simulation is an essential tool to develop and benchmark autonomous vehicle planning software in a safe and cost-effective manner. However, realistic simulation requires accurate modeling of nuanced and complex multi-agent interactive behaviors. To address these challenges, we introduce Waymax, a new data-driven simulator for autonomous driving in multi-agent scenes, designed for large-scale simulation and testing. Waymax uses publicly-released, real-world driving data (e.g., the Waymo Open Motion Dataset) to initialize or play back a diverse set of multi-agent simulated scenarios. It runs entirely on hardware accelerators such as TPUs/GPUs and supports in-graph simulation for training, making it suitable for modern large-scale, distributed machine learning workflows. To support online training and evaluation, Waymax includes several learned and hard-coded behavior models that allow for realistic interaction within simulation. To supplement Waymax, we benchmark a suite of popular imitation and reinforcement learning algorithms with ablation studies on different design decisions, where we highlight the effectiveness of routes as guidance for planning agents and the ability of RL to overfit against simulated agents.
Small-scale proxies for large-scale Transformer training instabilities
Sep 25, 2023



Teams that have trained large Transformer-based models have reported training instabilities at large scale that did not appear when training with the same hyperparameters at smaller scales. Although the causes of such instabilities are of scientific interest, the amount of resources required to reproduce them has made investigation difficult. In this work, we seek ways to reproduce and study training stability and instability at smaller scales. First, we focus on two sources of training instability described in previous work: the growth of logits in attention layers (Dehghani et al., 2023) and divergence of the output logits from the log probabilities (Chowdhery et al., 2022). By measuring the relationship between learning rate and loss across scales, we show that these instabilities also appear in small models when training at high learning rates, and that mitigations previously employed at large scales are equally effective in this regime. This prompts us to investigate the extent to which other known optimizer and model interventions influence the sensitivity of the final loss to changes in the learning rate. To this end, we study methods such as warm-up, weight decay, and the $\mu$Param (Yang et al., 2022), and combine techniques to train small models that achieve similar losses across orders of magnitude of learning rate variation. Finally, to conclude our exploration we study two cases where instabilities can be predicted before they emerge by examining the scaling behavior of model activation and gradient norms.
Multi-objective evolution for Generalizable Policy Gradient Algorithms
Apr 08, 2022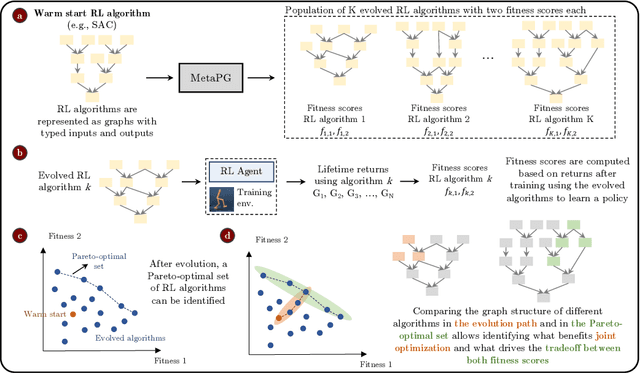
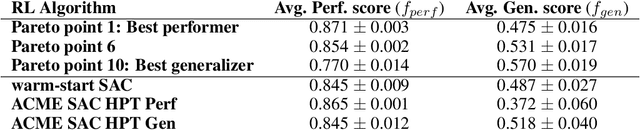
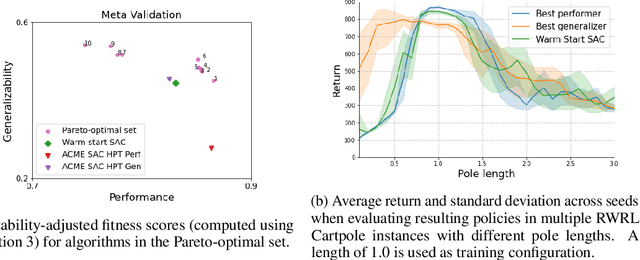
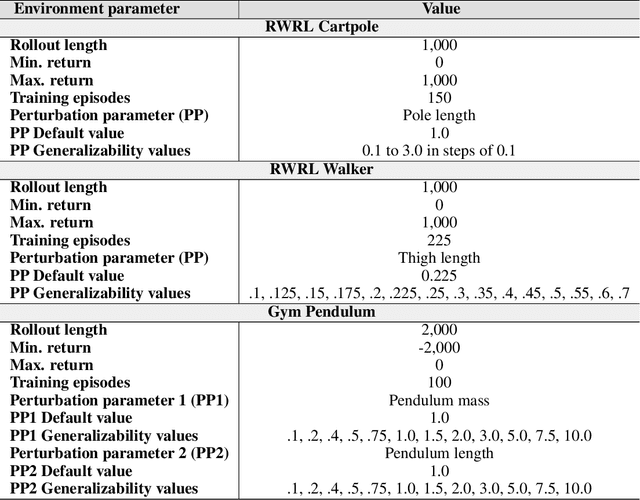
Performance, generalizability, and stability are three Reinforcement Learning (RL) challenges relevant to many practical applications in which they present themselves in combination. Still, state-of-the-art RL algorithms fall short when addressing multiple RL objectives simultaneously and current human-driven design practices might not be well-suited for multi-objective RL. In this paper we present MetaPG, an evolutionary method that discovers new RL algorithms represented as graphs, following a multi-objective search criteria in which different RL objectives are encoded in separate fitness scores. Our findings show that, when using a graph-based implementation of Soft Actor-Critic (SAC) to initialize the population, our method is able to find new algorithms that improve upon SAC's performance and generalizability by 3% and 17%, respectively, and reduce instability up to 65%. In addition, we analyze the graph structure of the best algorithms in the population and offer an interpretation of specific elements that help trading performance for generalizability and vice versa. We validate our findings in three different continuous control tasks: RWRL Cartpole, RWRL Walker, and Gym Pendulum.
Information is Power: Intrinsic Control via Information Capture
Dec 07, 2021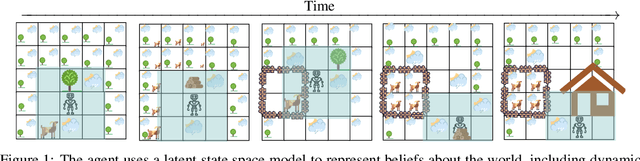


Humans and animals explore their environment and acquire useful skills even in the absence of clear goals, exhibiting intrinsic motivation. The study of intrinsic motivation in artificial agents is concerned with the following question: what is a good general-purpose objective for an agent? We study this question in dynamic partially-observed environments, and argue that a compact and general learning objective is to minimize the entropy of the agent's state visitation estimated using a latent state-space model. This objective induces an agent to both gather information about its environment, corresponding to reducing uncertainty, and to gain control over its environment, corresponding to reducing the unpredictability of future world states. We instantiate this approach as a deep reinforcement learning agent equipped with a deep variational Bayes filter. We find that our agent learns to discover, represent, and exercise control of dynamic objects in a variety of partially-observed environments sensed with visual observations without extrinsic reward.
Evolving Reinforcement Learning Algorithms
Jan 08, 2021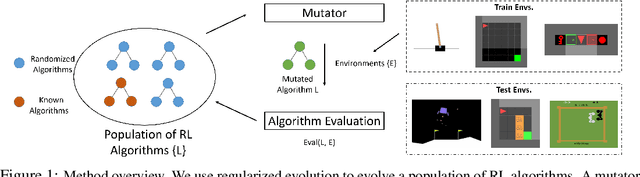
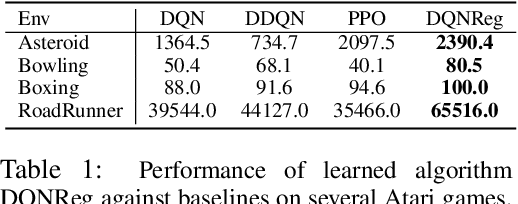
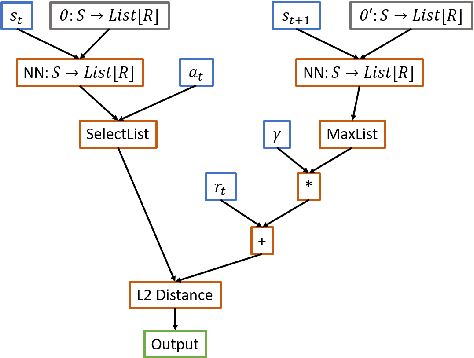
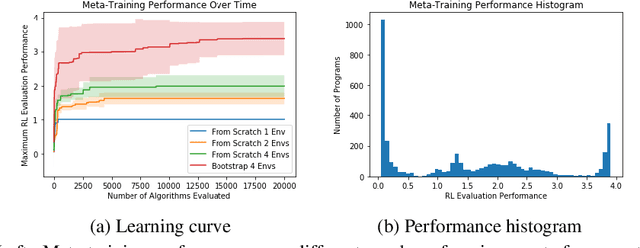
We propose a method for meta-learning reinforcement learning algorithms by searching over the space of computational graphs which compute the loss function for a value-based model-free RL agent to optimize. The learned algorithms are domain-agnostic and can generalize to new environments not seen during training. Our method can both learn from scratch and bootstrap off known existing algorithms, like DQN, enabling interpretable modifications which improve performance. Learning from scratch on simple classical control and gridworld tasks, our method rediscovers the temporal-difference (TD) algorithm. Bootstrapped from DQN, we highlight two learned algorithms which obtain good generalization performance over other classical control tasks, gridworld type tasks, and Atari games. The analysis of the learned algorithm behavior shows resemblance to recently proposed RL algorithms that address overestimation in value-based methods.
Ecological Reinforcement Learning
Jun 22, 2020

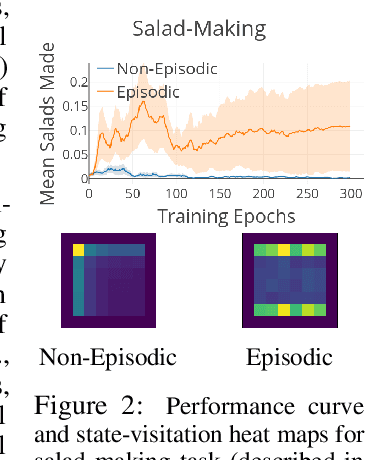

Much of the current work on reinforcement learning studies episodic settings, where the agent is reset between trials to an initial state distribution, often with well-shaped reward functions. Non-episodic settings, where the agent must learn through continuous interaction with the world without resets, and where the agent receives only delayed and sparse reward signals, is substantially more difficult, but arguably more realistic considering real-world environments do not present the learner with a convenient "reset mechanism" and easy reward shaping. In this paper, instead of studying algorithmic improvements that can address such non-episodic and sparse reward settings, we instead study the kinds of environment properties that can make learning under such conditions easier. Understanding how properties of the environment impact the performance of reinforcement learning agents can help us to structure our tasks in ways that make learning tractable. We first discuss what we term "environment shaping" -- modifications to the environment that provide an alternative to reward shaping, and may be easier to implement. We then discuss an even simpler property that we refer to as "dynamism," which describes the degree to which the environment changes independent of the agent's actions and can be measured by environment transition entropy. Surprisingly, we find that even this property can substantially alleviate the challenges associated with non-episodic RL in sparse reward settings. We provide an empirical evaluation on a set of new tasks focused on non-episodic learning with sparse rewards. Through this study, we hope to shift the focus of the community towards analyzing how properties of the environment can affect learning and the ultimate type of behavior that is learned via RL.