 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvSplat: Adversarial Attacks on Feed-Forward Gaussian Splatting Models
Mar 24, 20263D Gaussian Splatting (3DGS) is increasingly recognized as a powerful paradigm for real-time, high-fidelity 3D reconstruction. However, its per-scene optimization pipeline limits scalability and generalization, and prevents efficient inference. Recently emerged feed-forward 3DGS models address these limitations by enabling fast reconstruction from a few input views after large-scale pretraining, without scene-specific optimization. Despite their advantages and strong potential for commercial deployment, the use of neural networks as the backbone also amplifies the risk of adversarial manipulation. In this paper, we introduce AdvSplat, the first systematic study of adversarial attacks on feed-forward 3DGS. We first employ white-box attacks to reveal fundamental vulnerabilities of this model family. We then develop two improved, practically relevant, query-efficient black-box algorithms that optimize pixel-space perturbations via a frequency-domain parameterization: one based on gradient estimation and the other gradient-free, without requiring any access to model internals. Extensive experiments across multiple datasets demonstrate that AdvSplat can significantly disrupt reconstruction results by injecting imperceptible perturbations into the input images. Our findings surface an overlooked yet urgent problem in this domain, and we hope to draw the community's attention to this emerging security and robustness challenge.
Reconstruction Matters: Learning Geometry-Aligned BEV Representation through 3D Gaussian Splatting
Mar 19, 2026Bird's-Eye-View (BEV) perception serves as a cornerstone for autonomous driving, offering a unified spatial representation that fuses surrounding-view images to enable reasoning for various downstream tasks, such as semantic segmentation, 3D object detection, and motion prediction. However, most existing BEV perception frameworks adopt an end-to-end training paradigm, where image features are directly transformed into the BEV space and optimized solely through downstream task supervision. This formulation treats the entire perception process as a black box, often lacking explicit 3D geometric understanding and interpretability, leading to suboptimal performance. In this paper, we claim that an explicit 3D representation matters for accurate BEV perception, and we propose Splat2BEV, a Gaussian Splatting-assisted framework for BEV tasks. Splat2BEV aims to learn BEV feature representations that are both semantically rich and geometrically precise. We first pre-train a Gaussian generator that explicitly reconstructs 3D scenes from multi-view inputs, enabling the generation of geometry-aligned feature representations. These representations are then projected into the BEV space to serve as inputs for downstream tasks. Extensive experiments on nuScenes and argoverse dataset demonstrate that Splat2BEV achieves state-of-the-art performance and validate the effectiveness of incorporating explicit 3D reconstruction into BEV perception.
GSMem: 3D Gaussian Splatting as Persistent Spatial Memory for Zero-Shot Embodied Exploration and Reasoning
Mar 19, 2026Effective embodied exploration requires agents to accumulate and retain spatial knowledge over time. However, existing scene representations, such as discrete scene graphs or static view-based snapshots, lack \textit{post-hoc re-observability}. If an initial observation misses a target, the resulting memory omission is often irrecoverable. To bridge this gap, we propose \textbf{GSMem}, a zero-shot embodied exploration and reasoning framework built upon 3D Gaussian Splatting (3DGS). By explicitly parameterizing continuous geometry and dense appearance, 3DGS serves as a persistent spatial memory that endows the agent with \textit{Spatial Recollection}: the ability to render photorealistic novel views from optimal, previously unoccupied viewpoints. To operationalize this, GSMem employs a retrieval mechanism that simultaneously leverages parallel object-level scene graphs and semantic-level language fields. This complementary design robustly localizes target regions, enabling the agent to ``hallucinate'' optimal views for high-fidelity Vision-Language Model (VLM) reasoning. Furthermore, we introduce a hybrid exploration strategy that combines VLM-driven semantic scoring with a 3DGS-based coverage objective, balancing task-aware exploration with geometric coverage. Extensive experiments on embodied question answering and lifelong navigation demonstrate the robustness and effectiveness of our framework
DefenseSplat: Enhancing the Robustness of 3D Gaussian Splatting via Frequency-Aware Filtering
Feb 22, 20263D Gaussian Splatting (3DGS) has emerged as a powerful paradigm for real-time and high-fidelity 3D reconstruction from posed images. However, recent studies reveal its vulnerability to adversarial corruptions in input views, where imperceptible yet consistent perturbations can drastically degrade rendering quality, increase training and rendering time, and inflate memory usage, even leading to server denial-of-service. In our work, to mitigate this issue, we begin by analyzing the distinct behaviors of adversarial perturbations in the low- and high-frequency components of input images using wavelet transforms. Based on this observation, we design a simple yet effective frequency-aware defense strategy that reconstructs training views by filtering high-frequency noise while preserving low-frequency content. This approach effectively suppresses adversarial artifacts while maintaining the authenticity of the original scene. Notably, it does not significantly impair training on clean data, achieving a desirable trade-off between robustness and performance on clean inputs. Through extensive experiments under a wide range of attack intensities on multiple benchmarks, we demonstrate that our method substantially enhances the robustness of 3DGS without access to clean ground-truth supervision. By highlighting and addressing the overlooked vulnerabilities of 3D Gaussian Splatting, our work paves the way for more robust and secure 3D reconstructions.
UniDrive-WM: Unified Understanding, Planning and Generation World Model For Autonomous Driving
Jan 07, 2026World models have become central to autonomous driving, where accurate scene understanding and future prediction are crucial for safe control. Recent work has explored using vision-language models (VLMs) for planning, yet existing approaches typically treat perception, prediction, and planning as separate modules. We propose UniDrive-WM, a unified VLM-based world model that jointly performs driving-scene understanding, trajectory planning, and trajectory-conditioned future image generation within a single architecture. UniDrive-WM's trajectory planner predicts a future trajectory, which conditions a VLM-based image generator to produce plausible future frames. These predictions provide additional supervisory signals that enhance scene understanding and iteratively refine trajectory generation. We further compare discrete and continuous output representations for future image prediction, analyzing their influence on downstream driving performance. Experiments on the challenging Bench2Drive benchmark show that UniDrive-WM produces high-fidelity future images and improves planning performance by 5.9% in L2 trajectory error and 9.2% in collision rate over the previous best method. These results demonstrate the advantages of tightly integrating VLM-driven reasoning, planning, and generative world modeling for autonomous driving. The project page is available at https://unidrive-wm.github.io/UniDrive-WM .
S4-Driver: Scalable Self-Supervised Driving Multimodal Large Language Modelwith Spatio-Temporal Visual Representation
May 30, 2025

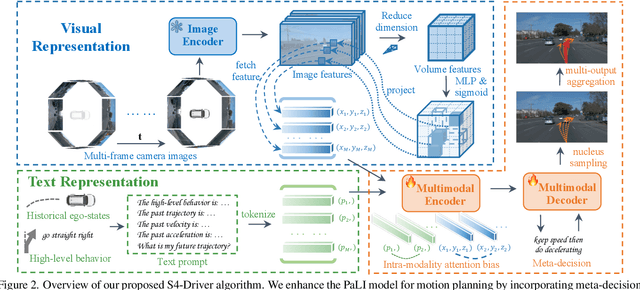

The latest advancements in multi-modal large language models (MLLMs) have spurred a strong renewed interest in end-to-end motion planning approaches for autonomous driving. Many end-to-end approaches rely on human annotations to learn intermediate perception and prediction tasks, while purely self-supervised approaches--which directly learn from sensor inputs to generate planning trajectories without human annotations often underperform the state of the art. We observe a key gap in the input representation space: end-to-end approaches built on MLLMs are often pretrained with reasoning tasks in 2D image space rather than the native 3D space in which autonomous vehicles plan. To this end, we propose S4-Driver, a scalable self-supervised motion planning algorithm with spatio-temporal visual representation, based on the popular PaLI multimodal large language model. S4-Driver uses a novel sparse volume strategy to seamlessly transform the strong visual representation of MLLMs from perspective view to 3D space without the need to finetune the vision encoder. This representation aggregates multi-view and multi-frame visual inputs and enables better prediction of planning trajectories in 3D space. To validate our method, we run experiments on both nuScenes and Waymo Open Motion Dataset (with in-house camera data). Results show that S4-Driver performs favorably against existing supervised multi-task approaches while requiring no human annotations. It also demonstrates great scalability when pretrained on large volumes of unannotated driving logs.
When 'YES' Meets 'BUT': Can Large Models Comprehend Contradictory Humor Through Comparative Reasoning?
Mar 29, 2025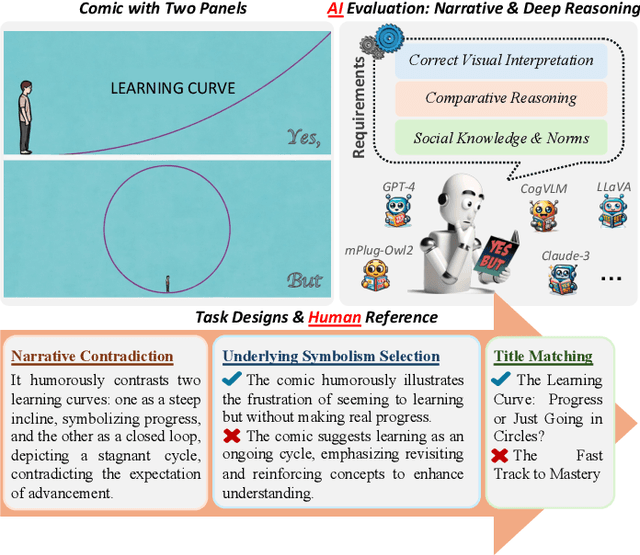



Understanding humor-particularly when it involves complex, contradictory narratives that require comparative reasoning-remains a significant challenge for large vision-language models (VLMs). This limitation hinders AI's ability to engage in human-like reasoning and cultural expression. In this paper, we investigate this challenge through an in-depth analysis of comics that juxtapose panels to create humor through contradictions. We introduce the YesBut (V2), a novel benchmark with 1,262 comic images from diverse multilingual and multicultural contexts, featuring comprehensive annotations that capture various aspects of narrative understanding. Using this benchmark, we systematically evaluate a wide range of VLMs through four complementary tasks spanning from surface content comprehension to deep narrative reasoning, with particular emphasis on comparative reasoning between contradictory elements. Our extensive experiments reveal that even the most advanced models significantly underperform compared to humans, with common failures in visual perception, key element identification, comparative analysis and hallucinations. We further investigate text-based training strategies and social knowledge augmentation methods to enhance model performance. Our findings not only highlight critical weaknesses in VLMs' understanding of cultural and creative expressions but also provide pathways toward developing context-aware models capable of deeper narrative understanding though comparative reasoning.
Segment then Splat: A Unified Approach for 3D Open-Vocabulary Segmentation based on Gaussian Splatting
Mar 28, 2025Open-vocabulary querying in 3D space is crucial for enabling more intelligent perception in applications such as robotics, autonomous systems, and augmented reality. However, most existing methods rely on 2D pixel-level parsing, leading to multi-view inconsistencies and poor 3D object retrieval. Moreover, they are limited to static scenes and struggle with dynamic scenes due to the complexities of motion modeling. In this paper, we propose Segment then Splat, a 3D-aware open vocabulary segmentation approach for both static and dynamic scenes based on Gaussian Splatting. Segment then Splat reverses the long established approach of "segmentation after reconstruction" by dividing Gaussians into distinct object sets before reconstruction. Once the reconstruction is complete, the scene is naturally segmented into individual objects, achieving true 3D segmentation. This approach not only eliminates Gaussian-object misalignment issues in dynamic scenes but also accelerates the optimization process, as it eliminates the need for learning a separate language field. After optimization, a CLIP embedding is assigned to each object to enable open-vocabulary querying. Extensive experiments on various datasets demonstrate the effectiveness of our proposed method in both static and dynamic scenarios.
BARD-GS: Blur-Aware Reconstruction of Dynamic Scenes via Gaussian Splatting
Mar 20, 2025



3D Gaussian Splatting (3DGS) has shown remarkable potential for static scene reconstruction, and recent advancements have extended its application to dynamic scenes. However, the quality of reconstructions depends heavily on high-quality input images and precise camera poses, which are not that trivial to fulfill in real-world scenarios. Capturing dynamic scenes with handheld monocular cameras, for instance, typically involves simultaneous movement of both the camera and objects within a single exposure. This combined motion frequently results in image blur that existing methods cannot adequately handle. To address these challenges, we introduce BARD-GS, a novel approach for robust dynamic scene reconstruction that effectively handles blurry inputs and imprecise camera poses. Our method comprises two main components: 1) camera motion deblurring and 2) object motion deblurring. By explicitly decomposing motion blur into camera motion blur and object motion blur and modeling them separately, we achieve significantly improved rendering results in dynamic regions. In addition, we collect a real-world motion blur dataset of dynamic scenes to evaluate our approach. Extensive experiments demonstrate that BARD-GS effectively reconstructs high-quality dynamic scenes under realistic conditions, significantly outperforming existing methods.
CAUSAL3D: A Comprehensive Benchmark for Causal Learning from Visual Data
Mar 06, 2025True intelligence hinges on the ability to uncover and leverage hidden causal relations. Despite significant progress in AI and computer vision (CV), there remains a lack of benchmarks for assessing models' abilities to infer latent causality from complex visual data. In this paper, we introduce \textsc{\textbf{Causal3D}}, a novel and comprehensive benchmark that integrates structured data (tables) with corresponding visual representations (images) to evaluate causal reasoning. Designed within a systematic framework, Causal3D comprises 19 3D-scene datasets capturing diverse causal relations, views, and backgrounds, enabling evaluations across scenes of varying complexity. We assess multiple state-of-the-art methods, including classical causal discovery, causal representation learning, and large/vision-language models (LLMs/VLMs). Our experiments show that as causal structures grow more complex without prior knowledge, performance declines significantly, highlighting the challenges even advanced methods face in complex causal scenarios. Causal3D serves as a vital resource for advancing causal reasoning in CV and fostering trustworthy AI in critical domains.