 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWOD-E2E: Waymo Open Dataset for End-to-End Driving in Challenging Long-tail Scenarios
Oct 30, 2025Vision-based end-to-end (E2E) driving has garnered significant interest in the research community due to its scalability and synergy with multimodal large language models (MLLMs). However, current E2E driving benchmarks primarily feature nominal scenarios, failing to adequately test the true potential of these systems. Furthermore, existing open-loop evaluation metrics often fall short in capturing the multi-modal nature of driving or effectively evaluating performance in long-tail scenarios. To address these gaps, we introduce the Waymo Open Dataset for End-to-End Driving (WOD-E2E). WOD-E2E contains 4,021 driving segments (approximately 12 hours), specifically curated for challenging long-tail scenarios that that are rare in daily life with an occurring frequency of less than 0.03%. Concretely, each segment in WOD-E2E includes the high-level routing information, ego states, and 360-degree camera views from 8 surrounding cameras. To evaluate the E2E driving performance on these long-tail situations, we propose a novel open-loop evaluation metric: Rater Feedback Score (RFS). Unlike conventional metrics that measure the distance between predicted way points and the logs, RFS measures how closely the predicted trajectory matches rater-annotated trajectory preference labels. We have released rater preference labels for all WOD-E2E validation set segments, while the held out test set labels have been used for the 2025 WOD-E2E Challenge. Through our work, we aim to foster state of the art research into generalizable, robust, and safe end-to-end autonomous driving agents capable of handling complex real-world situations.
CoST: Efficient Collaborative Perception From Unified Spatiotemporal Perspective
Aug 01, 2025Collaborative perception shares information among different agents and helps solving problems that individual agents may face, e.g., occlusions and small sensing range. Prior methods usually separate the multi-agent fusion and multi-time fusion into two consecutive steps. In contrast, this paper proposes an efficient collaborative perception that aggregates the observations from different agents (space) and different times into a unified spatio-temporal space simultanesouly. The unified spatio-temporal space brings two benefits, i.e., efficient feature transmission and superior feature fusion. 1) Efficient feature transmission: each static object yields a single observation in the spatial temporal space, and thus only requires transmission only once (whereas prior methods re-transmit all the object features multiple times). 2) superior feature fusion: merging the multi-agent and multi-time fusion into a unified spatial-temporal aggregation enables a more holistic perspective, thereby enhancing perception performance in challenging scenarios. Consequently, our Collaborative perception with Spatio-temporal Transformer (CoST) gains improvement in both efficiency and accuracy. Notably, CoST is not tied to any specific method and is compatible with a majority of previous methods, enhancing their accuracy while reducing the transmission bandwidth.
S4-Driver: Scalable Self-Supervised Driving Multimodal Large Language Modelwith Spatio-Temporal Visual Representation
May 30, 2025

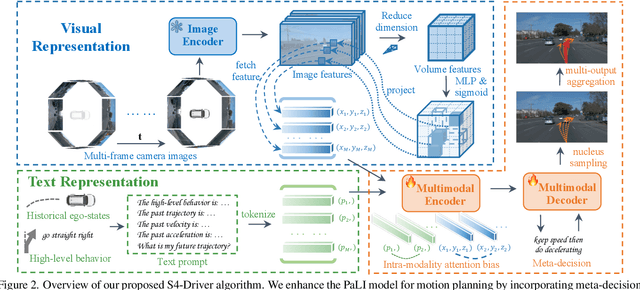

The latest advancements in multi-modal large language models (MLLMs) have spurred a strong renewed interest in end-to-end motion planning approaches for autonomous driving. Many end-to-end approaches rely on human annotations to learn intermediate perception and prediction tasks, while purely self-supervised approaches--which directly learn from sensor inputs to generate planning trajectories without human annotations often underperform the state of the art. We observe a key gap in the input representation space: end-to-end approaches built on MLLMs are often pretrained with reasoning tasks in 2D image space rather than the native 3D space in which autonomous vehicles plan. To this end, we propose S4-Driver, a scalable self-supervised motion planning algorithm with spatio-temporal visual representation, based on the popular PaLI multimodal large language model. S4-Driver uses a novel sparse volume strategy to seamlessly transform the strong visual representation of MLLMs from perspective view to 3D space without the need to finetune the vision encoder. This representation aggregates multi-view and multi-frame visual inputs and enables better prediction of planning trajectories in 3D space. To validate our method, we run experiments on both nuScenes and Waymo Open Motion Dataset (with in-house camera data). Results show that S4-Driver performs favorably against existing supervised multi-task approaches while requiring no human annotations. It also demonstrates great scalability when pretrained on large volumes of unannotated driving logs.
EMMA: End-to-End Multimodal Model for Autonomous Driving
Oct 30, 2024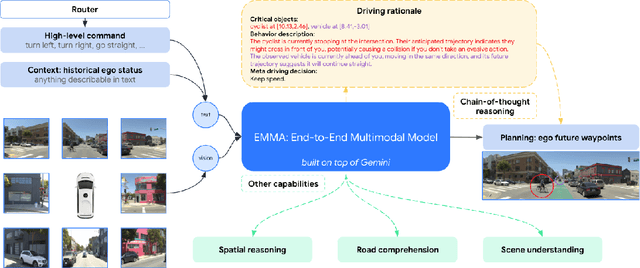
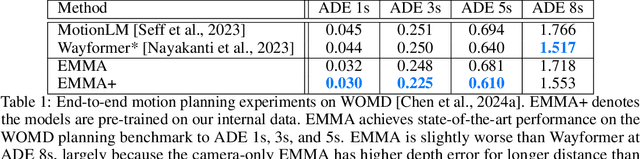
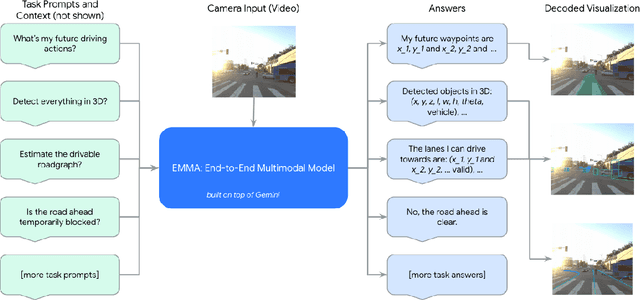
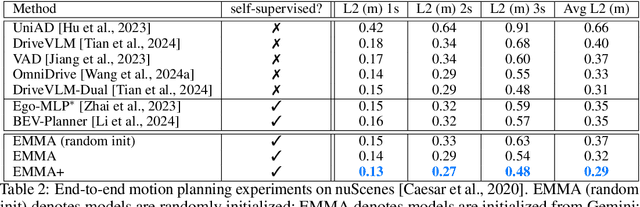
We introduce EMMA, an End-to-end Multimodal Model for Autonomous driving. Built on a multi-modal large language model foundation, EMMA directly maps raw camera sensor data into various driving-specific outputs, including planner trajectories, perception objects, and road graph elements. EMMA maximizes the utility of world knowledge from the pre-trained large language models, by representing all non-sensor inputs (e.g. navigation instructions and ego vehicle status) and outputs (e.g. trajectories and 3D locations) as natural language text. This approach allows EMMA to jointly process various driving tasks in a unified language space, and generate the outputs for each task using task-specific prompts. Empirically, we demonstrate EMMA's effectiveness by achieving state-of-the-art performance in motion planning on nuScenes as well as competitive results on the Waymo Open Motion Dataset (WOMD). EMMA also yields competitive results for camera-primary 3D object detection on the Waymo Open Dataset (WOD). We show that co-training EMMA with planner trajectories, object detection, and road graph tasks yields improvements across all three domains, highlighting EMMA's potential as a generalist model for autonomous driving applications. However, EMMA also exhibits certain limitations: it can process only a small amount of image frames, does not incorporate accurate 3D sensing modalities like LiDAR or radar and is computationally expensive. We hope that our results will inspire further research to mitigate these issues and to further evolve the state of the art in autonomous driving model architectures.
CoMamba: Real-time Cooperative Perception Unlocked with State Space Models
Sep 16, 2024



Cooperative perception systems play a vital role in enhancing the safety and efficiency of vehicular autonomy. Although recent studies have highlighted the efficacy of vehicle-to-everything (V2X) communication techniques in autonomous driving, a significant challenge persists: how to efficiently integrate multiple high-bandwidth features across an expanding network of connected agents such as vehicles and infrastructure. In this paper, we introduce CoMamba, a novel cooperative 3D detection framework designed to leverage state-space models for real-time onboard vehicle perception. Compared to prior state-of-the-art transformer-based models, CoMamba enjoys being a more scalable 3D model using bidirectional state space models, bypassing the quadratic complexity pain-point of attention mechanisms. Through extensive experimentation on V2X/V2V datasets, CoMamba achieves superior performance compared to existing methods while maintaining real-time processing capabilities. The proposed framework not only enhances object detection accuracy but also significantly reduces processing time, making it a promising solution for next-generation cooperative perception systems in intelligent transportation networks.
Light the Night: A Multi-Condition Diffusion Framework for Unpaired Low-Light Enhancement in Autonomous Driving
Apr 07, 2024Vision-centric perception systems for autonomous driving have gained considerable attention recently due to their cost-effectiveness and scalability, especially compared to LiDAR-based systems. However, these systems often struggle in low-light conditions, potentially compromising their performance and safety. To address this, our paper introduces LightDiff, a domain-tailored framework designed to enhance the low-light image quality for autonomous driving applications. Specifically, we employ a multi-condition controlled diffusion model. LightDiff works without any human-collected paired data, leveraging a dynamic data degradation process instead. It incorporates a novel multi-condition adapter that adaptively controls the input weights from different modalities, including depth maps, RGB images, and text captions, to effectively illuminate dark scenes while maintaining context consistency. Furthermore, to align the enhanced images with the detection model's knowledge, LightDiff employs perception-specific scores as rewards to guide the diffusion training process through reinforcement learning. Extensive experiments on the nuScenes datasets demonstrate that LightDiff can significantly improve the performance of several state-of-the-art 3D detectors in night-time conditions while achieving high visual quality scores, highlighting its potential to safeguard autonomous driving.
V2X-DGW: Domain Generalization for Multi-agent Perception under Adverse Weather Conditions
Mar 29, 2024



Current LiDAR-based Vehicle-to-Everything (V2X) multi-agent perception systems have shown the significant success on 3D object detection. While these models perform well in the trained clean weather, they struggle in unseen adverse weather conditions with the real-world domain gap. In this paper, we propose a domain generalization approach, named V2X-DGW, for LiDAR-based 3D object detection on multi-agent perception system under adverse weather conditions. Not only in the clean weather does our research aim to ensure favorable multi-agent performance, but also in the unseen adverse weather conditions by learning only on the clean weather data. To advance research in this area, we have simulated the impact of three prevalent adverse weather conditions on two widely-used multi-agent datasets, resulting in the creation of two novel benchmark datasets: OPV2V-w and V2XSet-w. To this end, we first introduce the Adaptive Weather Augmentation (AWA) to mimic the unseen adverse weather conditions, and then propose two alignments for generalizable representation learning: Trust-region Weather-invariant Alignment (TWA) and Agent-aware Contrastive Alignment (ACA). Extensive experimental results demonstrate that our V2X-DGW achieved improvements in the unseen adverse weather conditions.
V2X-Real: a Largs-Scale Dataset for Vehicle-to-Everything Cooperative Perception
Mar 24, 2024Recent advancements in Vehicle-to-Everything (V2X) technologies have enabled autonomous vehicles to share sensing information to see through occlusions, greatly boosting the perception capability. However, there are no real-world datasets to facilitate the real V2X cooperative perception research -- existing datasets either only support Vehicle-to-Infrastructure cooperation or Vehicle-to-Vehicle cooperation. In this paper, we propose a dataset that has a mixture of multiple vehicles and smart infrastructure simultaneously to facilitate the V2X cooperative perception development with multi-modality sensing data. Our V2X-Real is collected using two connected automated vehicles and two smart infrastructures, which are all equipped with multi-modal sensors including LiDAR sensors and multi-view cameras. The whole dataset contains 33K LiDAR frames and 171K camera data with over 1.2M annotated bounding boxes of 10 categories in very challenging urban scenarios. According to the collaboration mode and ego perspective, we derive four types of datasets for Vehicle-Centric, Infrastructure-Centric, Vehicle-to-Vehicle, and Infrastructure-to-Infrastructure cooperative perception. Comprehensive multi-class multi-agent benchmarks of SOTA cooperative perception methods are provided. The V2X-Real dataset and benchmark codes will be released.
Breaking Data Silos: Cross-Domain Learning for Multi-Agent Perception from Independent Private Sources
Feb 20, 2024



The diverse agents in multi-agent perception systems may be from different companies. Each company might use the identical classic neural network architecture based encoder for feature extraction. However, the data source to train the various agents is independent and private in each company, leading to the Distribution Gap of different private data for training distinct agents in multi-agent perception system. The data silos by the above Distribution Gap could result in a significant performance decline in multi-agent perception. In this paper, we thoroughly examine the impact of the distribution gap on existing multi-agent perception systems. To break the data silos, we introduce the Feature Distribution-aware Aggregation (FDA) framework for cross-domain learning to mitigate the above Distribution Gap in multi-agent perception. FDA comprises two key components: Learnable Feature Compensation Module and Distribution-aware Statistical Consistency Module, both aimed at enhancing intermediate features to minimize the distribution gap among multi-agent features. Intensive experiments on the public OPV2V and V2XSet datasets underscore FDA's effectiveness in point cloud-based 3D object detection, presenting it as an invaluable augmentation to existing multi-agent perception systems.
DUSA: Decoupled Unsupervised Sim2Real Adaptation for Vehicle-to-Everything Collaborative Perception
Oct 12, 2023Vehicle-to-Everything (V2X) collaborative perception is crucial for autonomous driving. However, achieving high-precision V2X perception requires a significant amount of annotated real-world data, which can always be expensive and hard to acquire. Simulated data have raised much attention since they can be massively produced at an extremely low cost. Nevertheless, the significant domain gap between simulated and real-world data, including differences in sensor type, reflectance patterns, and road surroundings, often leads to poor performance of models trained on simulated data when evaluated on real-world data. In addition, there remains a domain gap between real-world collaborative agents, e.g. different types of sensors may be installed on autonomous vehicles and roadside infrastructures with different extrinsics, further increasing the difficulty of sim2real generalization. To take full advantage of simulated data, we present a new unsupervised sim2real domain adaptation method for V2X collaborative detection named Decoupled Unsupervised Sim2Real Adaptation (DUSA). Our new method decouples the V2X collaborative sim2real domain adaptation problem into two sub-problems: sim2real adaptation and inter-agent adaptation. For sim2real adaptation, we design a Location-adaptive Sim2Real Adapter (LSA) module to adaptively aggregate features from critical locations of the feature map and align the features between simulated data and real-world data via a sim/real discriminator on the aggregated global feature. For inter-agent adaptation, we further devise a Confidence-aware Inter-agent Adapter (CIA) module to align the fine-grained features from heterogeneous agents under the guidance of agent-wise confidence maps. Experiments demonstrate the effectiveness of the proposed DUSA approach on unsupervised sim2real adaptation from the simulated V2XSet dataset to the real-world DAIR-V2X-C dataset.