 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Multi-agent and Single-agent Perception from Cooperative Views
Apr 07, 2026The LiDAR-based multi-agent and single-agent perception has shown promising performance in environmental understanding for robots and automated vehicles. However, there is no existing method that simultaneously solves both multi-agent and single-agent perception in an unsupervised way. By sharing sensor data between multiple agents via communication, this paper discovers two key insights: 1) Improved point cloud density after the data sharing from cooperative views could benefit unsupervised object classification, 2) Cooperative view of multiple agents can be used as unsupervised guidance for the 3D object detection in the single view. Based on these two discovered insights, we propose an Unsupervised Multi-agent and Single-agent (UMS) perception framework that leverages multi-agent cooperation without human annotations to simultaneously solve multi-agent and single-agent perception. UMS combines a learning-based Proposal Purifying Filter to better classify the candidate proposals after multi-agent point cloud density cooperation, followed by a Progressive Proposal Stabilizing module to yield reliable pseudo labels by the easy-to-hard curriculum learning. Furthermore, we design a Cross-View Consensus Learning to use multi-agent cooperative view to guide detection in single-agent view. Experimental results on two public datasets V2V4Real and OPV2V show that our UMS method achieved significantly higher 3D detection performance than the state-of-the-art methods on both multi-agent and single-agent perception tasks in an unsupervised setting.
DarkDriving: A Real-World Day and Night Aligned Dataset for Autonomous Driving in the Dark Environment
Mar 18, 2026The low-light conditions are challenging to the vision-centric perception systems for autonomous driving in the dark environment. In this paper, we propose a new benchmark dataset (named DarkDriving) to investigate the low-light enhancement for autonomous driving. The existing real-world low-light enhancement benchmark datasets can be collected by controlling various exposures only in small-ranges and static scenes. The dark images of the current nighttime driving datasets do not have the precisely aligned daytime counterparts. The extreme difficulty to collect a real-world day and night aligned dataset in the dynamic driving scenes significantly limited the research in this area. With a proposed automatic day-night Trajectory Tracking based Pose Matching (TTPM) method in a large real-world closed driving test field (area: 69 acres), we collected the first real-world day and night aligned dataset for autonomous driving in the dark environment. The DarkDriving dataset has 9,538 day and night image pairs precisely aligned in location and spatial contents, whose alignment error is in just several centimeters. For each pair, we also manually label the object 2D bounding boxes. DarkDriving introduces four perception related tasks, including low-light enhancement, generalized low-light enhancement, and low-light enhancement for 2D detection and 3D detection of autonomous driving in the dark environment. The experimental results show that our DarkDriving dataset provides a comprehensive benchmark for evaluating low-light enhancement for autonomous driving and it can also be generalized to enhance dark images and promote detection in some other low-light driving environment, such as nuScenes.
Video2LoRA: Unified Semantic-Controlled Video Generation via Per-Reference-Video LoRA
Mar 10, 2026Achieving semantic alignment across diverse video generation conditions remains a significant challenge. Methods that rely on explicit structural guidance often enforce rigid spatial constraints that limit semantic flexibility, whereas models tailored for individual control types lack interoperability and adaptability. These design bottlenecks hinder progress toward flexible and efficient semantic video generation. To address this, we propose Video2LoRA, a scalable and generalizable framework for semantic-controlled video generation that conditions on a reference video. Video2LoRA employs a lightweight hypernetwork to predict personalized LoRA weights for each semantic input, which are combined with auxiliary matrices to form adaptive LoRA modules integrated into a frozen diffusion backbone. This design enables the model to generate videos consistent with the reference semantics while preserving key style and content variations, eliminating the need for any per-condition training. Notably, the final model weights less than 150MB, making it highly efficient for storage and deployment. Video2LoRA achieves coherent, semantically aligned generation across diverse conditions and exhibits strong zero-shot generalization to unseen semantics.
VFXMaster: Unlocking Dynamic Visual Effect Generation via In-Context Learning
Oct 29, 2025Visual effects (VFX) are crucial to the expressive power of digital media, yet their creation remains a major challenge for generative AI. Prevailing methods often rely on the one-LoRA-per-effect paradigm, which is resource-intensive and fundamentally incapable of generalizing to unseen effects, thus limiting scalability and creation. To address this challenge, we introduce VFXMaster, the first unified, reference-based framework for VFX video generation. It recasts effect generation as an in-context learning task, enabling it to reproduce diverse dynamic effects from a reference video onto target content. In addition, it demonstrates remarkable generalization to unseen effect categories. Specifically, we design an in-context conditioning strategy that prompts the model with a reference example. An in-context attention mask is designed to precisely decouple and inject the essential effect attributes, allowing a single unified model to master the effect imitation without information leakage. In addition, we propose an efficient one-shot effect adaptation mechanism to boost generalization capability on tough unseen effects from a single user-provided video rapidly. Extensive experiments demonstrate that our method effectively imitates various categories of effect information and exhibits outstanding generalization to out-of-domain effects. To foster future research, we will release our code, models, and a comprehensive dataset to the community.
Towards Physically Plausible Video Generation via VLM Planning
Mar 30, 2025Video diffusion models (VDMs) have advanced significantly in recent years, enabling the generation of highly realistic videos and drawing the attention of the community in their potential as world simulators. However, despite their capabilities, VDMs often fail to produce physically plausible videos due to an inherent lack of understanding of physics, resulting in incorrect dynamics and event sequences. To address this limitation, we propose a novel two-stage image-to-video generation framework that explicitly incorporates physics. In the first stage, we employ a Vision Language Model (VLM) as a coarse-grained motion planner, integrating chain-of-thought and physics-aware reasoning to predict a rough motion trajectories/changes that approximate real-world physical dynamics while ensuring the inter-frame consistency. In the second stage, we use the predicted motion trajectories/changes to guide the video generation of a VDM. As the predicted motion trajectories/changes are rough, noise is added during inference to provide freedom to the VDM in generating motion with more fine details. Extensive experimental results demonstrate that our framework can produce physically plausible motion, and comparative evaluations highlight the notable superiority of our approach over existing methods. More video results are available on our Project Page: https://madaoer.github.io/projects/physically_plausible_video_generation.
V2X-DG: Domain Generalization for Vehicle-to-Everything Cooperative Perception
Mar 19, 2025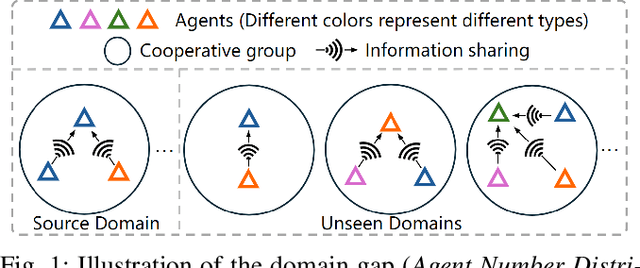
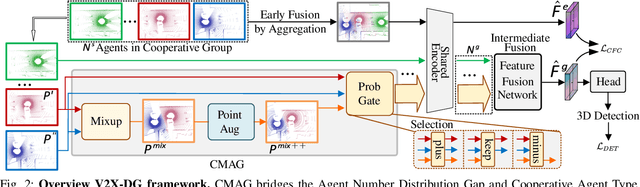
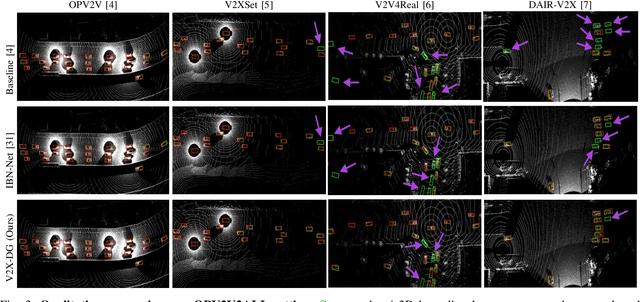

LiDAR-based Vehicle-to-Everything (V2X) cooperative perception has demonstrated its impact on the safety and effectiveness of autonomous driving. Since current cooperative perception algorithms are trained and tested on the same dataset, the generalization ability of cooperative perception systems remains underexplored. This paper is the first work to study the Domain Generalization problem of LiDAR-based V2X cooperative perception (V2X-DG) for 3D detection based on four widely-used open source datasets: OPV2V, V2XSet, V2V4Real and DAIR-V2X. Our research seeks to sustain high performance not only within the source domain but also across other unseen domains, achieved solely through training on source domain. To this end, we propose Cooperative Mixup Augmentation based Generalization (CMAG) to improve the model generalization capability by simulating the unseen cooperation, which is designed compactly for the domain gaps in cooperative perception. Furthermore, we propose a constraint for the regularization of the robust generalized feature representation learning: Cooperation Feature Consistency (CFC), which aligns the intermediately fused features of the generalized cooperation by CMAG and the early fused features of the original cooperation in source domain. Extensive experiments demonstrate that our approach achieves significant performance gains when generalizing to other unseen datasets while it also maintains strong performance on the source dataset.
CoMamba: Real-time Cooperative Perception Unlocked with State Space Models
Sep 16, 2024



Cooperative perception systems play a vital role in enhancing the safety and efficiency of vehicular autonomy. Although recent studies have highlighted the efficacy of vehicle-to-everything (V2X) communication techniques in autonomous driving, a significant challenge persists: how to efficiently integrate multiple high-bandwidth features across an expanding network of connected agents such as vehicles and infrastructure. In this paper, we introduce CoMamba, a novel cooperative 3D detection framework designed to leverage state-space models for real-time onboard vehicle perception. Compared to prior state-of-the-art transformer-based models, CoMamba enjoys being a more scalable 3D model using bidirectional state space models, bypassing the quadratic complexity pain-point of attention mechanisms. Through extensive experimentation on V2X/V2V datasets, CoMamba achieves superior performance compared to existing methods while maintaining real-time processing capabilities. The proposed framework not only enhances object detection accuracy but also significantly reduces processing time, making it a promising solution for next-generation cooperative perception systems in intelligent transportation networks.
CharacterFactory: Sampling Consistent Characters with GANs for Diffusion Models
Apr 27, 2024



Recent advances in text-to-image models have opened new frontiers in human-centric generation. However, these models cannot be directly employed to generate images with consistent newly coined identities. In this work, we propose CharacterFactory, a framework that allows sampling new characters with consistent identities in the latent space of GANs for diffusion models. More specifically, we consider the word embeddings of celeb names as ground truths for the identity-consistent generation task and train a GAN model to learn the mapping from a latent space to the celeb embedding space. In addition, we design a context-consistent loss to ensure that the generated identity embeddings can produce identity-consistent images in various contexts. Remarkably, the whole model only takes 10 minutes for training, and can sample infinite characters end-to-end during inference. Extensive experiments demonstrate excellent performance of the proposed CharacterFactory on character creation in terms of identity consistency and editability. Furthermore, the generated characters can be seamlessly combined with the off-the-shelf image/video/3D diffusion models. We believe that the proposed CharacterFactory is an important step for identity-consistent character generation. Project page is available at: https://qinghew.github.io/CharacterFactory/.
Light the Night: A Multi-Condition Diffusion Framework for Unpaired Low-Light Enhancement in Autonomous Driving
Apr 07, 2024Vision-centric perception systems for autonomous driving have gained considerable attention recently due to their cost-effectiveness and scalability, especially compared to LiDAR-based systems. However, these systems often struggle in low-light conditions, potentially compromising their performance and safety. To address this, our paper introduces LightDiff, a domain-tailored framework designed to enhance the low-light image quality for autonomous driving applications. Specifically, we employ a multi-condition controlled diffusion model. LightDiff works without any human-collected paired data, leveraging a dynamic data degradation process instead. It incorporates a novel multi-condition adapter that adaptively controls the input weights from different modalities, including depth maps, RGB images, and text captions, to effectively illuminate dark scenes while maintaining context consistency. Furthermore, to align the enhanced images with the detection model's knowledge, LightDiff employs perception-specific scores as rewards to guide the diffusion training process through reinforcement learning. Extensive experiments on the nuScenes datasets demonstrate that LightDiff can significantly improve the performance of several state-of-the-art 3D detectors in night-time conditions while achieving high visual quality scores, highlighting its potential to safeguard autonomous driving.
V2X-DGW: Domain Generalization for Multi-agent Perception under Adverse Weather Conditions
Mar 29, 2024



Current LiDAR-based Vehicle-to-Everything (V2X) multi-agent perception systems have shown the significant success on 3D object detection. While these models perform well in the trained clean weather, they struggle in unseen adverse weather conditions with the real-world domain gap. In this paper, we propose a domain generalization approach, named V2X-DGW, for LiDAR-based 3D object detection on multi-agent perception system under adverse weather conditions. Not only in the clean weather does our research aim to ensure favorable multi-agent performance, but also in the unseen adverse weather conditions by learning only on the clean weather data. To advance research in this area, we have simulated the impact of three prevalent adverse weather conditions on two widely-used multi-agent datasets, resulting in the creation of two novel benchmark datasets: OPV2V-w and V2XSet-w. To this end, we first introduce the Adaptive Weather Augmentation (AWA) to mimic the unseen adverse weather conditions, and then propose two alignments for generalizable representation learning: Trust-region Weather-invariant Alignment (TWA) and Agent-aware Contrastive Alignment (ACA). Extensive experimental results demonstrate that our V2X-DGW achieved improvements in the unseen adverse weather conditions.