 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeV2X-DG: Domain Generalization for Vehicle-to-Everything Cooperative Perception
Mar 19, 2025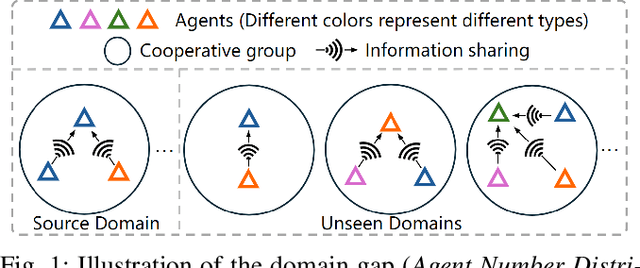
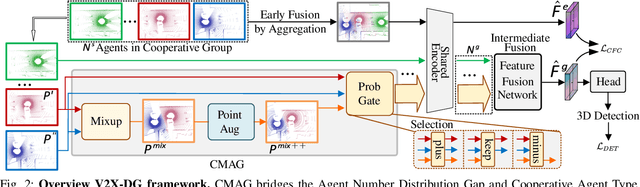
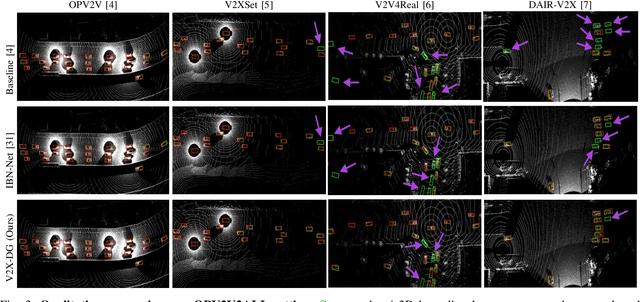

LiDAR-based Vehicle-to-Everything (V2X) cooperative perception has demonstrated its impact on the safety and effectiveness of autonomous driving. Since current cooperative perception algorithms are trained and tested on the same dataset, the generalization ability of cooperative perception systems remains underexplored. This paper is the first work to study the Domain Generalization problem of LiDAR-based V2X cooperative perception (V2X-DG) for 3D detection based on four widely-used open source datasets: OPV2V, V2XSet, V2V4Real and DAIR-V2X. Our research seeks to sustain high performance not only within the source domain but also across other unseen domains, achieved solely through training on source domain. To this end, we propose Cooperative Mixup Augmentation based Generalization (CMAG) to improve the model generalization capability by simulating the unseen cooperation, which is designed compactly for the domain gaps in cooperative perception. Furthermore, we propose a constraint for the regularization of the robust generalized feature representation learning: Cooperation Feature Consistency (CFC), which aligns the intermediately fused features of the generalized cooperation by CMAG and the early fused features of the original cooperation in source domain. Extensive experiments demonstrate that our approach achieves significant performance gains when generalizing to other unseen datasets while it also maintains strong performance on the source dataset.
Specialized Foundation Models Struggle to Beat Supervised Baselines
Nov 05, 2024



Following its success for vision and text, the "foundation model" (FM) paradigm -- pretraining large models on massive data, then fine-tuning on target tasks -- has rapidly expanded to domains in the sciences, engineering, healthcare, and beyond. Has this achieved what the original FMs accomplished, i.e. the supplanting of traditional supervised learning in their domains? To answer we look at three modalities -- genomics, satellite imaging, and time series -- with multiple recent FMs and compare them to a standard supervised learning workflow: model development, hyperparameter tuning, and training, all using only data from the target task. Across these three specialized domains, we find that it is consistently possible to train simple supervised models -- no more complicated than a lightly modified wide ResNet or UNet -- that match or even outperform the latest foundation models. Our work demonstrates that the benefits of large-scale pretraining have yet to be realized in many specialized areas, reinforces the need to compare new FMs to strong, well-tuned baselines, and introduces two new, easy-to-use, open-source, and automated workflows for doing so.