 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEasyVFX: Frequency-Driven Decoupling for Resource-Efficient VFX Generation
May 21, 2026Generating high-fidelity visual effects (VFX) typically demands massive datasets and prohibitive computational power due to the intricate coupling of spatial textures and temporal dynamics. In this paper, we introduce EasyVFX, a resource-efficient framework that achieves realistic VFX synthesis under stringent constraints. Our core philosophy lies in frequency-domain decomposition: we observe that the complexity of VFX can be significantly mitigated by decoupling high-frequency components, which represent intricate spatial appearances, from low-frequency components that encapsulate global motion dynamics. This spectral disentanglement transforms a high-dimensional learning problem into manageable sub-tasks, thereby lowering the optimization barrier and reducing data dependency. Building upon this insight, we propose a two-stage training paradigm. First, we design a Frequency-aware Mixture-of-Experts (Freq-MoE) architecture. By utilizing a soft routing mechanism, our model assigns specialized experts to distinct spectral bands, enabling them to cultivate robust priors for appearance and motion dynamics. This specialization allows the model to acquire foundational VFX knowledge with fewer GPU resources. Second, we introduce a Test-Time Training strategy powered by a novel Frequency-constraint Loss. This allows the pre-trained model to swiftly adapt to specific, unseen effects through localized optimizations, requiring only about 100 steps on a single GPU. Experimental results demonstrate that EasyVFX produces structurally consistent and visually stunning effects, proving that frequency-aware learning is a key catalyst for democratizing professional-grade VFX.
Group Editing : Edit Multiple Images in One Go
Mar 25, 2026In this paper, we tackle the problem of performing consistent and unified modifications across a set of related images. This task is particularly challenging because these images may vary significantly in pose, viewpoint, and spatial layout. Achieving coherent edits requires establishing reliable correspondences across the images, so that modifications can be applied accurately to semantically aligned regions. To address this, we propose GroupEditing, a novel framework that builds both explicit and implicit relationships among images within a group. On the explicit side, we extract geometric correspondences using VGGT, which provides spatial alignment based on visual features. On the implicit side, we reformulate the image group as a pseudo-video and leverage the temporal coherence priors learned by pre-trained video models to capture latent relationships. To effectively fuse these two types of correspondences, we inject the explicit geometric cues from VGGT into the video model through a novel fusion mechanism. To support large-scale training, we construct GroupEditData, a new dataset containing high-quality masks and detailed captions for numerous image groups. Furthermore, to ensure identity preservation during editing, we introduce an alignment-enhanced RoPE module, which improves the model's ability to maintain consistent appearance across multiple images. Finally, we present GroupEditBench, a dedicated benchmark designed to evaluate the effectiveness of group-level image editing. Extensive experiments demonstrate that GroupEditing significantly outperforms existing methods in terms of visual quality, cross-view consistency, and semantic alignment.
Know3D: Prompting 3D Generation with Knowledge from Vision-Language Models
Mar 24, 2026Recent advances in 3D generation have improved the fidelity and geometric details of synthesized 3D assets. However, due to the inherent ambiguity of single-view observations and the lack of robust global structural priors caused by limited 3D training data, the unseen regions generated by existing models are often stochastic and difficult to control, which may sometimes fail to align with user intentions or produce implausible geometries. In this paper, we propose Know3D, a novel framework that incorporates rich knowledge from multimodal large language models into 3D generative processes via latent hidden-state injection, enabling language-controllable generation of the back-view for 3D assets. We utilize a VLM-diffusion-based model, where the VLM is responsible for semantic understanding and guidance. The diffusion model acts as a bridge that transfers semantic knowledge from the VLM to the 3D generation model. In this way, we successfully bridge the gap between abstract textual instructions and the geometric reconstruction of unobserved regions, transforming the traditionally stochastic back-view hallucination into a semantically controllable process, demonstrating a promising direction for future 3D generation models.
Video2LoRA: Unified Semantic-Controlled Video Generation via Per-Reference-Video LoRA
Mar 10, 2026Achieving semantic alignment across diverse video generation conditions remains a significant challenge. Methods that rely on explicit structural guidance often enforce rigid spatial constraints that limit semantic flexibility, whereas models tailored for individual control types lack interoperability and adaptability. These design bottlenecks hinder progress toward flexible and efficient semantic video generation. To address this, we propose Video2LoRA, a scalable and generalizable framework for semantic-controlled video generation that conditions on a reference video. Video2LoRA employs a lightweight hypernetwork to predict personalized LoRA weights for each semantic input, which are combined with auxiliary matrices to form adaptive LoRA modules integrated into a frozen diffusion backbone. This design enables the model to generate videos consistent with the reference semantics while preserving key style and content variations, eliminating the need for any per-condition training. Notably, the final model weights less than 150MB, making it highly efficient for storage and deployment. Video2LoRA achieves coherent, semantically aligned generation across diverse conditions and exhibits strong zero-shot generalization to unseen semantics.
SemanticGen: Video Generation in Semantic Space
Dec 24, 2025

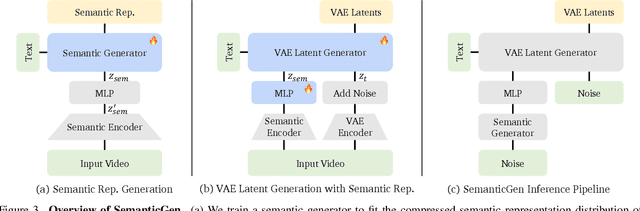

State-of-the-art video generative models typically learn the distribution of video latents in the VAE space and map them to pixels using a VAE decoder. While this approach can generate high-quality videos, it suffers from slow convergence and is computationally expensive when generating long videos. In this paper, we introduce SemanticGen, a novel solution to address these limitations by generating videos in the semantic space. Our main insight is that, due to the inherent redundancy in videos, the generation process should begin in a compact, high-level semantic space for global planning, followed by the addition of high-frequency details, rather than directly modeling a vast set of low-level video tokens using bi-directional attention. SemanticGen adopts a two-stage generation process. In the first stage, a diffusion model generates compact semantic video features, which define the global layout of the video. In the second stage, another diffusion model generates VAE latents conditioned on these semantic features to produce the final output. We observe that generation in the semantic space leads to faster convergence compared to the VAE latent space. Our method is also effective and computationally efficient when extended to long video generation. Extensive experiments demonstrate that SemanticGen produces high-quality videos and outperforms state-of-the-art approaches and strong baselines.
RelightMaster: Precise Video Relighting with Multi-plane Light Images
Nov 09, 2025Recent advances in diffusion models enable high-quality video generation and editing, but precise relighting with consistent video contents, which is critical for shaping scene atmosphere and viewer attention, remains unexplored. Mainstream text-to-video (T2V) models lack fine-grained lighting control due to text's inherent limitation in describing lighting details and insufficient pre-training on lighting-related prompts. Additionally, constructing high-quality relighting training data is challenging, as real-world controllable lighting data is scarce. To address these issues, we propose RelightMaster, a novel framework for accurate and controllable video relighting. First, we build RelightVideo, the first dataset with identical dynamic content under varying precise lighting conditions based on the Unreal Engine. Then, we introduce Multi-plane Light Image (MPLI), a novel visual prompt inspired by Multi-Plane Image (MPI). MPLI models lighting via K depth-aligned planes, representing 3D light source positions, intensities, and colors while supporting multi-source scenarios and generalizing to unseen light setups. Third, we design a Light Image Adapter that seamlessly injects MPLI into pre-trained Video Diffusion Transformers (DiT): it compresses MPLI via a pre-trained Video VAE and injects latent light features into DiT blocks, leveraging the base model's generative prior without catastrophic forgetting. Experiments show that RelightMaster generates physically plausible lighting and shadows and preserves original scene content. Demos are available at https://wkbian.github.io/Projects/RelightMaster/.
VFXMaster: Unlocking Dynamic Visual Effect Generation via In-Context Learning
Oct 29, 2025Visual effects (VFX) are crucial to the expressive power of digital media, yet their creation remains a major challenge for generative AI. Prevailing methods often rely on the one-LoRA-per-effect paradigm, which is resource-intensive and fundamentally incapable of generalizing to unseen effects, thus limiting scalability and creation. To address this challenge, we introduce VFXMaster, the first unified, reference-based framework for VFX video generation. It recasts effect generation as an in-context learning task, enabling it to reproduce diverse dynamic effects from a reference video onto target content. In addition, it demonstrates remarkable generalization to unseen effect categories. Specifically, we design an in-context conditioning strategy that prompts the model with a reference example. An in-context attention mask is designed to precisely decouple and inject the essential effect attributes, allowing a single unified model to master the effect imitation without information leakage. In addition, we propose an efficient one-shot effect adaptation mechanism to boost generalization capability on tough unseen effects from a single user-provided video rapidly. Extensive experiments demonstrate that our method effectively imitates various categories of effect information and exhibits outstanding generalization to out-of-domain effects. To foster future research, we will release our code, models, and a comprehensive dataset to the community.
CineMaster: A 3D-Aware and Controllable Framework for Cinematic Text-to-Video Generation
Feb 12, 2025In this work, we present CineMaster, a novel framework for 3D-aware and controllable text-to-video generation. Our goal is to empower users with comparable controllability as professional film directors: precise placement of objects within the scene, flexible manipulation of both objects and camera in 3D space, and intuitive layout control over the rendered frames. To achieve this, CineMaster operates in two stages. In the first stage, we design an interactive workflow that allows users to intuitively construct 3D-aware conditional signals by positioning object bounding boxes and defining camera movements within the 3D space. In the second stage, these control signals--comprising rendered depth maps, camera trajectories and object class labels--serve as the guidance for a text-to-video diffusion model, ensuring to generate the user-intended video content. Furthermore, to overcome the scarcity of in-the-wild datasets with 3D object motion and camera pose annotations, we carefully establish an automated data annotation pipeline that extracts 3D bounding boxes and camera trajectories from large-scale video data. Extensive qualitative and quantitative experiments demonstrate that CineMaster significantly outperforms existing methods and implements prominent 3D-aware text-to-video generation. Project page: https://cinemaster-dev.github.io/.
MoTrans: Customized Motion Transfer with Text-driven Video Diffusion Models
Dec 02, 2024



Existing pretrained text-to-video (T2V) models have demonstrated impressive abilities in generating realistic videos with basic motion or camera movement. However, these models exhibit significant limitations when generating intricate, human-centric motions. Current efforts primarily focus on fine-tuning models on a small set of videos containing a specific motion. They often fail to effectively decouple motion and the appearance in the limited reference videos, thereby weakening the modeling capability of motion patterns. To this end, we propose MoTrans, a customized motion transfer method enabling video generation of similar motion in new context. Specifically, we introduce a multimodal large language model (MLLM)-based recaptioner to expand the initial prompt to focus more on appearance and an appearance injection module to adapt appearance prior from video frames to the motion modeling process. These complementary multimodal representations from recaptioned prompt and video frames promote the modeling of appearance and facilitate the decoupling of appearance and motion. In addition, we devise a motion-specific embedding for further enhancing the modeling of the specific motion. Experimental results demonstrate that our method effectively learns specific motion pattern from singular or multiple reference videos, performing favorably against existing methods in customized video generation.
CharacterFactory: Sampling Consistent Characters with GANs for Diffusion Models
Apr 27, 2024



Recent advances in text-to-image models have opened new frontiers in human-centric generation. However, these models cannot be directly employed to generate images with consistent newly coined identities. In this work, we propose CharacterFactory, a framework that allows sampling new characters with consistent identities in the latent space of GANs for diffusion models. More specifically, we consider the word embeddings of celeb names as ground truths for the identity-consistent generation task and train a GAN model to learn the mapping from a latent space to the celeb embedding space. In addition, we design a context-consistent loss to ensure that the generated identity embeddings can produce identity-consistent images in various contexts. Remarkably, the whole model only takes 10 minutes for training, and can sample infinite characters end-to-end during inference. Extensive experiments demonstrate excellent performance of the proposed CharacterFactory on character creation in terms of identity consistency and editability. Furthermore, the generated characters can be seamlessly combined with the off-the-shelf image/video/3D diffusion models. We believe that the proposed CharacterFactory is an important step for identity-consistent character generation. Project page is available at: https://qinghew.github.io/CharacterFactory/.