 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDreamID: High-Fidelity and Fast diffusion-based Face Swapping via Triplet ID Group Learning
Apr 20, 2025In this paper, we introduce DreamID, a diffusion-based face swapping model that achieves high levels of ID similarity, attribute preservation, image fidelity, and fast inference speed. Unlike the typical face swapping training process, which often relies on implicit supervision and struggles to achieve satisfactory results. DreamID establishes explicit supervision for face swapping by constructing Triplet ID Group data, significantly enhancing identity similarity and attribute preservation. The iterative nature of diffusion models poses challenges for utilizing efficient image-space loss functions, as performing time-consuming multi-step sampling to obtain the generated image during training is impractical. To address this issue, we leverage the accelerated diffusion model SD Turbo, reducing the inference steps to a single iteration, enabling efficient pixel-level end-to-end training with explicit Triplet ID Group supervision. Additionally, we propose an improved diffusion-based model architecture comprising SwapNet, FaceNet, and ID Adapter. This robust architecture fully unlocks the power of the Triplet ID Group explicit supervision. Finally, to further extend our method, we explicitly modify the Triplet ID Group data during training to fine-tune and preserve specific attributes, such as glasses and face shape. Extensive experiments demonstrate that DreamID outperforms state-of-the-art methods in terms of identity similarity, pose and expression preservation, and image fidelity. Overall, DreamID achieves high-quality face swapping results at 512*512 resolution in just 0.6 seconds and performs exceptionally well in challenging scenarios such as complex lighting, large angles, and occlusions.
Customize Your Own Paired Data via Few-shot Way
May 21, 2024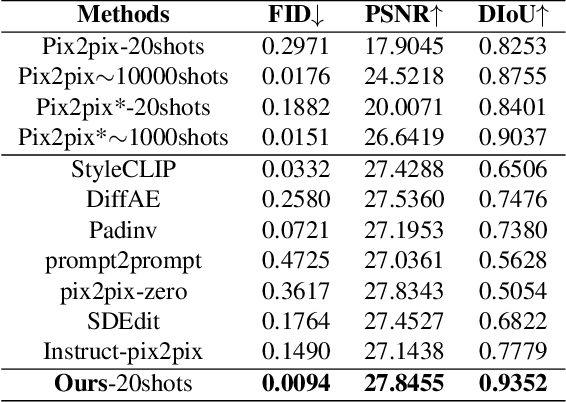
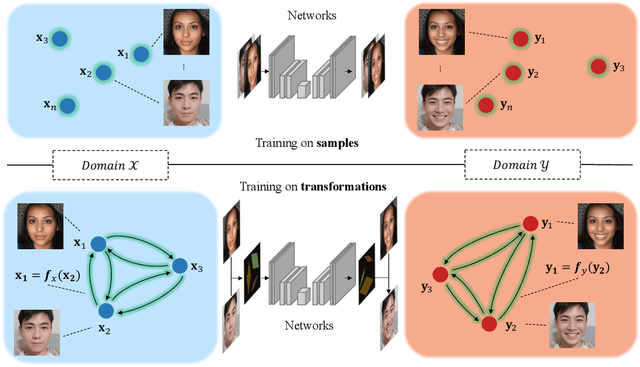
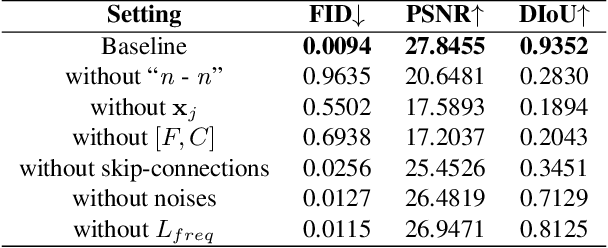
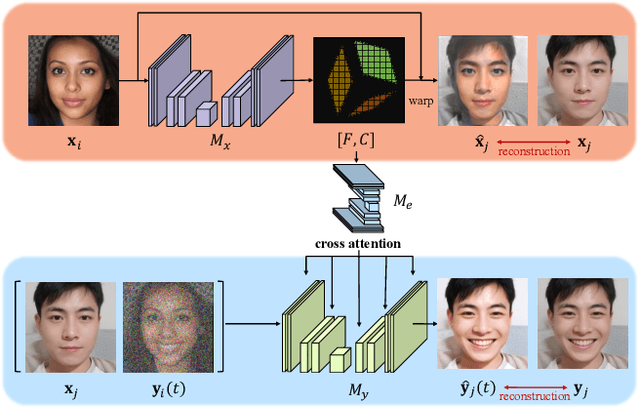
Existing solutions to image editing tasks suffer from several issues. Though achieving remarkably satisfying generated results, some supervised methods require huge amounts of paired training data, which greatly limits their usages. The other unsupervised methods take full advantage of large-scale pre-trained priors, thus being strictly restricted to the domains where the priors are trained on and behaving badly in out-of-distribution cases. The task we focus on is how to enable the users to customize their desired effects through only few image pairs. In our proposed framework, a novel few-shot learning mechanism based on the directional transformations among samples is introduced and expands the learnable space exponentially. Adopting a diffusion model pipeline, we redesign the condition calculating modules in our model and apply several technical improvements. Experimental results demonstrate the capabilities of our method in various cases.
DreamTuner: Single Image is Enough for Subject-Driven Generation
Dec 21, 2023



Diffusion-based models have demonstrated impressive capabilities for text-to-image generation and are expected for personalized applications of subject-driven generation, which require the generation of customized concepts with one or a few reference images. However, existing methods based on fine-tuning fail to balance the trade-off between subject learning and the maintenance of the generation capabilities of pretrained models. Moreover, other methods that utilize additional image encoders tend to lose important details of the subject due to encoding compression. To address these challenges, we propose DreamTurner, a novel method that injects reference information from coarse to fine to achieve subject-driven image generation more effectively. DreamTurner introduces a subject-encoder for coarse subject identity preservation, where the compressed general subject features are introduced through an attention layer before visual-text cross-attention. We then modify the self-attention layers within pretrained text-to-image models to self-subject-attention layers to refine the details of the target subject. The generated image queries detailed features from both the reference image and itself in self-subject-attention. It is worth emphasizing that self-subject-attention is an effective, elegant, and training-free method for maintaining the detailed features of customized subjects and can serve as a plug-and-play solution during inference. Finally, with additional subject-driven fine-tuning, DreamTurner achieves remarkable performance in subject-driven image generation, which can be controlled by a text or other conditions such as pose. For further details, please visit the project page at https://dreamtuner-diffusion.github.io/.
CFFT-GAN: Cross-domain Feature Fusion Transformer for Exemplar-based Image Translation
Feb 03, 2023

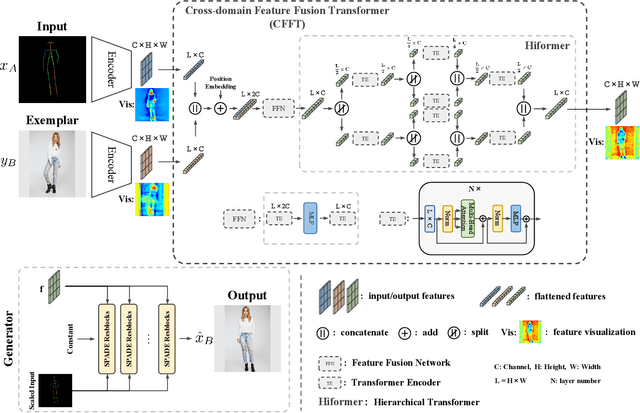
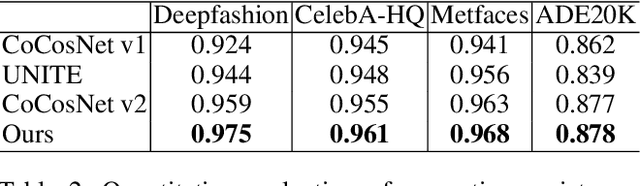
Exemplar-based image translation refers to the task of generating images with the desired style, while conditioning on certain input image. Most of the current methods learn the correspondence between two input domains and lack the mining of information within the domains. In this paper, we propose a more general learning approach by considering two domain features as a whole and learning both inter-domain correspondence and intra-domain potential information interactions. Specifically, we propose a Cross-domain Feature Fusion Transformer (CFFT) to learn inter- and intra-domain feature fusion. Based on CFFT, the proposed CFFT-GAN works well on exemplar-based image translation. Moreover, CFFT-GAN is able to decouple and fuse features from multiple domains by cascading CFFT modules. We conduct rich quantitative and qualitative experiments on several image translation tasks, and the results demonstrate the superiority of our approach compared to state-of-the-art methods. Ablation studies show the importance of our proposed CFFT. Application experimental results reflect the potential of our method.
ReGANIE: Rectifying GAN Inversion Errors for Accurate Real Image Editing
Jan 31, 2023



The StyleGAN family succeed in high-fidelity image generation and allow for flexible and plausible editing of generated images by manipulating the semantic-rich latent style space.However, projecting a real image into its latent space encounters an inherent trade-off between inversion quality and editability. Existing encoder-based or optimization-based StyleGAN inversion methods attempt to mitigate the trade-off but see limited performance. To fundamentally resolve this problem, we propose a novel two-phase framework by designating two separate networks to tackle editing and reconstruction respectively, instead of balancing the two. Specifically, in Phase I, a W-space-oriented StyleGAN inversion network is trained and used to perform image inversion and editing, which assures the editability but sacrifices reconstruction quality. In Phase II, a carefully designed rectifying network is utilized to rectify the inversion errors and perform ideal reconstruction. Experimental results show that our approach yields near-perfect reconstructions without sacrificing the editability, thus allowing accurate manipulation of real images. Further, we evaluate the performance of our rectifying network, and see great generalizability towards unseen manipulation types and out-of-domain images.
HS-Diffusion: Learning a Semantic-Guided Diffusion Model for Head Swapping
Dec 13, 2022Image-based head swapping task aims to stitch a source head to another source body flawlessly. This seldom-studied task faces two major challenges: 1) Preserving the head and body from various sources while generating a seamless transition region. 2) No paired head swapping dataset and benchmark so far. In this paper, we propose an image-based head swapping framework (HS-Diffusion) which consists of a semantic-guided latent diffusion model (SG-LDM) and a semantic layout generator. We blend the semantic layouts of source head and source body, and then inpaint the transition region by the semantic layout generator, achieving a coarse-grained head swapping. SG-LDM can further implement fine-grained head swapping with the blended layout as condition by a progressive fusion process, while preserving source head and source body with high-quality reconstruction. To this end, we design a head-cover augmentation strategy for training and a neck alignment trick for geometric realism. Importantly, we construct a new image-based head swapping benchmark and propose two tailor-designed metrics (Mask-FID and Focal-FID). Extensive experiments demonstrate the superiority of our framework. The code will be available: https://github.com/qinghew/HS-Diffusion.
Region-Aware Face Swapping
Mar 18, 2022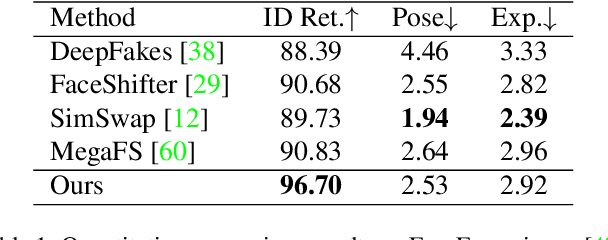
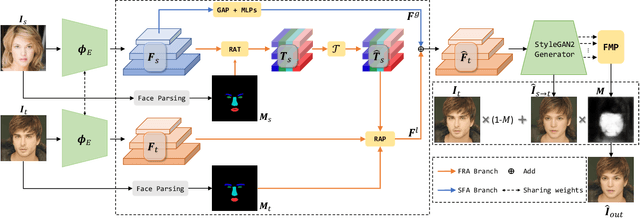

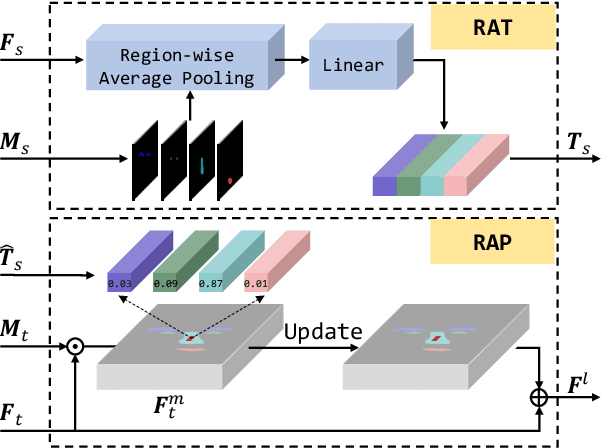
This paper presents a novel Region-Aware Face Swapping (RAFSwap) network to achieve identity-consistent harmonious high-resolution face generation in a local-global manner: \textbf{1)} Local Facial Region-Aware (FRA) branch augments local identity-relevant features by introducing the Transformer to effectively model misaligned cross-scale semantic interaction. \textbf{2)} Global Source Feature-Adaptive (SFA) branch further complements global identity-relevant cues for generating identity-consistent swapped faces. Besides, we propose a \textit{Face Mask Predictor} (FMP) module incorporated with StyleGAN2 to predict identity-relevant soft facial masks in an unsupervised manner that is more practical for generating harmonious high-resolution faces. Abundant experiments qualitatively and quantitatively demonstrate the superiority of our method for generating more identity-consistent high-resolution swapped faces over SOTA methods, \eg, obtaining 96.70 ID retrieval that outperforms SOTA MegaFS by 5.87$\uparrow$.
FaceEraser: Removing Facial Parts for Augmented Reality
Sep 22, 2021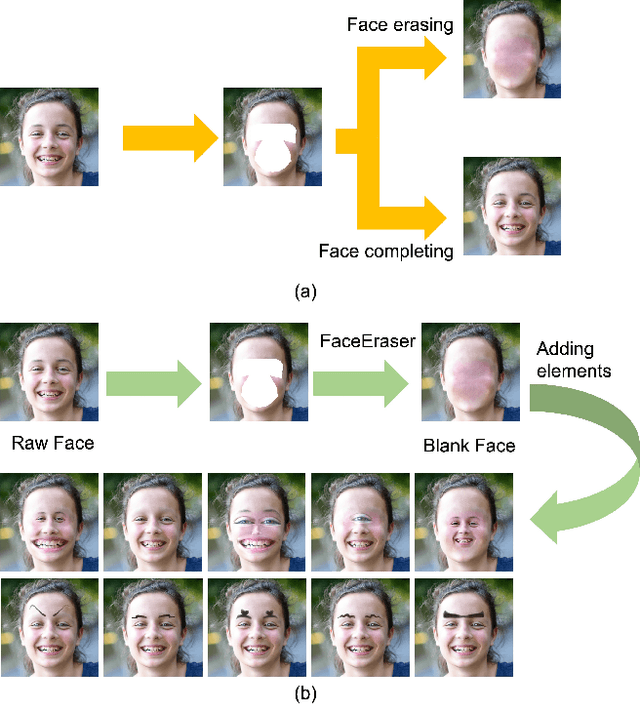

Our task is to remove all facial parts (e.g., eyebrows, eyes, mouth and nose), and then impose visual elements onto the ``blank'' face for augmented reality. Conventional object removal methods rely on image inpainting techniques (e.g., EdgeConnect, HiFill) that are trained in a self-supervised manner with randomly manipulated image pairs. Specifically, given a set of natural images, randomly masked images are used as inputs and the raw images are treated as ground truths. Whereas, this technique does not satisfy the requirements of facial parts removal, as it is hard to obtain ``ground-truth'' images with real ``blank'' faces. To address this issue, we propose a novel data generation technique to produce paired training data that well mimic the ``blank'' faces. In the mean time, we propose a novel network architecture for improved inpainting quality for our task. Finally, we demonstrate various face-oriented augmented reality applications on top of our facial parts removal model. Our method has been integrated into commercial products and its effectiveness has been verified with unconstrained user inputs. The source codes, pre-trained models and training data will be released for research purposes.
DyStyle: Dynamic Neural Network for Multi-Attribute-Conditioned Style Editing
Sep 22, 2021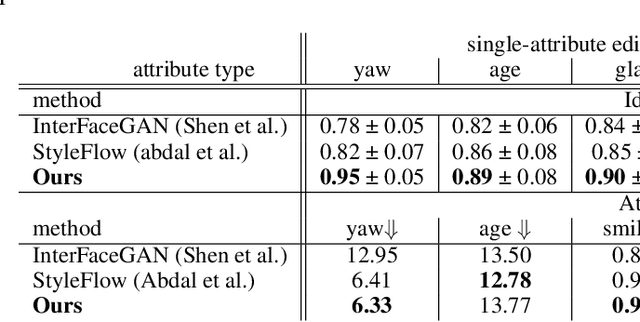
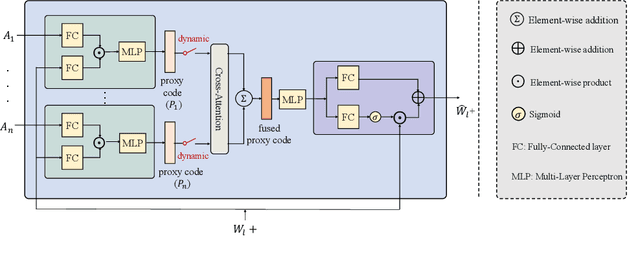
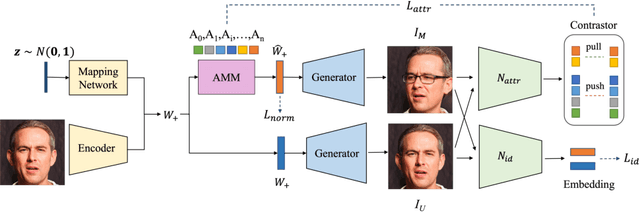
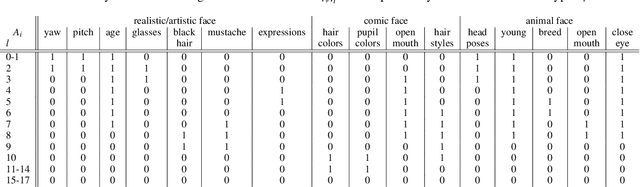
Great diversity and photorealism have been achieved by unconditional GAN frameworks such as StyleGAN and its variations. In the meantime, persistent efforts have been made to enhance the semantic controllability of StyleGANs. For example, a dozen of style manipulation methods have been recently proposed to perform attribute-conditioned style editing. Although some of these methods work well in manipulating the style codes along one attribute, the control accuracy when jointly manipulating multiple attributes tends to be problematic. To address these limitations, we propose a Dynamic Style Manipulation Network (DyStyle) whose structure and parameters vary by input samples, to perform nonlinear and adaptive manipulation of latent codes for flexible and precise attribute control. Additionally, a novel easy-to-hard training procedure is introduced for efficient and stable training of the DyStyle network. Extensive experiments have been conducted on faces and other objects. As a result, our approach demonstrates fine-grained disentangled edits along multiple numeric and binary attributes. Qualitative and quantitative comparisons with existing style manipulation methods verify the superiority of our method in terms of the attribute control accuracy and identity preservation without compromising the photorealism. The advantage of our method is even more significant for joint multi-attribute control. The source codes are made publicly available at \href{https://github.com/phycvgan/DyStyle}{phycvgan/DyStyle}.