 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLibraGen: Playing a Balance Game in Subject-Driven Video Generation
Mar 17, 2026With the advancement of video generation foundation models (VGFMs), customized generation, particularly subject-to-video (S2V), has attracted growing attention. However, a key challenge lies in balancing the intrinsic priors of a VGFM, such as motion coherence, visual aesthetics, and prompt alignment, with its newly derived S2V capability. Existing methods often neglect this balance by enhancing one aspect at the expense of others. To address this, we propose LibraGen, a novel framework that views extending foundation models for S2V generation as a balance game between intrinsic VGFM strengths and S2V capability. Specifically, guided by the core philosophy of "Raising the Fulcrum, Tuning to Balance," we identify data quality as the fulcrum and advocate a quality-over-quantity approach. We construct a hybrid pipeline that combines automated and manual data filtering to improve overall data quality. To further harmonize the VGFM's native capabilities with its S2V extension, we introduce a Tune-to-Balance post-training paradigm. During supervised fine-tuning, both cross-pair and in-pair data are incorporated, and model merging is employed to achieve an effective trade-off. Subsequently, two tailored direct preference optimization (DPO) pipelines, namely Consis-DPO and Real-Fake DPO, are designed and merged to consolidate this balance. During inference, we introduce a time-dependent dynamic classifier-free guidance scheme to enable flexible and fine-grained control. Experimental results demonstrate that LibraGen outperforms both open-source and commercial S2V models using only thousand-scale training data.
HuMo: Human-Centric Video Generation via Collaborative Multi-Modal Conditioning
Sep 10, 2025Human-Centric Video Generation (HCVG) methods seek to synthesize human videos from multimodal inputs, including text, image, and audio. Existing methods struggle to effectively coordinate these heterogeneous modalities due to two challenges: the scarcity of training data with paired triplet conditions and the difficulty of collaborating the sub-tasks of subject preservation and audio-visual sync with multimodal inputs. In this work, we present HuMo, a unified HCVG framework for collaborative multimodal control. For the first challenge, we construct a high-quality dataset with diverse and paired text, reference images, and audio. For the second challenge, we propose a two-stage progressive multimodal training paradigm with task-specific strategies. For the subject preservation task, to maintain the prompt following and visual generation abilities of the foundation model, we adopt the minimal-invasive image injection strategy. For the audio-visual sync task, besides the commonly adopted audio cross-attention layer, we propose a focus-by-predicting strategy that implicitly guides the model to associate audio with facial regions. For joint learning of controllabilities across multimodal inputs, building on previously acquired capabilities, we progressively incorporate the audio-visual sync task. During inference, for flexible and fine-grained multimodal control, we design a time-adaptive Classifier-Free Guidance strategy that dynamically adjusts guidance weights across denoising steps. Extensive experimental results demonstrate that HuMo surpasses specialized state-of-the-art methods in sub-tasks, establishing a unified framework for collaborative multimodal-conditioned HCVG. Project Page: https://phantom-video.github.io/HuMo.
Phantom-Data : Towards a General Subject-Consistent Video Generation Dataset
Jun 23, 2025Subject-to-video generation has witnessed substantial progress in recent years. However, existing models still face significant challenges in faithfully following textual instructions. This limitation, commonly known as the copy-paste problem, arises from the widely used in-pair training paradigm. This approach inherently entangles subject identity with background and contextual attributes by sampling reference images from the same scene as the target video. To address this issue, we introduce \textbf{Phantom-Data, the first general-purpose cross-pair subject-to-video consistency dataset}, containing approximately one million identity-consistent pairs across diverse categories. Our dataset is constructed via a three-stage pipeline: (1) a general and input-aligned subject detection module, (2) large-scale cross-context subject retrieval from more than 53 million videos and 3 billion images, and (3) prior-guided identity verification to ensure visual consistency under contextual variation. Comprehensive experiments show that training with Phantom-Data significantly improves prompt alignment and visual quality while preserving identity consistency on par with in-pair baselines.
I2VControl-Camera: Precise Video Camera Control with Adjustable Motion Strength
Nov 26, 2024

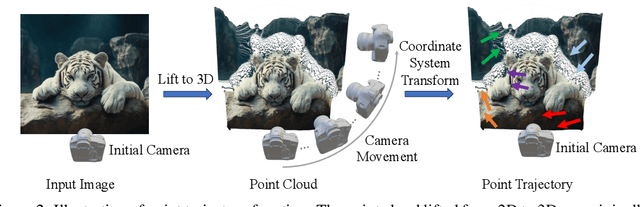
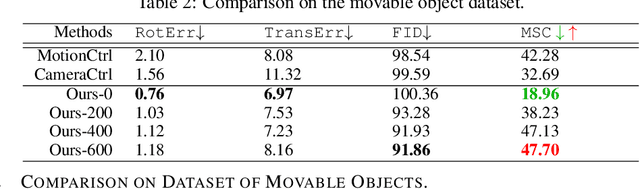
Video generation technologies are developing rapidly and have broad potential applications. Among these technologies, camera control is crucial for generating professional-quality videos that accurately meet user expectations. However, existing camera control methods still suffer from several limitations, including control precision and the neglect of the control for subject motion dynamics. In this work, we propose I2VControl-Camera, a novel camera control method that significantly enhances controllability while providing adjustability over the strength of subject motion. To improve control precision, we employ point trajectory in the camera coordinate system instead of only extrinsic matrix information as our control signal. To accurately control and adjust the strength of subject motion, we explicitly model the higher-order components of the video trajectory expansion, not merely the linear terms, and design an operator that effectively represents the motion strength. We use an adapter architecture that is independent of the base model structure. Experiments on static and dynamic scenes show that our framework outperformances previous methods both quantitatively and qualitatively. The project page is: https://wanquanf.github.io/I2VControlCamera .
I2VControl: Disentangled and Unified Video Motion Synthesis Control
Nov 26, 2024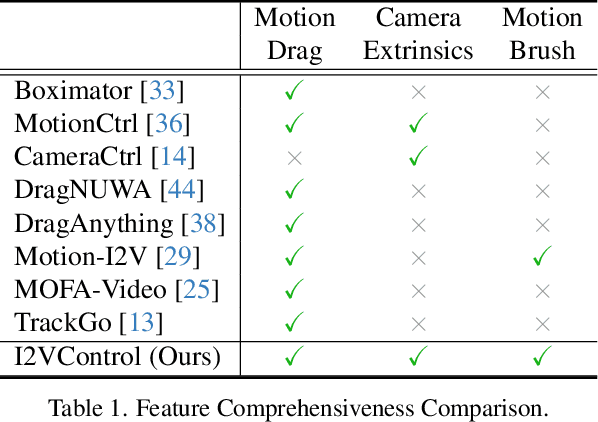
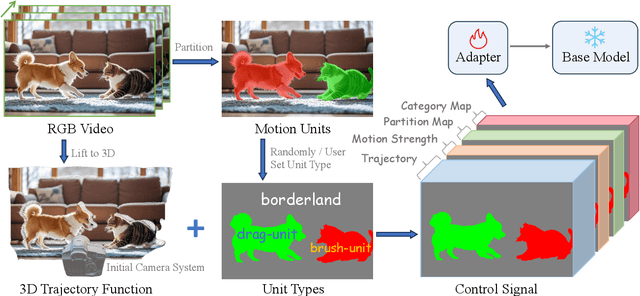
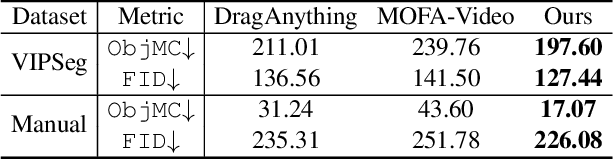

Video synthesis techniques are undergoing rapid progress, with controllability being a significant aspect of practical usability for end-users. Although text condition is an effective way to guide video synthesis, capturing the correct joint distribution between text descriptions and video motion remains a substantial challenge. In this paper, we present a disentangled and unified framework, namely I2VControl, that unifies multiple motion control tasks in image-to-video synthesis. Our approach partitions the video into individual motion units and represents each unit with disentangled control signals, which allows for various control types to be flexibly combined within our single system. Furthermore, our methodology seamlessly integrates as a plug-in for pre-trained models and remains agnostic to specific model architectures. We conduct extensive experiments, achieving excellent performance on various control tasks, and our method further facilitates user-driven creative combinations, enhancing innovation and creativity. The project page is: https://wanquanf.github.io/I2VControl .
RS-Corrector: Correcting the Racial Stereotypes in Latent Diffusion Models
Dec 20, 2023



Recent text-conditioned image generation models have demonstrated an exceptional capacity to produce diverse and creative imagery with high visual quality. However, when pre-trained on billion-sized datasets randomly collected from the Internet, where potential biased human preferences exist, these models tend to produce images with common and recurring stereotypes, particularly for certain racial groups. In this paper, we conduct an initial analysis of the publicly available Stable Diffusion model and its derivatives, highlighting the presence of racial stereotypes. These models often generate distorted or biased images for certain racial groups, emphasizing stereotypical characteristics. To address these issues, we propose a framework called "RS-Corrector", designed to establish an anti-stereotypical preference in the latent space and update the latent code for refined generated results. The correction process occurs during the inference stage without requiring fine-tuning of the original model. Extensive empirical evaluations demonstrate that the introduced \themodel effectively corrects the racial stereotypes of the well-trained Stable Diffusion model while leaving the original model unchanged.
GaFET: Learning Geometry-aware Facial Expression Translation from In-The-Wild Images
Aug 07, 2023While current face animation methods can manipulate expressions individually, they suffer from several limitations. The expressions manipulated by some motion-based facial reenactment models are crude. Other ideas modeled with facial action units cannot generalize to arbitrary expressions not covered by annotations. In this paper, we introduce a novel Geometry-aware Facial Expression Translation (GaFET) framework, which is based on parametric 3D facial representations and can stably decoupled expression. Among them, a Multi-level Feature Aligned Transformer is proposed to complement non-geometric facial detail features while addressing the alignment challenge of spatial features. Further, we design a De-expression model based on StyleGAN, in order to reduce the learning difficulty of GaFET in unpaired "in-the-wild" images. Extensive qualitative and quantitative experiments demonstrate that we achieve higher-quality and more accurate facial expression transfer results compared to state-of-the-art methods, and demonstrate applicability of various poses and complex textures. Besides, videos or annotated training data are omitted, making our method easier to use and generalize.
Free-style and Fast 3D Portrait Synthesis
Jun 28, 2023Efficiently generating a free-style 3D portrait with high quality and consistency is a promising yet challenging task. The portrait styles generated by most existing methods are usually restricted by their 3D generators, which are learned in specific facial datasets, such as FFHQ. To get a free-style 3D portrait, one can build a large-scale multi-style database to retrain the 3D generator, or use a off-the-shelf tool to do the style translation. However, the former is time-consuming due to data collection and training process, the latter may destroy the multi-view consistency. To tackle this problem, we propose a fast 3D portrait synthesis framework in this paper, which enable one to use text prompts to specify styles. Specifically, for a given portrait style, we first leverage two generative priors, a 3D-aware GAN generator (EG3D) and a text-guided image editor (Ip2p), to quickly construct a few-shot training set, where the inference process of Ip2p is optimized to make editing more stable. Then we replace original triplane generator of EG3D with a Image-to-Triplane (I2T) module for two purposes: 1) getting rid of the style constraints of pre-trained EG3D by fine-tuning I2T on the few-shot dataset; 2) improving training efficiency by fixing all parts of EG3D except I2T. Furthermore, we construct a multi-style and multi-identity 3D portrait database to demonstrate the scalability and generalization of our method. Experimental results show that our method is capable of synthesizing high-quality 3D portraits with specified styles in a few minutes, outperforming the state-of-the-art.
Semantic 3D-aware Portrait Synthesis and Manipulation Based on Compositional Neural Radiance Field
Feb 03, 2023
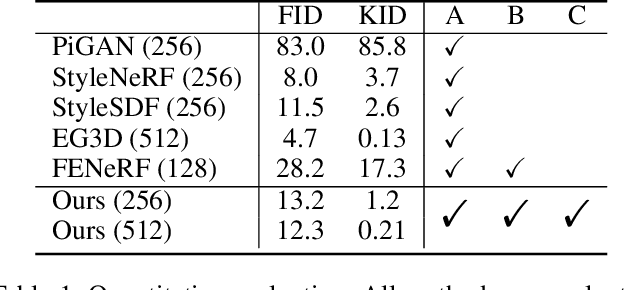
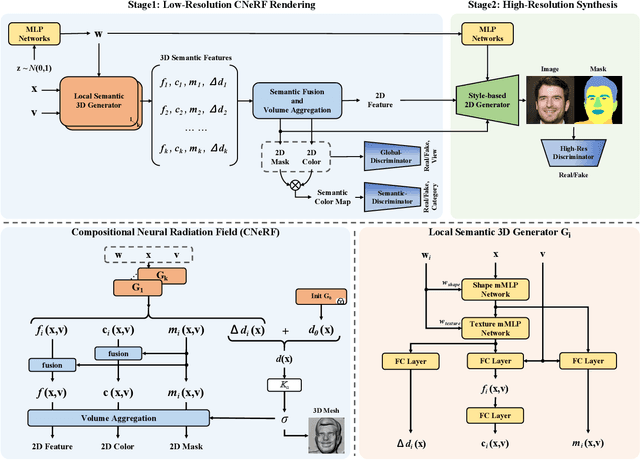

Recently 3D-aware GAN methods with neural radiance field have developed rapidly. However, current methods model the whole image as an overall neural radiance field, which limits the partial semantic editability of synthetic results. Since NeRF renders an image pixel by pixel, it is possible to split NeRF in the spatial dimension. We propose a Compositional Neural Radiance Field (CNeRF) for semantic 3D-aware portrait synthesis and manipulation. CNeRF divides the image by semantic regions and learns an independent neural radiance field for each region, and finally fuses them and renders the complete image. Thus we can manipulate the synthesized semantic regions independently, while fixing the other parts unchanged. Furthermore, CNeRF is also designed to decouple shape and texture within each semantic region. Compared to state-of-the-art 3D-aware GAN methods, our approach enables fine-grained semantic region manipulation, while maintaining high-quality 3D-consistent synthesis. The ablation studies show the effectiveness of the structure and loss function used by our method. In addition real image inversion and cartoon portrait 3D editing experiments demonstrate the application potential of our method.
CFFT-GAN: Cross-domain Feature Fusion Transformer for Exemplar-based Image Translation
Feb 03, 2023

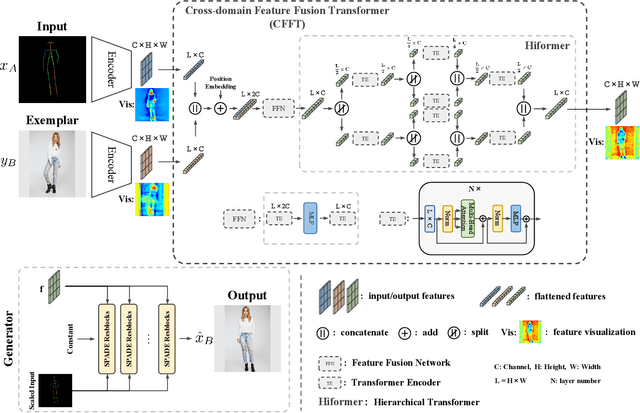
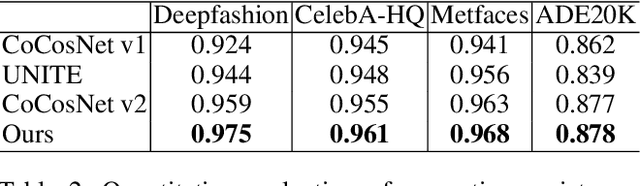
Exemplar-based image translation refers to the task of generating images with the desired style, while conditioning on certain input image. Most of the current methods learn the correspondence between two input domains and lack the mining of information within the domains. In this paper, we propose a more general learning approach by considering two domain features as a whole and learning both inter-domain correspondence and intra-domain potential information interactions. Specifically, we propose a Cross-domain Feature Fusion Transformer (CFFT) to learn inter- and intra-domain feature fusion. Based on CFFT, the proposed CFFT-GAN works well on exemplar-based image translation. Moreover, CFFT-GAN is able to decouple and fuse features from multiple domains by cascading CFFT modules. We conduct rich quantitative and qualitative experiments on several image translation tasks, and the results demonstrate the superiority of our approach compared to state-of-the-art methods. Ablation studies show the importance of our proposed CFFT. Application experimental results reflect the potential of our method.