 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNextFlow: Unified Sequential Modeling Activates Multimodal Understanding and Generation
Jan 05, 2026We present NextFlow, a unified decoder-only autoregressive transformer trained on 6 trillion interleaved text-image discrete tokens. By leveraging a unified vision representation within a unified autoregressive architecture, NextFlow natively activates multimodal understanding and generation capabilities, unlocking abilities of image editing, interleaved content and video generation. Motivated by the distinct nature of modalities - where text is strictly sequential and images are inherently hierarchical - we retain next-token prediction for text but adopt next-scale prediction for visual generation. This departs from traditional raster-scan methods, enabling the generation of 1024x1024 images in just 5 seconds - orders of magnitude faster than comparable AR models. We address the instabilities of multi-scale generation through a robust training recipe. Furthermore, we introduce a prefix-tuning strategy for reinforcement learning. Experiments demonstrate that NextFlow achieves state-of-the-art performance among unified models and rivals specialized diffusion baselines in visual quality.
Phantom-Data : Towards a General Subject-Consistent Video Generation Dataset
Jun 23, 2025Subject-to-video generation has witnessed substantial progress in recent years. However, existing models still face significant challenges in faithfully following textual instructions. This limitation, commonly known as the copy-paste problem, arises from the widely used in-pair training paradigm. This approach inherently entangles subject identity with background and contextual attributes by sampling reference images from the same scene as the target video. To address this issue, we introduce \textbf{Phantom-Data, the first general-purpose cross-pair subject-to-video consistency dataset}, containing approximately one million identity-consistent pairs across diverse categories. Our dataset is constructed via a three-stage pipeline: (1) a general and input-aligned subject detection module, (2) large-scale cross-context subject retrieval from more than 53 million videos and 3 billion images, and (3) prior-guided identity verification to ensure visual consistency under contextual variation. Comprehensive experiments show that training with Phantom-Data significantly improves prompt alignment and visual quality while preserving identity consistency on par with in-pair baselines.
RealCustom++: Representing Images as Real-Word for Real-Time Customization
Aug 19, 2024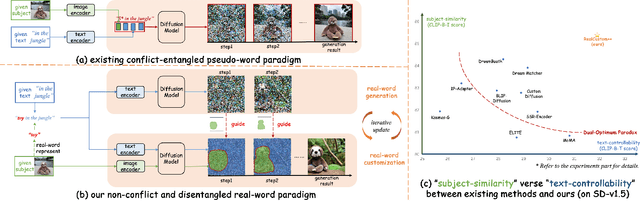
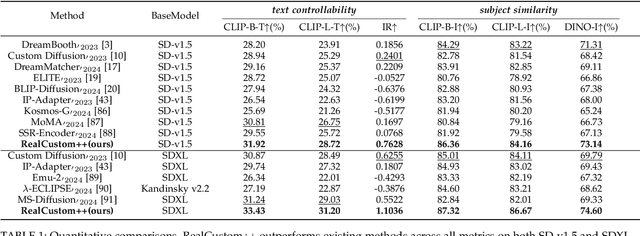


Text-to-image customization, which takes given texts and images depicting given subjects as inputs, aims to synthesize new images that align with both text semantics and subject appearance. This task provides precise control over details that text alone cannot capture and is fundamental for various real-world applications, garnering significant interest from academia and industry. Existing works follow the pseudo-word paradigm, which involves representing given subjects as pseudo-words and combining them with given texts to collectively guide the generation. However, the inherent conflict and entanglement between the pseudo-words and texts result in a dual-optimum paradox, where subject similarity and text controllability cannot be optimal simultaneously. We propose a novel real-words paradigm termed RealCustom++ that instead represents subjects as non-conflict real words, thereby disentangling subject similarity from text controllability and allowing both to be optimized simultaneously. Specifically, RealCustom++ introduces a novel "train-inference" decoupled framework: (1) During training, RealCustom++ learns the alignment between vision conditions and all real words in the text, ensuring high subject-similarity generation in open domains. This is achieved by the cross-layer cross-scale projector to robustly and finely extract subject features, and a curriculum training recipe that adapts the generated subject to diverse poses and sizes. (2) During inference, leveraging the learned general alignment, an adaptive mask guidance is proposed to only customize the generation of the specific target real word, keeping other subject-irrelevant regions uncontaminated to ensure high text-controllability in real-time.
RealCustom: Narrowing Real Text Word for Real-Time Open-Domain Text-to-Image Customization
Mar 01, 2024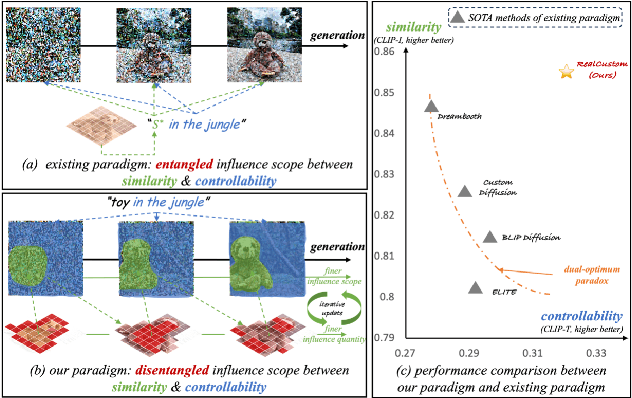
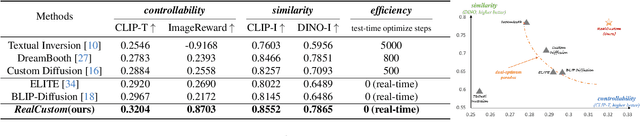

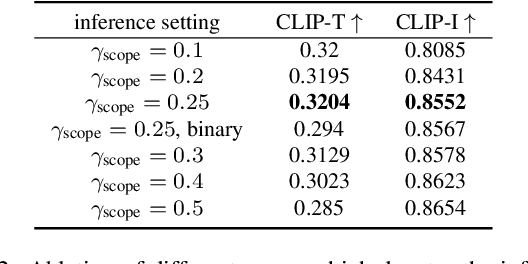
Text-to-image customization, which aims to synthesize text-driven images for the given subjects, has recently revolutionized content creation. Existing works follow the pseudo-word paradigm, i.e., represent the given subjects as pseudo-words and then compose them with the given text. However, the inherent entangled influence scope of pseudo-words with the given text results in a dual-optimum paradox, i.e., the similarity of the given subjects and the controllability of the given text could not be optimal simultaneously. We present RealCustom that, for the first time, disentangles similarity from controllability by precisely limiting subject influence to relevant parts only, achieved by gradually narrowing real text word from its general connotation to the specific subject and using its cross-attention to distinguish relevance. Specifically, RealCustom introduces a novel "train-inference" decoupled framework: (1) during training, RealCustom learns general alignment between visual conditions to original textual conditions by a novel adaptive scoring module to adaptively modulate influence quantity; (2) during inference, a novel adaptive mask guidance strategy is proposed to iteratively update the influence scope and influence quantity of the given subjects to gradually narrow the generation of the real text word. Comprehensive experiments demonstrate the superior real-time customization ability of RealCustom in the open domain, achieving both unprecedented similarity of the given subjects and controllability of the given text for the first time. The project page is https://corleone-huang.github.io/realcustom/.
BlendGAN: Implicitly GAN Blending for Arbitrary Stylized Face Generation
Oct 22, 2021



Generative Adversarial Networks (GANs) have made a dramatic leap in high-fidelity image synthesis and stylized face generation. Recently, a layer-swapping mechanism has been developed to improve the stylization performance. However, this method is incapable of fitting arbitrary styles in a single model and requires hundreds of style-consistent training images for each style. To address the above issues, we propose BlendGAN for arbitrary stylized face generation by leveraging a flexible blending strategy and a generic artistic dataset. Specifically, we first train a self-supervised style encoder on the generic artistic dataset to extract the representations of arbitrary styles. In addition, a weighted blending module (WBM) is proposed to blend face and style representations implicitly and control the arbitrary stylization effect. By doing so, BlendGAN can gracefully fit arbitrary styles in a unified model while avoiding case-by-case preparation of style-consistent training images. To this end, we also present a novel large-scale artistic face dataset AAHQ. Extensive experiments demonstrate that BlendGAN outperforms state-of-the-art methods in terms of visual quality and style diversity for both latent-guided and reference-guided stylized face synthesis.