 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniDirector: General Multi-Shot Camera Cloning without Cross-Paired Data
Jun 11, 2026Cloning camera motion from reference videos is an important task in video generation, as videos provide intuitive and precise control. Existing methods either directly use parametric representations that fail to handle multi-shot generation or synthesize cross-paired data, which suffer from data scarcity, resulting in poor performance in complicated camera motion cloning. To address these issues, we introduce a general camera motion representation that encodes cameras as grid motion videos. This camera grid represents the camera parameters visually and supports the integration of diverse trajectories for multi-shot video generation. Building upon this, we propose OmniDirector, a unified framework trained on a million-scale camera grid-video pairs that coordinates characters, actions, and cameras to provide director-level control for multimodal diffusion transformers. Furthermore, we design a novel hierarchical prompt expansion agent that harmoniously integrates different control signals by systematically describing camera motion and visual content through understanding signal relationships. Extensive experiments demonstrate the superior performance and outstanding controllability of our framework. Project page: https://ymlinfeng.github.io/OmniDirector.github.io/
ERGeoBench:A Comprehensive Benchmark for Embodied Reasoning and Geo-localization in Multimodal Large Language Models
May 29, 2026Multimodal large language models (MLLMs) have shown strong potential as embodied agents, yet embodied geo-localization remains underexplored due to the lack of fine-grained evaluation. We introduce ERGeoBench, a diagnostic benchmark for vision-driven embodied geo-localization. ERGeoBench evaluates models under three progressive settings -- single-view, panorama-view, and embodied-view -- where agents may actively acquire observations through sequential changes in yaw, pitch, and zoom. The benchmark contains 2,207 globally distributed street-view panoramas and measures four complementary capabilities: foundational perception, spatial awareness, common sense reasoning, and geo-localization reasoning. Evaluations of leading proprietary and open-source MLLMs show that current models can infer high-level geographic semantics, but still struggle with fine-grained perceptual operations, metric localization, and spatial consistency across views. We further observe that geo-localization is strongly correlated with the other capability dimensions, suggesting that accurate localization depends on integrated perception, spatial reasoning, and commonsense inference rather than isolated visual recognition. Overall, ERGeoBench provides a unified framework for diagnosing and advancing human-like embodied geo-localization. Project Page: https://kaixuewen.github.io/ERGeoBench/
CreBench: Human-Aligned Creativity Evaluation from Idea to Process to Product
Nov 17, 2025Human-defined creativity is highly abstract, posing a challenge for multimodal large language models (MLLMs) to comprehend and assess creativity that aligns with human judgments. The absence of an existing benchmark further exacerbates this dilemma. To this end, we propose CreBench, which consists of two key components: 1) an evaluation benchmark covering the multiple dimensions from creative idea to process to products; 2) CreMIT (Creativity Multimodal Instruction Tuning dataset), a multimodal creativity evaluation dataset, consisting of 2.2K diverse-sourced multimodal data, 79.2K human feedbacks and 4.7M multi-typed instructions. Specifically, to ensure MLLMs can handle diverse creativity-related queries, we prompt GPT to refine these human feedbacks to activate stronger creativity assessment capabilities. CreBench serves as a foundation for building MLLMs that understand human-aligned creativity. Based on the CreBench, we fine-tune open-source general MLLMs, resulting in CreExpert, a multimodal creativity evaluation expert model. Extensive experiments demonstrate that the proposed CreExpert models achieve significantly better alignment with human creativity evaluation compared to state-of-the-art MLLMs, including the most advanced GPT-4V and Gemini-Pro-Vision.
FGU3R: Fine-Grained Fusion via Unified 3D Representation for Multimodal 3D Object Detection
Jan 08, 2025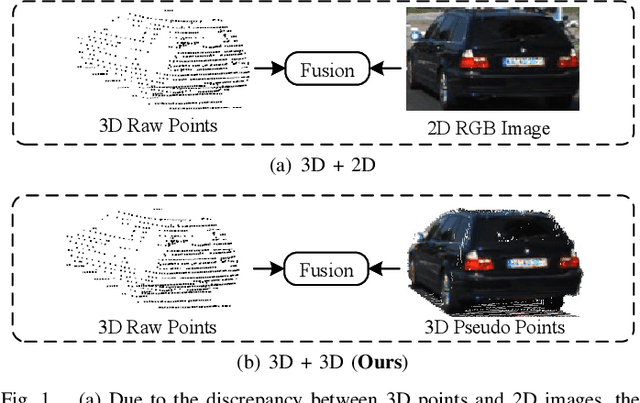
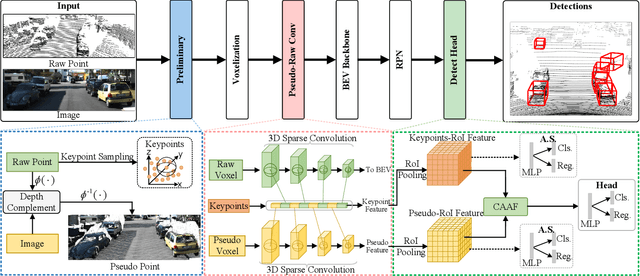


Multimodal 3D object detection has garnered considerable interest in autonomous driving. However, multimodal detectors suffer from dimension mismatches that derive from fusing 3D points with 2D pixels coarsely, which leads to sub-optimal fusion performance. In this paper, we propose a multimodal framework FGU3R to tackle the issue mentioned above via unified 3D representation and fine-grained fusion, which consists of two important components. First, we propose an efficient feature extractor for raw and pseudo points, termed Pseudo-Raw Convolution (PRConv), which modulates multimodal features synchronously and aggregates the features from different types of points on key points based on multimodal interaction. Second, a Cross-Attention Adaptive Fusion (CAAF) is designed to fuse homogeneous 3D RoI (Region of Interest) features adaptively via a cross-attention variant in a fine-grained manner. Together they make fine-grained fusion on unified 3D representation. The experiments conducted on the KITTI and nuScenes show the effectiveness of our proposed method.
Segmentation-aware Prior Assisted Joint Global Information Aggregated 3D Building Reconstruction
Oct 24, 2024Multi-View Stereo plays a pivotal role in civil engineering by facilitating 3D modeling, precise engineering surveying, quantitative analysis, as well as monitoring and maintenance. It serves as a valuable tool, offering high-precision and real-time spatial information crucial for various engineering projects. However, Multi-View Stereo algorithms encounter challenges in reconstructing weakly-textured regions within large-scale building scenes. In these areas, the stereo matching of pixels often fails, leading to inaccurate depth estimations. Based on the Segment Anything Model and RANSAC algorithm, we propose an algorithm that accurately segments weakly-textured regions and constructs their plane priors. These plane priors, combined with triangulation priors, form a reliable prior candidate set. Additionally, we introduce a novel global information aggregation cost function. This function selects optimal plane prior information based on global information in the prior candidate set, constrained by geometric consistency during the depth estimation update process. Experimental results on both the ETH3D benchmark dataset, aerial dataset, building dataset and real scenarios substantiate the superior performance of our method in producing 3D building models compared to other state-of-the-art methods. In summary, our work aims to enhance the completeness and density of 3D building reconstruction, carrying implications for broader applications in urban planning and virtual reality.
ContrastAlign: Toward Robust BEV Feature Alignment via Contrastive Learning for Multi-Modal 3D Object Detection
May 27, 2024



In the field of 3D object detection tasks, fusing heterogeneous features from LiDAR and camera sensors into a unified Bird's Eye View (BEV) representation is a widely adopted paradigm. However, existing methods are often compromised by imprecise sensor calibration, resulting in feature misalignment in LiDAR-camera BEV fusion. Moreover, such inaccuracies result in errors in depth estimation for the camera branch, ultimately causing misalignment between LiDAR and camera BEV features. In this work, we propose a novel ContrastAlign approach that utilizes contrastive learning to enhance the alignment of heterogeneous modalities, thereby improving the robustness of the fusion process. Specifically, our approach includes the L-Instance module, which directly outputs LiDAR instance features within LiDAR BEV features. Then, we introduce the C-Instance module, which predicts camera instance features through RoI (Region of Interest) pooling on the camera BEV features. We propose the InstanceFusion module, which utilizes contrastive learning to generate similar instance features across heterogeneous modalities. We then use graph matching to calculate the similarity between the neighboring camera instance features and the similarity instance features to complete the alignment of instance features. Our method achieves state-of-the-art performance, with an mAP of 70.3%, surpassing BEVFusion by 1.8% on the nuScenes validation set. Importantly, our method outperforms BEVFusion by 7.3% under conditions with misalignment noise.
Robustness-Aware 3D Object Detection in Autonomous Driving: A Review and Outlook
Jan 12, 2024In the realm of modern autonomous driving, the perception system is indispensable for accurately assessing the state of the surrounding environment, thereby enabling informed prediction and planning. Key to this system is 3D object detection methods, that utilize vehicle-mounted sensors such as LiDAR and cameras to identify the size, category, and location of nearby objects. Despite the surge in 3D object detection methods aimed at enhancing detection precision and efficiency, there is a gap in the literature that systematically examines their resilience against environmental variations, noise, and weather changes. This study emphasizes the importance of robustness, alongside accuracy and latency, in evaluating perception systems under practical scenarios. Our work presents an extensive survey of camera-based, LiDAR-based, and multimodal 3D object detection algorithms, thoroughly evaluating their trade-off between accuracy, latency, and robustness, particularly on datasets like KITTI-C and nuScenes-C to ensure fair comparisons. Among these,multimodal 3D detection approaches exhibit superior robustness and a novel taxonomy is introduced to reorganize its literature for enhanced clarity. This survey aims to offer a more practical perspective on the current capabilities and constraints of 3D object detection algorithms in real-world applications, thus steering future research towards robustness-centric advancements
VoxelNextFusion: A Simple, Unified and Effective Voxel Fusion Framework for Multi-Modal 3D Object Detection
Jan 05, 2024LiDAR-camera fusion can enhance the performance of 3D object detection by utilizing complementary information between depth-aware LiDAR points and semantically rich images. Existing voxel-based methods face significant challenges when fusing sparse voxel features with dense image features in a one-to-one manner, resulting in the loss of the advantages of images, including semantic and continuity information, leading to sub-optimal detection performance, especially at long distances. In this paper, we present VoxelNextFusion, a multi-modal 3D object detection framework specifically designed for voxel-based methods, which effectively bridges the gap between sparse point clouds and dense images. In particular, we propose a voxel-based image pipeline that involves projecting point clouds onto images to obtain both pixel- and patch-level features. These features are then fused using a self-attention to obtain a combined representation. Moreover, to address the issue of background features present in patches, we propose a feature importance module that effectively distinguishes between foreground and background features, thus minimizing the impact of the background features. Extensive experiments were conducted on the widely used KITTI and nuScenes 3D object detection benchmarks. Notably, our VoxelNextFusion achieved around +3.20% in AP@0.7 improvement for car detection in hard level compared to the Voxel R-CNN baseline on the KITTI test dataset
ITTR: Unpaired Image-to-Image Translation with Transformers
Mar 30, 2022
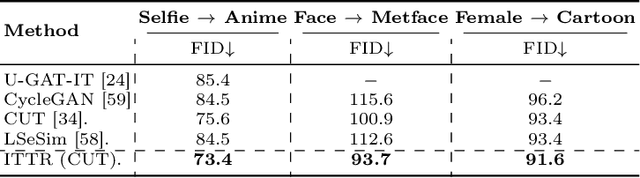

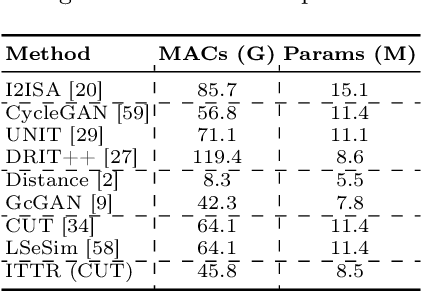
Unpaired image-to-image translation is to translate an image from a source domain to a target domain without paired training data. By utilizing CNN in extracting local semantics, various techniques have been developed to improve the translation performance. However, CNN-based generators lack the ability to capture long-range dependency to well exploit global semantics. Recently, Vision Transformers have been widely investigated for recognition tasks. Though appealing, it is inappropriate to simply transfer a recognition-based vision transformer to image-to-image translation due to the generation difficulty and the computation limitation. In this paper, we propose an effective and efficient architecture for unpaired Image-to-Image Translation with Transformers (ITTR). It has two main designs: 1) hybrid perception block (HPB) for token mixing from different receptive fields to utilize global semantics; 2) dual pruned self-attention (DPSA) to sharply reduce the computational complexity. Our ITTR outperforms the state-of-the-arts for unpaired image-to-image translation on six benchmark datasets.
Audio-Driven Talking Face Video Generation with Dynamic Convolution Kernels
Jan 16, 2022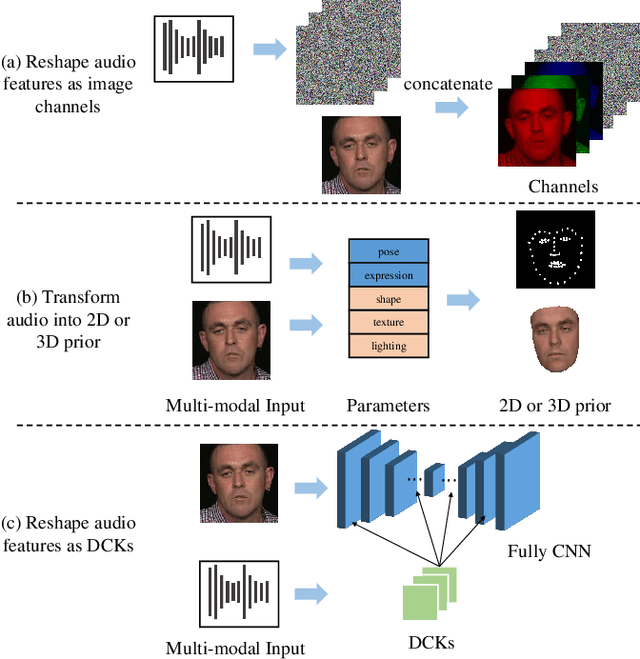
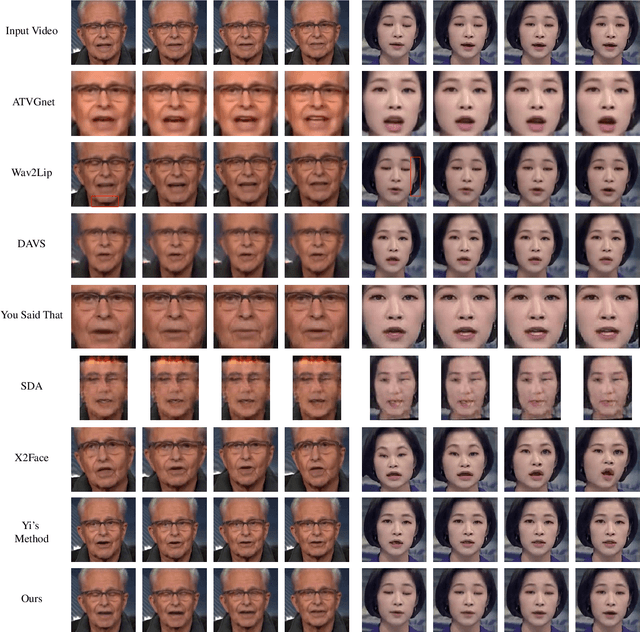
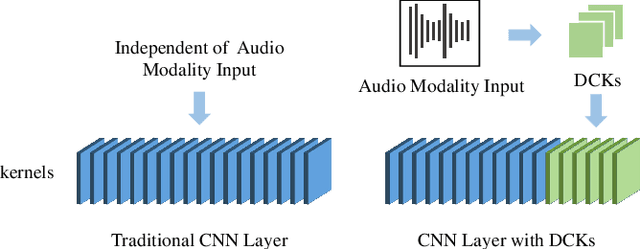
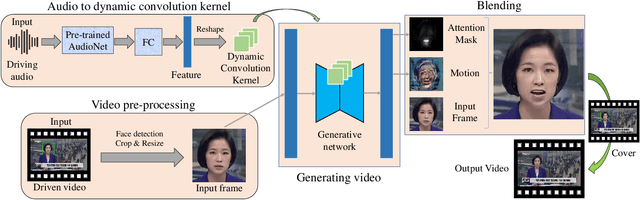
In this paper, we present a dynamic convolution kernel (DCK) strategy for convolutional neural networks. Using a fully convolutional network with the proposed DCKs, high-quality talking-face video can be generated from multi-modal sources (i.e., unmatched audio and video) in real time, and our trained model is robust to different identities, head postures, and input audios. Our proposed DCKs are specially designed for audio-driven talking face video generation, leading to a simple yet effective end-to-end system. We also provide a theoretical analysis to interpret why DCKs work. Experimental results show that our method can generate high-quality talking-face video with background at 60 fps. Comparison and evaluation between our method and the state-of-the-art methods demonstrate the superiority of our method.