 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeature-prompting GBMSeg: One-Shot Reference Guided Training-Free Prompt Engineering for Glomerular Basement Membrane Segmentation
Jun 24, 2024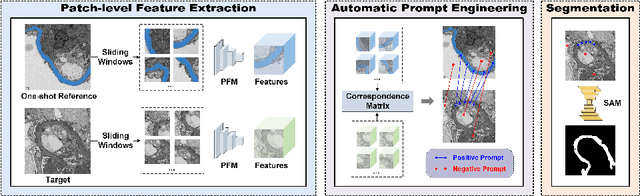

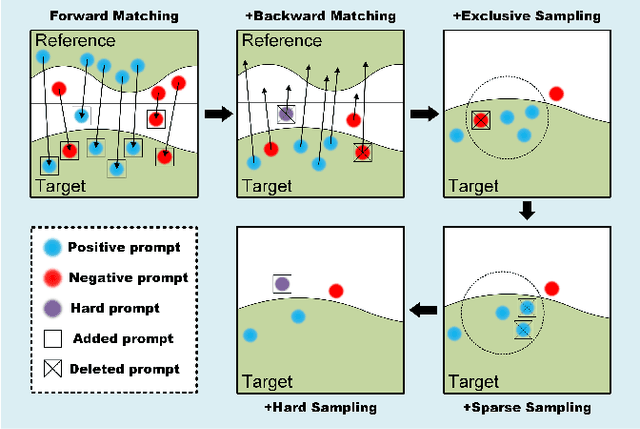

Assessment of the glomerular basement membrane (GBM) in transmission electron microscopy (TEM) is crucial for diagnosing chronic kidney disease (CKD). The lack of domain-independent automatic segmentation tools for the GBM necessitates an AI-based solution to automate the process. In this study, we introduce GBMSeg, a training-free framework designed to automatically segment the GBM in TEM images guided only by a one-shot annotated reference. Specifically, GBMSeg first exploits the robust feature matching capabilities of the pretrained foundation model to generate initial prompt points, then introduces a series of novel automatic prompt engineering techniques across the feature and physical space to optimize the prompt scheme. Finally, GBMSeg employs a class-agnostic foundation segmentation model with the generated prompt scheme to obtain accurate segmentation results. Experimental results on our collected 2538 TEM images confirm that GBMSeg achieves superior segmentation performance with a Dice similarity coefficient (DSC) of 87.27% using only one labeled reference image in a training-free manner, outperforming recently proposed one-shot or few-shot methods. In summary, GBMSeg introduces a distinctive automatic prompt framework that facilitates robust domain-independent segmentation performance without training, particularly advancing the automatic prompting of foundation segmentation models for medical images. Future work involves automating the thickness measurement of segmented GBM and quantifying pathological indicators, holding significant potential for advancing pathology assessments in clinical applications. The source code is available on https://github.com/SnowRain510/GBMSeg
Contextual Knowledge Learning For Dialogue Generation
May 29, 2023
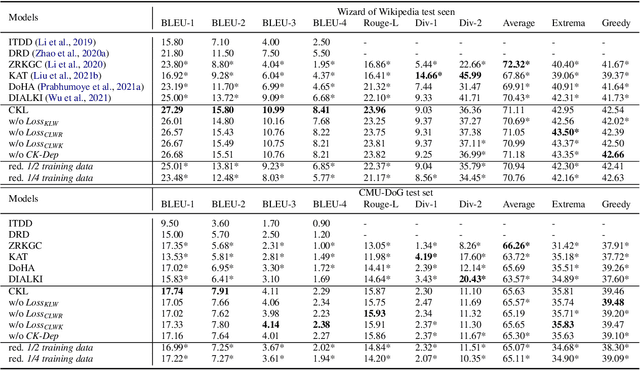
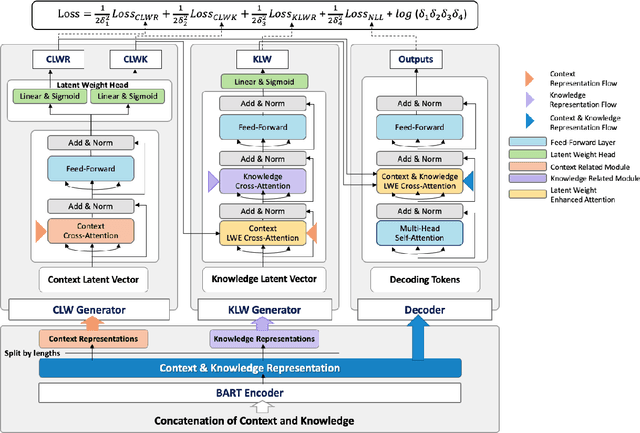
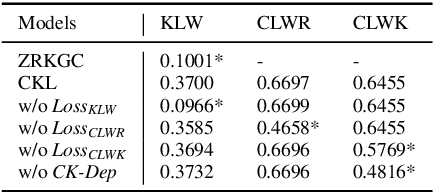
Incorporating conversational context and knowledge into dialogue generation models has been essential for improving the quality of the generated responses. The context, comprising utterances from previous dialogue exchanges, is used as a source of content for response generation and as a means of selecting external knowledge. However, to avoid introducing irrelevant content, it is key to enable fine-grained scoring of context and knowledge. In this paper, we present a novel approach to context and knowledge weighting as an integral part of model training. We guide the model training through a Contextual Knowledge Learning (CKL) process which involves Latent Vectors for context and knowledge, respectively. CKL Latent Vectors capture the relationship between context, knowledge, and responses through weak supervision and enable differential weighting of context utterances and knowledge sentences during the training process. Experiments with two standard datasets and human evaluation demonstrate that CKL leads to a significant improvement compared with the performance of six strong baseline models and shows robustness with regard to reduced sizes of training sets.
Revisiting Long-tailed Image Classification: Survey and Benchmarks with New Evaluation Metrics
Feb 03, 2023



Recently, long-tailed image classification harvests lots of research attention, since the data distribution is long-tailed in many real-world situations. Piles of algorithms are devised to address the data imbalance problem by biasing the training process towards less frequent classes. However, they usually evaluate the performance on a balanced testing set or multiple independent testing sets having distinct distributions with the training data. Considering the testing data may have arbitrary distributions, existing evaluation strategies are unable to reflect the actual classification performance objectively. We set up novel evaluation benchmarks based on a series of testing sets with evolving distributions. A corpus of metrics are designed for measuring the accuracy, robustness, and bounds of algorithms for learning with long-tailed distribution. Based on our benchmarks, we re-evaluate the performance of existing methods on CIFAR10 and CIFAR100 datasets, which is valuable for guiding the selection of data rebalancing techniques. We also revisit existing methods and categorize them into four types including data balancing, feature balancing, loss balancing, and prediction balancing, according the focused procedure during the training pipeline.
Towards Generalizable Graph Contrastive Learning: An Information Theory Perspective
Nov 20, 2022



Graph contrastive learning (GCL) emerges as the most representative approach for graph representation learning, which leverages the principle of maximizing mutual information (InfoMax) to learn node representations applied in downstream tasks. To explore better generalization from GCL to downstream tasks, previous methods heuristically define data augmentation or pretext tasks. However, the generalization ability of GCL and its theoretical principle are still less reported. In this paper, we first propose a metric named GCL-GE for GCL generalization ability. Considering the intractability of the metric due to the agnostic downstream task, we theoretically prove a mutual information upper bound for it from an information-theoretic perspective. Guided by the bound, we design a GCL framework named InfoAdv with enhanced generalization ability, which jointly optimizes the generalization metric and InfoMax to strike the right balance between pretext task fitting and the generalization ability on downstream tasks. We empirically validate our theoretical findings on a number of representative benchmarks, and experimental results demonstrate that our model achieves state-of-the-art performance.
PMP-Net++: Point Cloud Completion by Transformer-Enhanced Multi-step Point Moving Paths
Feb 28, 2022

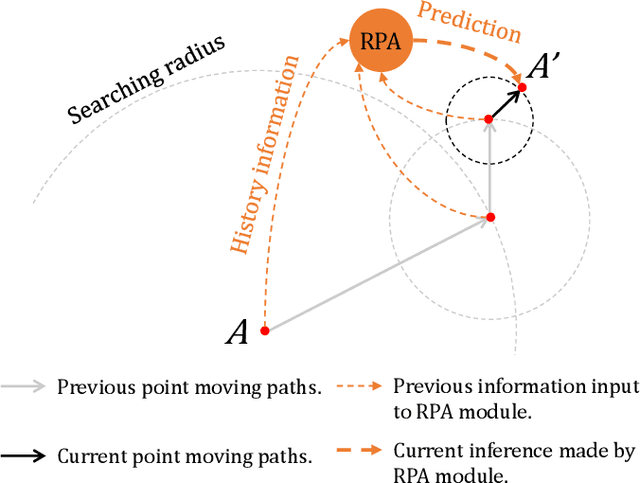

Point cloud completion concerns to predict missing part for incomplete 3D shapes. A common strategy is to generate complete shape according to incomplete input. However, unordered nature of point clouds will degrade generation of high-quality 3D shapes, as detailed topology and structure of unordered points are hard to be captured during the generative process using an extracted latent code. We address this problem by formulating completion as point cloud deformation process. Specifically, we design a novel neural network, named PMP-Net++, to mimic behavior of an earth mover. It moves each point of incomplete input to obtain a complete point cloud, where total distance of point moving paths (PMPs) should be the shortest. Therefore, PMP-Net++ predicts unique PMP for each point according to constraint of point moving distances. The network learns a strict and unique correspondence on point-level, and thus improves quality of predicted complete shape. Moreover, since moving points heavily relies on per-point features learned by network, we further introduce a transformer-enhanced representation learning network, which significantly improves completion performance of PMP-Net++. We conduct comprehensive experiments in shape completion, and further explore application on point cloud up-sampling, which demonstrate non-trivial improvement of PMP-Net++ over state-of-the-art point cloud completion/up-sampling methods.
Snowflake Point Deconvolution for Point Cloud Completion and Generation with Skip-Transformer
Feb 22, 2022Most existing point cloud completion methods suffered from discrete nature of point clouds and unstructured prediction of points in local regions, which makes it hard to reveal fine local geometric details. To resolve this issue, we propose SnowflakeNet with Snowflake Point Deconvolution (SPD) to generate the complete point clouds. SPD models the generation of complete point clouds as the snowflake-like growth of points, where the child points are progressively generated by splitting their parent points after each SPD. Our insight of revealing detailed geometry is to introduce skip-transformer in SPD to learn point splitting patterns which can fit local regions the best. Skip-transformer leverages attention mechanism to summarize the splitting patterns used in previous SPD layer to produce the splitting in current SPD layer. The locally compact and structured point clouds generated by SPD precisely reveal the structure characteristic of 3D shape in local patches, which enables us to predict highly detailed geometries. Moreover, since SPD is a general operation, which is not limited to completion, we further explore the applications of SPD on other generative tasks, including point cloud auto-encoding, generation, single image reconstruction and upsampling. Our experimental results outperform the state-of-the-art methods under widely used benchmarks.
BlendGAN: Implicitly GAN Blending for Arbitrary Stylized Face Generation
Oct 22, 2021



Generative Adversarial Networks (GANs) have made a dramatic leap in high-fidelity image synthesis and stylized face generation. Recently, a layer-swapping mechanism has been developed to improve the stylization performance. However, this method is incapable of fitting arbitrary styles in a single model and requires hundreds of style-consistent training images for each style. To address the above issues, we propose BlendGAN for arbitrary stylized face generation by leveraging a flexible blending strategy and a generic artistic dataset. Specifically, we first train a self-supervised style encoder on the generic artistic dataset to extract the representations of arbitrary styles. In addition, a weighted blending module (WBM) is proposed to blend face and style representations implicitly and control the arbitrary stylization effect. By doing so, BlendGAN can gracefully fit arbitrary styles in a unified model while avoiding case-by-case preparation of style-consistent training images. To this end, we also present a novel large-scale artistic face dataset AAHQ. Extensive experiments demonstrate that BlendGAN outperforms state-of-the-art methods in terms of visual quality and style diversity for both latent-guided and reference-guided stylized face synthesis.
SnowflakeNet: Point Cloud Completion by Snowflake Point Deconvolution with Skip-Transformer
Aug 10, 2021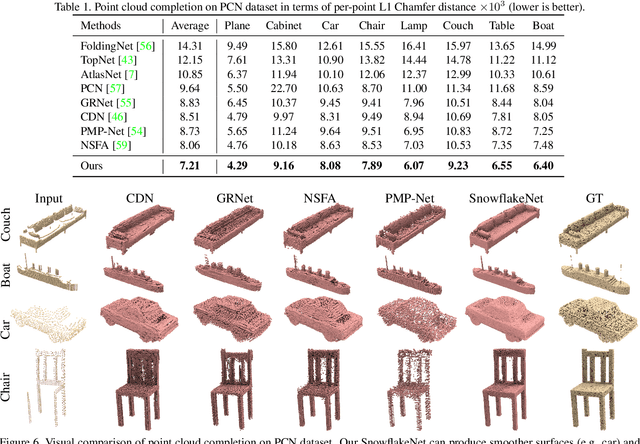

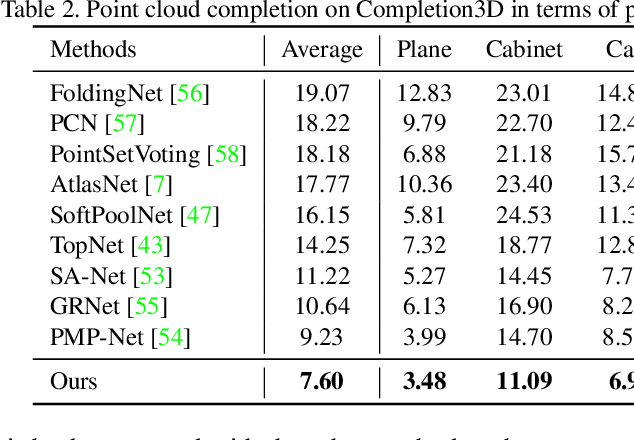
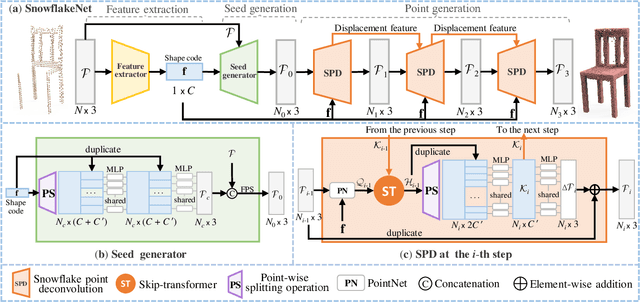
Point cloud completion aims to predict a complete shape in high accuracy from its partial observation. However, previous methods usually suffered from discrete nature of point cloud and unstructured prediction of points in local regions, which makes it hard to reveal fine local geometric details on the complete shape. To resolve this issue, we propose SnowflakeNet with Snowflake Point Deconvolution (SPD) to generate the complete point clouds. The SnowflakeNet models the generation of complete point clouds as the snowflake-like growth of points in 3D space, where the child points are progressively generated by splitting their parent points after each SPD. Our insight of revealing detailed geometry is to introduce skip-transformer in SPD to learn point splitting patterns which can fit local regions the best. Skip-transformer leverages attention mechanism to summarize the splitting patterns used in the previous SPD layer to produce the splitting in the current SPD layer. The locally compact and structured point cloud generated by SPD is able to precisely capture the structure characteristic of 3D shape in local patches, which enables the network to predict highly detailed geometries, such as smooth regions, sharp edges and corners. Our experimental results outperform the state-of-the-art point cloud completion methods under widely used benchmarks. Code will be available at https://github.com/AllenXiangX/SnowflakeNet.
Exploring Set Similarity for Dense Self-supervised Representation Learning
Jul 19, 2021
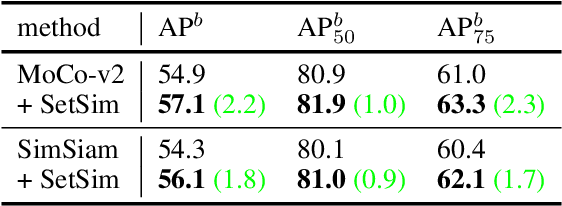
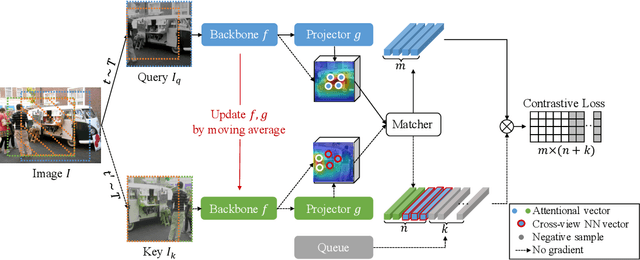

By considering the spatial correspondence, dense self-supervised representation learning has achieved superior performance on various dense prediction tasks. However, the pixel-level correspondence tends to be noisy because of many similar misleading pixels, e.g., backgrounds. To address this issue, in this paper, we propose to explore \textbf{set} \textbf{sim}ilarity (SetSim) for dense self-supervised representation learning. We generalize pixel-wise similarity learning to set-wise one to improve the robustness because sets contain more semantic and structure information. Specifically, by resorting to attentional features of views, we establish corresponding sets, thus filtering out noisy backgrounds that may cause incorrect correspondences. Meanwhile, these attentional features can keep the coherence of the same image across different views to alleviate semantic inconsistency. We further search the cross-view nearest neighbours of sets and employ the structured neighbourhood information to enhance the robustness. Empirical evaluations demonstrate that SetSim is superior to state-of-the-art methods on object detection, keypoint detection, instance segmentation, and semantic segmentation.
Cascade Image Matting with Deformable Graph Refinement
May 08, 2021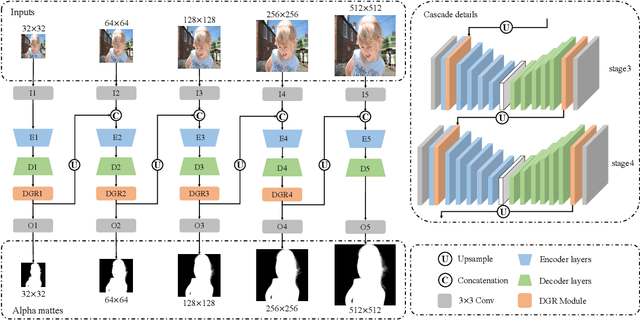



Image matting refers to the estimation of the opacity of foreground objects. It requires correct contours and fine details of foreground objects for the matting results. To better accomplish human image matting tasks, we propose the Cascade Image Matting Network with Deformable Graph Refinement, which can automatically predict precise alpha mattes from single human images without any additional inputs. We adopt a network cascade architecture to perform matting from low-to-high resolution, which corresponds to coarse-to-fine optimization. We also introduce the Deformable Graph Refinement (DGR) module based on graph neural networks (GNNs) to overcome the limitations of convolutional neural networks (CNNs). The DGR module can effectively capture long-range relations and obtain more global and local information to help produce finer alpha mattes. We also reduce the computation complexity of the DGR module by dynamically predicting the neighbors and apply DGR module to higher--resolution features. Experimental results demonstrate the ability of our CasDGR to achieve state-of-the-art performance on synthetic datasets and produce good results on real human images.