 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClinCoT: Clinical-Aware Visual Chain-of-Thought for Medical Vision Language Models
Mar 01, 2026Medical Vision-Language Models have shown promising potential in clinical decision support, yet they remain prone to factual hallucinations due to insufficient grounding in localized pathological evidence. Existing medical alignment methods primarily operate at the response level through preference optimization, improving output correctness but leaving intermediate reasoning weakly connected to visual regions. Although chain-of-thought (CoT) enhances multimodal reasoning, it remains largely text-centric, limiting effective integration of clinical visual cues. To address this gap, we propose ClinCoT, a clinical-aware visual chain-of-thought framework that transforms preference optimization from response-level correction to visual-driven reasoning. We introduce an automatic data generation pipeline that constructs clinically grounded preference pairs through reasoning with hypotheses-driven region proposals. Multiple Med-LLMs evaluators rank and assign scores to each response, and these rankings serve as supervision to train the target model. We further introduce a scoring-based margin-aware optimization strategy that incorporates both preference ranking and score difference to refine region-level reasoning trajectories. To maintain alignment as the model's policy evolves during training, we adopt an iterative learning scheme that dynamically regenerates preference data. Extensive experiments on three medical VQA and report generation benchmarks demonstrate that ClinCoT consistently improves factual grounding and achieves superior performance compared with existing preference-based alignment methods.
Path-Guided Flow Matching for Dataset Distillation
Feb 05, 2026Dataset distillation compresses large datasets into compact synthetic sets with comparable performance in training models. Despite recent progress on diffusion-based distillation, this type of method typically depends on heuristic guidance or prototype assignment, which comes with time-consuming sampling and trajectory instability and thus hurts downstream generalization especially under strong control or low IPC. We propose \emph{Path-Guided Flow Matching (PGFM)}, the first flow matching-based framework for generative distillation, which enables fast deterministic synthesis by solving an ODE in a few steps. PGFM conducts flow matching in the latent space of a frozen VAE to learn class-conditional transport from Gaussian noise to data distribution. Particularly, we develop a continuous path-to-prototype guidance algorithm for ODE-consistent path control, which allows trajectories to reliably land on assigned prototypes while preserving diversity and efficiency. Extensive experiments across high-resolution benchmarks demonstrate that PGFM matches or surpasses prior diffusion-based distillation approaches with fewer steps of sampling while delivering competitive performance with remarkably improved efficiency, e.g., 7.6$\times$ more efficient than the diffusion-based counterparts with 78\% mode coverage.
User-Feedback-Driven Continual Adaptation for Vision-and-Language Navigation
Dec 11, 2025Vision-and-Language Navigation (VLN) requires agents to navigate complex environments by following natural-language instructions. General Scene Adaptation for VLN (GSA-VLN) shifts the focus from zero-shot generalization to continual, environment-specific adaptation, narrowing the gap between static benchmarks and real-world deployment. However, current GSA-VLN frameworks exclude user feedback, relying solely on unsupervised adaptation from repeated environmental exposure. In practice, user feedback offers natural and valuable supervision that can significantly enhance adaptation quality. We introduce a user-feedback-driven adaptation framework that extends GSA-VLN by systematically integrating human interactions into continual learning. Our approach converts user feedback-navigation instructions and corrective signals-into high-quality, environment-aligned training data, enabling efficient and realistic adaptation. A memory-bank warm-start mechanism further reuses previously acquired environmental knowledge, mitigating cold-start degradation and ensuring stable redeployment. Experiments on the GSA-R2R benchmark show that our method consistently surpasses strong baselines such as GR-DUET, improving navigation success and path efficiency. The memory-bank warm start stabilizes early navigation and reduces performance drops after updates. Results under both continual and hybrid adaptation settings confirm the robustness and generality of our framework, demonstrating sustained improvement across diverse deployment conditions.
GeoDM: Geometry-aware Distribution Matching for Dataset Distillation
Dec 10, 2025Dataset distillation aims to synthesize a compact subset of the original data, enabling models trained on it to achieve performance comparable to those trained on the original large dataset. Existing distribution-matching methods are confined to Euclidean spaces, making them only capture linear structures and overlook the intrinsic geometry of real data, e.g., curvature. However, high-dimensional data often lie on low-dimensional manifolds, suggesting that dataset distillation should have the distilled data manifold aligned with the original data manifold. In this work, we propose a geometry-aware distribution-matching framework, called \textbf{GeoDM}, which operates in the Cartesian product of Euclidean, hyperbolic, and spherical manifolds, with flat, hierarchical, and cyclical structures all captured by a unified representation. To adapt to the underlying data geometry, we introduce learnable curvature and weight parameters for three kinds of geometries. At the same time, we design an optimal transport loss to enhance the distribution fidelity. Our theoretical analysis shows that the geometry-aware distribution matching in a product space yields a smaller generalization error bound than the Euclidean counterparts. Extensive experiments conducted on standard benchmarks demonstrate that our algorithm outperforms state-of-the-art data distillation methods and remains effective across various distribution-matching strategies for the single geometries.
When Personalization Tricks Detectors: The Feature-Inversion Trap in Machine-Generated Text Detection
Oct 14, 2025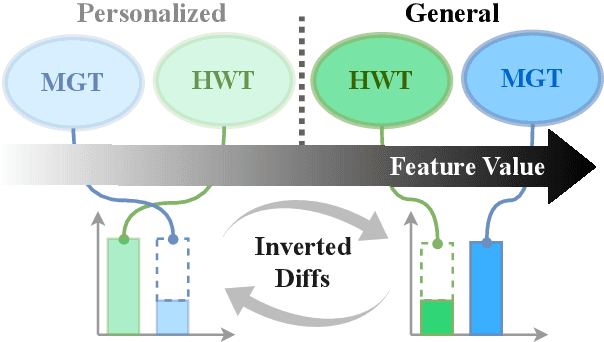

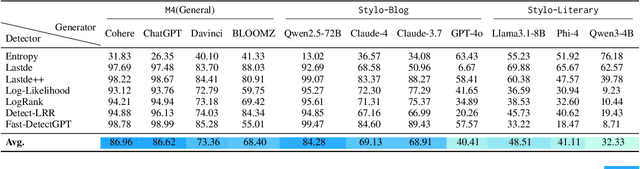
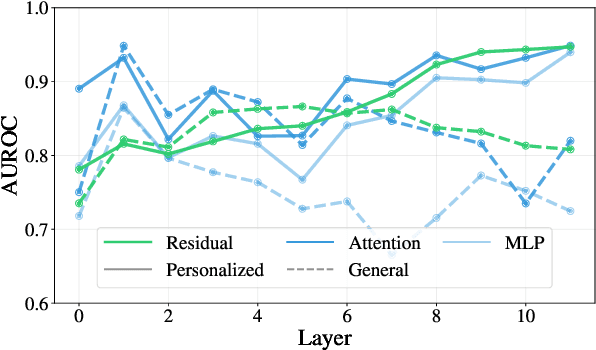
Large language models (LLMs) have grown more powerful in language generation, producing fluent text and even imitating personal style. Yet, this ability also heightens the risk of identity impersonation. To the best of our knowledge, no prior work has examined personalized machine-generated text (MGT) detection. In this paper, we introduce \dataset, the first benchmark for evaluating detector robustness in personalized settings, built from literary and blog texts paired with their LLM-generated imitations. Our experimental results demonstrate large performance gaps across detectors in personalized settings: some state-of-the-art models suffer significant drops. We attribute this limitation to the \textit{feature-inversion trap}, where features that are discriminative in general domains become inverted and misleading when applied to personalized text. Based on this finding, we propose \method, a simple and reliable way to predict detector performance changes in personalized settings. \method identifies latent directions corresponding to inverted features and constructs probe datasets that differ primarily along these features to evaluate detector dependence. Our experiments show that \method can accurately predict both the direction and the magnitude of post-transfer changes, showing 85\% correlation with the actual performance gaps. We hope that this work will encourage further research on personalized text detection.
Quantize More, Lose Less: Autoregressive Generation from Residually Quantized Speech Representations
Jul 16, 2025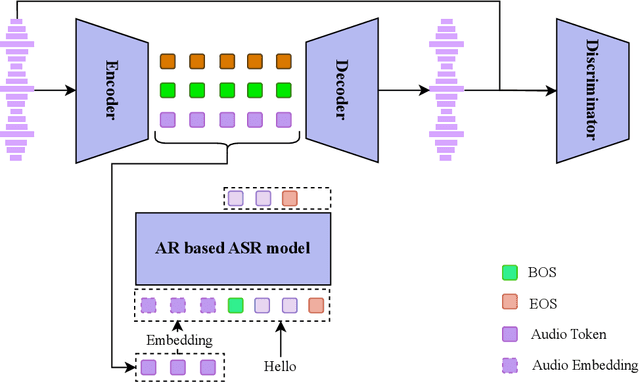

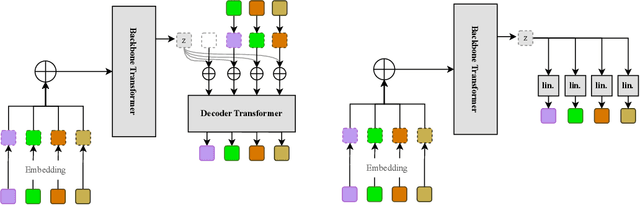
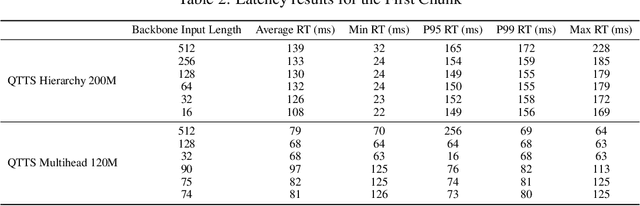
Text-to-speech (TTS) synthesis has seen renewed progress under the discrete modeling paradigm. Existing autoregressive approaches often rely on single-codebook representations, which suffer from significant information loss. Even with post-hoc refinement techniques such as flow matching, these methods fail to recover fine-grained details (e.g., prosodic nuances, speaker-specific timbres), especially in challenging scenarios like singing voice or music synthesis. We propose QTTS, a novel TTS framework built upon our new audio codec, QDAC. The core innovation of QDAC lies in its end-to-end training of an ASR-based auto-regressive network with a GAN, which achieves superior semantic feature disentanglement for scalable, near-lossless compression. QTTS models these discrete codes using two innovative strategies: the Hierarchical Parallel architecture, which uses a dual-AR structure to model inter-codebook dependencies for higher-quality synthesis, and the Delay Multihead approach, which employs parallelized prediction with a fixed delay to accelerate inference speed. Our experiments demonstrate that the proposed framework achieves higher synthesis quality and better preserves expressive content compared to baseline. This suggests that scaling up compression via multi-codebook modeling is a promising direction for high-fidelity, general-purpose speech and audio generation.
Cascade Image Matting with Deformable Graph Refinement
May 08, 2021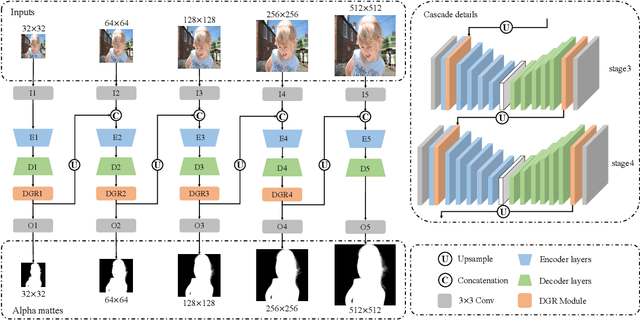



Image matting refers to the estimation of the opacity of foreground objects. It requires correct contours and fine details of foreground objects for the matting results. To better accomplish human image matting tasks, we propose the Cascade Image Matting Network with Deformable Graph Refinement, which can automatically predict precise alpha mattes from single human images without any additional inputs. We adopt a network cascade architecture to perform matting from low-to-high resolution, which corresponds to coarse-to-fine optimization. We also introduce the Deformable Graph Refinement (DGR) module based on graph neural networks (GNNs) to overcome the limitations of convolutional neural networks (CNNs). The DGR module can effectively capture long-range relations and obtain more global and local information to help produce finer alpha mattes. We also reduce the computation complexity of the DGR module by dynamically predicting the neighbors and apply DGR module to higher--resolution features. Experimental results demonstrate the ability of our CasDGR to achieve state-of-the-art performance on synthetic datasets and produce good results on real human images.