 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThinking with Frames: Generative Video Distortion Evaluation via Frame Reward Model
Jan 07, 2026Recent advances in video reward models and post-training strategies have improved text-to-video (T2V) generation. While these models typically assess visual quality, motion quality, and text alignment, they often overlook key structural distortions, such as abnormal object appearances and interactions, which can degrade the overall quality of the generative video. To address this gap, we introduce REACT, a frame-level reward model designed specifically for structural distortions evaluation in generative videos. REACT assigns point-wise scores and attribution labels by reasoning over video frames, focusing on recognizing distortions. To support this, we construct a large-scale human preference dataset, annotated based on our proposed taxonomy of structural distortions, and generate additional data using a efficient Chain-of-Thought (CoT) synthesis pipeline. REACT is trained with a two-stage framework: ((1) supervised fine-tuning with masked loss for domain knowledge injection, followed by (2) reinforcement learning with Group Relative Policy Optimization (GRPO) and pairwise rewards to enhance reasoning capability and align output scores with human preferences. During inference, a dynamic sampling mechanism is introduced to focus on frames most likely to exhibit distortion. We also present REACT-Bench, a benchmark for generative video distortion evaluation. Experimental results demonstrate that REACT complements existing reward models in assessing structutal distortion, achieving both accurate quantitative evaluations and interpretable attribution analysis.
Bridging Cognitive Gap: Hierarchical Description Learning for Artistic Image Aesthetics Assessment
Dec 29, 2025The aesthetic quality assessment task is crucial for developing a human-aligned quantitative evaluation system for AIGC. However, its inherently complex nature, spanning visual perception, cognition, and emotion, poses fundamental challenges. Although aesthetic descriptions offer a viable representation of this complexity, two critical challenges persist: (1) data scarcity and imbalance: existing dataset overly focuses on visual perception and neglects deeper dimensions due to the expensive manual annotation; and (2) model fragmentation: current visual networks isolate aesthetic attributes with multi-branch encoder, while multimodal methods represented by contrastive learning struggle to effectively process long-form textual descriptions. To resolve challenge (1), we first present the Refined Aesthetic Description (RAD) dataset, a large-scale (70k), multi-dimensional structured dataset, generated via an iterative pipeline without heavy annotation costs and easy to scale. To address challenge (2), we propose ArtQuant, an aesthetics assessment framework for artistic images which not only couples isolated aesthetic dimensions through joint description generation, but also better models long-text semantics with the help of LLM decoders. Besides, theoretical analysis confirms this symbiosis: RAD's semantic adequacy (data) and generation paradigm (model) collectively minimize prediction entropy, providing mathematical grounding for the framework. Our approach achieves state-of-the-art performance on several datasets while requiring only 33% of conventional training epochs, narrowing the cognitive gap between artistic images and aesthetic judgment. We will release both code and dataset to support future research.
DiverseGRPO: Mitigating Mode Collapse in Image Generation via Diversity-Aware GRPO
Dec 25, 2025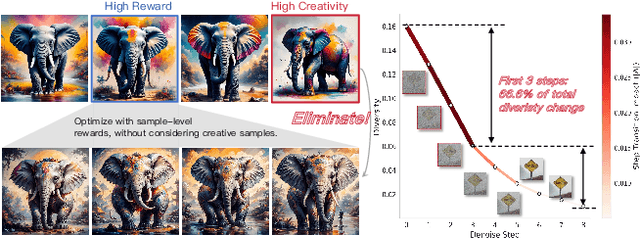



Reinforcement learning (RL), particularly GRPO, improves image generation quality significantly by comparing the relative performance of images generated within the same group. However, in the later stages of training, the model tends to produce homogenized outputs, lacking creativity and visual diversity, which restricts its application scenarios. This issue can be analyzed from both reward modeling and generation dynamics perspectives. First, traditional GRPO relies on single-sample quality as the reward signal, driving the model to converge toward a few high-reward generation modes while neglecting distribution-level diversity. Second, conventional GRPO regularization neglects the dominant role of early-stage denoising in preserving diversity, causing a misaligned regularization budget that limits the achievable quality--diversity trade-off. Motivated by these insights, we revisit the diversity degradation problem from both reward modeling and generation dynamics. At the reward level, we propose a distributional creativity bonus based on semantic grouping. Specifically, we construct a distribution-level representation via spectral clustering over samples generated from the same caption, and adaptively allocate exploratory rewards according to group sizes to encourage the discovery of novel visual modes. At the generation level, we introduce a structure-aware regularization, which enforces stronger early-stage constraints to preserve diversity without compromising reward optimization efficiency. Experiments demonstrate that our method achieves a 13\%--18\% improvement in semantic diversity under matched quality scores, establishing a new Pareto frontier between image quality and diversity for GRPO-based image generation.
Easier Painting Than Thinking: Can Text-to-Image Models Set the Stage, but Not Direct the Play?
Sep 03, 2025Text-to-image (T2I) generation aims to synthesize images from textual prompts, which jointly specify what must be shown and imply what can be inferred, thereby corresponding to two core capabilities: composition and reasoning. However, with the emerging advances of T2I models in reasoning beyond composition, existing benchmarks reveal clear limitations in providing comprehensive evaluations across and within these capabilities. Meanwhile, these advances also enable models to handle more complex prompts, whereas current benchmarks remain limited to low scene density and simplified one-to-one reasoning. To address these limitations, we propose T2I-CoReBench, a comprehensive and complex benchmark that evaluates both composition and reasoning capabilities of T2I models. To ensure comprehensiveness, we structure composition around scene graph elements (instance, attribute, and relation) and reasoning around the philosophical framework of inference (deductive, inductive, and abductive), formulating a 12-dimensional evaluation taxonomy. To increase complexity, driven by the inherent complexities of real-world scenarios, we curate each prompt with high compositional density for composition and multi-step inference for reasoning. We also pair each prompt with a checklist that specifies individual yes/no questions to assess each intended element independently to facilitate fine-grained and reliable evaluation. In statistics, our benchmark comprises 1,080 challenging prompts and around 13,500 checklist questions. Experiments across 27 current T2I models reveal that their composition capability still remains limited in complex high-density scenarios, while the reasoning capability lags even further behind as a critical bottleneck, with all models struggling to infer implicit elements from prompts. Our project page: https://t2i-corebench.github.io/.
StyleMaster: Stylize Your Video with Artistic Generation and Translation
Dec 10, 2024



Style control has been popular in video generation models. Existing methods often generate videos far from the given style, cause content leakage, and struggle to transfer one video to the desired style. Our first observation is that the style extraction stage matters, whereas existing methods emphasize global style but ignore local textures. In order to bring texture features while preventing content leakage, we filter content-related patches while retaining style ones based on prompt-patch similarity; for global style extraction, we generate a paired style dataset through model illusion to facilitate contrastive learning, which greatly enhances the absolute style consistency. Moreover, to fill in the image-to-video gap, we train a lightweight motion adapter on still videos, which implicitly enhances stylization extent, and enables our image-trained model to be seamlessly applied to videos. Benefited from these efforts, our approach, StyleMaster, not only achieves significant improvement in both style resemblance and temporal coherence, but also can easily generalize to video style transfer with a gray tile ControlNet. Extensive experiments and visualizations demonstrate that StyleMaster significantly outperforms competitors, effectively generating high-quality stylized videos that align with textual content and closely resemble the style of reference images. Our project page is at https://zixuan-ye.github.io/stylemaster
Assessing a Single Image in Reference-Guided Image Synthesis
Dec 08, 2021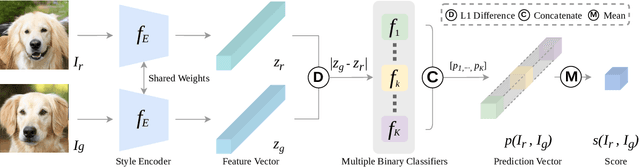
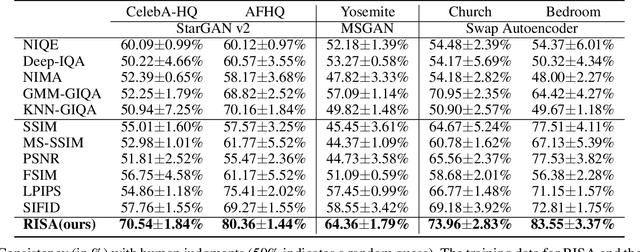

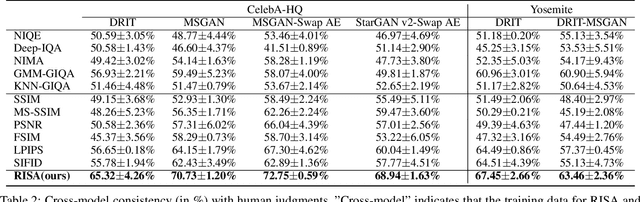
Assessing the performance of Generative Adversarial Networks (GANs) has been an important topic due to its practical significance. Although several evaluation metrics have been proposed, they generally assess the quality of the whole generated image distribution. For Reference-guided Image Synthesis (RIS) tasks, i.e., rendering a source image in the style of another reference image, where assessing the quality of a single generated image is crucial, these metrics are not applicable. In this paper, we propose a general learning-based framework, Reference-guided Image Synthesis Assessment (RISA) to quantitatively evaluate the quality of a single generated image. Notably, the training of RISA does not require human annotations. In specific, the training data for RISA are acquired by the intermediate models from the training procedure in RIS, and weakly annotated by the number of models' iterations, based on the positive correlation between image quality and iterations. As this annotation is too coarse as a supervision signal, we introduce two techniques: 1) a pixel-wise interpolation scheme to refine the coarse labels, and 2) multiple binary classifiers to replace a na\"ive regressor. In addition, an unsupervised contrastive loss is introduced to effectively capture the style similarity between a generated image and its reference image. Empirical results on various datasets demonstrate that RISA is highly consistent with human preference and transfers well across models.
Cascade Image Matting with Deformable Graph Refinement
May 08, 2021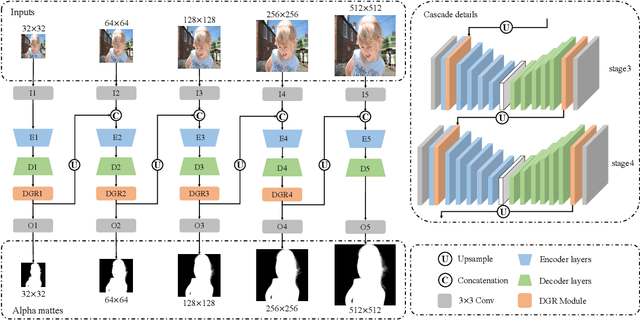



Image matting refers to the estimation of the opacity of foreground objects. It requires correct contours and fine details of foreground objects for the matting results. To better accomplish human image matting tasks, we propose the Cascade Image Matting Network with Deformable Graph Refinement, which can automatically predict precise alpha mattes from single human images without any additional inputs. We adopt a network cascade architecture to perform matting from low-to-high resolution, which corresponds to coarse-to-fine optimization. We also introduce the Deformable Graph Refinement (DGR) module based on graph neural networks (GNNs) to overcome the limitations of convolutional neural networks (CNNs). The DGR module can effectively capture long-range relations and obtain more global and local information to help produce finer alpha mattes. We also reduce the computation complexity of the DGR module by dynamically predicting the neighbors and apply DGR module to higher--resolution features. Experimental results demonstrate the ability of our CasDGR to achieve state-of-the-art performance on synthetic datasets and produce good results on real human images.
Frequency Domain Image Translation: More Photo-realistic, Better Identity-preserving
Dec 01, 2020
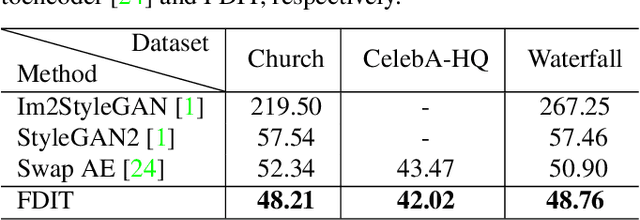
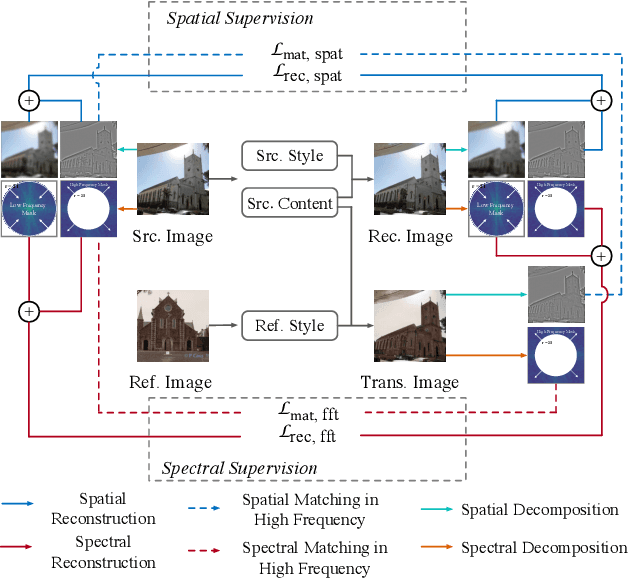
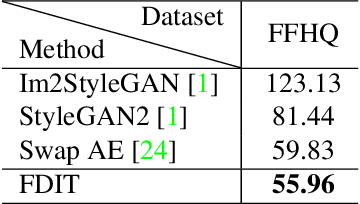
Image-to-image translation aims at translating a particular style of an image to another. The synthesized images can be more photo-realistic and identity-preserving by decomposing the image into content and style in a disentangled manner. While existing models focus on designing specialized network architecture to separate the two components, this paper investigates how to explicitly constrain the content and style statistics of images. We achieve this goal by transforming the input image into high frequency and low frequency information, which correspond to the content and style, respectively. We regulate the frequency distribution from two aspects: a) a spatial level restriction to locally restrict the frequency distribution of images; b) a spectral level regulation to enhance the global consistency among images. On multiple datasets we show that the proposed approach consistently leads to significant improvements on top of various state-of-the-art image translation models.