 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePreciseCache: Precise Feature Caching for Efficient and High-fidelity Video Generation
Mar 03, 2026High computational costs and slow inference hinder the practical application of video generation models. While prior works accelerate the generation process through feature caching, they often suffer from notable quality degradation. In this work, we reveal that this issue arises from their inability to distinguish truly redundant features, which leads to the unintended skipping of computations on important features. To address this, we propose \textbf{PreciseCache}, a plug-and-play framework that precisely detects and skips truly redundant computations, thereby accelerating inference without sacrificing quality. Specifically, PreciseCache contains two components: LFCache for step-wise caching and BlockCache for block-wise caching. For LFCache, we compute the Low-Frequency Difference (LFD) between the prediction features of the current step and those from the previous cached step. Empirically, we observe that LFD serves as an effective measure of step-wise redundancy, accurately detecting highly redundant steps whose computation can be skipped through reusing cached features. To further accelerate generation within each non-skipped step, we propose BlockCache, which precisely detects and skips redundant computations at the block level within the network. Extensive experiments on various backbones demonstrate the effectiveness of our PreciseCache, such as achieving an average of $2.6\times$ speedup on Wan2.1-14B without noticeable quality loss.
Elastic Diffusion Transformer
Feb 15, 2026Diffusion Transformers (DiT) have demonstrated remarkable generative capabilities but remain highly computationally expensive. Previous acceleration methods, such as pruning and distillation, typically rely on a fixed computational capacity, leading to insufficient acceleration and degraded generation quality. To address this limitation, we propose \textbf{Elastic Diffusion Transformer (E-DiT)}, an adaptive acceleration framework for DiT that effectively improves efficiency while maintaining generation quality. Specifically, we observe that the generative process of DiT exhibits substantial sparsity (i.e., some computations can be skipped with minimal impact on quality), and this sparsity varies significantly across samples. Motivated by this observation, E-DiT equips each DiT block with a lightweight router that dynamically identifies sample-dependent sparsity from the input latent. Each router adaptively determines whether the corresponding block can be skipped. If the block is not skipped, the router then predicts the optimal MLP width reduction ratio within the block. During inference, we further introduce a block-level feature caching mechanism that leverages router predictions to eliminate redundant computations in a training-free manner. Extensive experiments across 2D image (Qwen-Image and FLUX) and 3D asset (Hunyuan3D-3.0) demonstrate the effectiveness of E-DiT, achieving up to $\sim$2$\times$ speedup with negligible loss in generation quality. Code will be available at https://github.com/wangjiangshan0725/Elastic-DiT.
Efficient Autoregressive Video Diffusion with Dummy Head
Jan 28, 2026The autoregressive video diffusion model has recently gained considerable research interest due to its causal modeling and iterative denoising. In this work, we identify that the multi-head self-attention in these models under-utilizes historical frames: approximately 25% heads attend almost exclusively to the current frame, and discarding their KV caches incurs only minor performance degradation. Building upon this, we propose Dummy Forcing, a simple yet effective method to control context accessibility across different heads. Specifically, the proposed heterogeneous memory allocation reduces head-wise context redundancy, accompanied by dynamic head programming to adaptively classify head types. Moreover, we develop a context packing technique to achieve more aggressive cache compression. Without additional training, our Dummy Forcing delivers up to 2.0x speedup over the baseline, supporting video generation at 24.3 FPS with less than 0.5% quality drop. Project page is available at https://csguoh.github.io/project/DummyForcing/.
MultiMotion: Multi Subject Video Motion Transfer via Video Diffusion Transformer
Dec 12, 2025Multi-object video motion transfer poses significant challenges for Diffusion Transformer (DiT) architectures due to inherent motion entanglement and lack of object-level control. We present MultiMotion, a novel unified framework that overcomes these limitations. Our core innovation is Maskaware Attention Motion Flow (AMF), which utilizes SAM2 masks to explicitly disentangle and control motion features for multiple objects within the DiT pipeline. Furthermore, we introduce RectPC, a high-order predictor-corrector solver for efficient and accurate sampling, particularly beneficial for multi-entity generation. To facilitate rigorous evaluation, we construct the first benchmark dataset specifically for DiT-based multi-object motion transfer. MultiMotion demonstrably achieves precise, semantically aligned, and temporally coherent motion transfer for multiple distinct objects, maintaining DiT's high quality and scalability. The code is in the supp.
FastVAR: Linear Visual Autoregressive Modeling via Cached Token Pruning
Mar 30, 2025Visual Autoregressive (VAR) modeling has gained popularity for its shift towards next-scale prediction. However, existing VAR paradigms process the entire token map at each scale step, leading to the complexity and runtime scaling dramatically with image resolution. To address this challenge, we propose FastVAR, a post-training acceleration method for efficient resolution scaling with VARs. Our key finding is that the majority of latency arises from the large-scale step where most tokens have already converged. Leveraging this observation, we develop the cached token pruning strategy that only forwards pivotal tokens for scale-specific modeling while using cached tokens from previous scale steps to restore the pruned slots. This significantly reduces the number of forwarded tokens and improves the efficiency at larger resolutions. Experiments show the proposed FastVAR can further speedup FlashAttention-accelerated VAR by 2.7$\times$ with negligible performance drop of <1%. We further extend FastVAR to zero-shot generation of higher resolution images. In particular, FastVAR can generate one 2K image with 15GB memory footprints in 1.5s on a single NVIDIA 3090 GPU. Code is available at https://github.com/csguoh/FastVAR.
ArtCrafter: Text-Image Aligning Style Transfer via Embedding Reframing
Jan 03, 2025



Recent years have witnessed significant advancements in text-guided style transfer, primarily attributed to innovations in diffusion models. These models excel in conditional guidance, utilizing text or images to direct the sampling process. However, despite their capabilities, direct conditional guidance approaches often face challenges in balancing the expressiveness of textual semantics with the diversity of output results while capturing stylistic features. To address these challenges, we introduce ArtCrafter, a novel framework for text-to-image style transfer. Specifically, we introduce an attention-based style extraction module, meticulously engineered to capture the subtle stylistic elements within an image. This module features a multi-layer architecture that leverages the capabilities of perceiver attention mechanisms to integrate fine-grained information. Additionally, we present a novel text-image aligning augmentation component that adeptly balances control over both modalities, enabling the model to efficiently map image and text embeddings into a shared feature space. We achieve this through attention operations that enable smooth information flow between modalities. Lastly, we incorporate an explicit modulation that seamlessly blends multimodal enhanced embeddings with original embeddings through an embedding reframing design, empowering the model to generate diverse outputs. Extensive experiments demonstrate that ArtCrafter yields impressive results in visual stylization, exhibiting exceptional levels of stylistic intensity, controllability, and diversity.
Taming Rectified Flow for Inversion and Editing
Nov 07, 2024



Rectified-flow-based diffusion transformers, such as FLUX and OpenSora, have demonstrated exceptional performance in the field of image and video generation. Despite their robust generative capabilities, these models often suffer from inaccurate inversion, which could further limit their effectiveness in downstream tasks such as image and video editing. To address this issue, we propose RF-Solver, a novel training-free sampler that enhances inversion precision by reducing errors in the process of solving rectified flow ODEs. Specifically, we derive the exact formulation of the rectified flow ODE and perform a high-order Taylor expansion to estimate its nonlinear components, significantly decreasing the approximation error at each timestep. Building upon RF-Solver, we further design RF-Edit, which comprises specialized sub-modules for image and video editing. By sharing self-attention layer features during the editing process, RF-Edit effectively preserves the structural information of the source image or video while achieving high-quality editing results. Our approach is compatible with any pre-trained rectified-flow-based models for image and video tasks, requiring no additional training or optimization. Extensive experiments on text-to-image generation, image & video inversion, and image & video editing demonstrate the robust performance and adaptability of our methods. Code is available at https://github.com/wangjiangshan0725/RF-Solver-Edit.
COVE: Unleashing the Diffusion Feature Correspondence for Consistent Video Editing
Jun 13, 2024
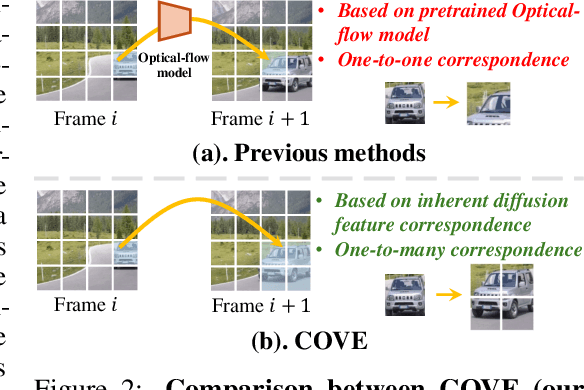

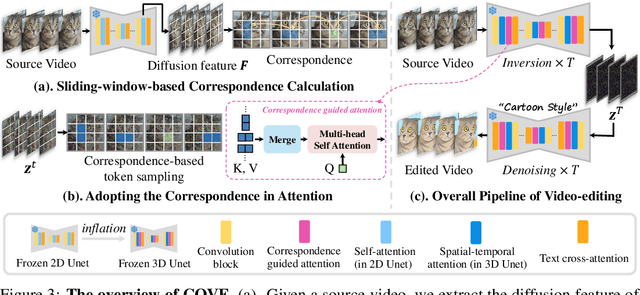
Video editing is an emerging task, in which most current methods adopt the pre-trained text-to-image (T2I) diffusion model to edit the source video in a zero-shot manner. Despite extensive efforts, maintaining the temporal consistency of edited videos remains challenging due to the lack of temporal constraints in the regular T2I diffusion model. To address this issue, we propose COrrespondence-guided Video Editing (COVE), leveraging the inherent diffusion feature correspondence to achieve high-quality and consistent video editing. Specifically, we propose an efficient sliding-window-based strategy to calculate the similarity among tokens in the diffusion features of source videos, identifying the tokens with high correspondence across frames. During the inversion and denoising process, we sample the tokens in noisy latent based on the correspondence and then perform self-attention within them. To save GPU memory usage and accelerate the editing process, we further introduce the temporal-dimensional token merging strategy, which can effectively reduce redundancy. COVE can be seamlessly integrated into the pre-trained T2I diffusion model without the need for extra training or optimization. Extensive experiment results demonstrate that COVE achieves the start-of-the-art performance in various video editing scenarios, outperforming existing methods both quantitatively and qualitatively. The code will be release at https://github.com/wangjiangshan0725/COVE
GrootVL: Tree Topology is All You Need in State Space Model
Jun 04, 2024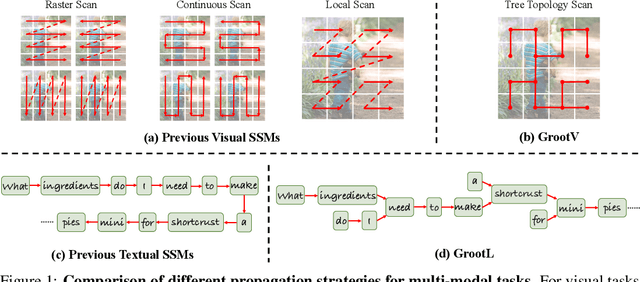
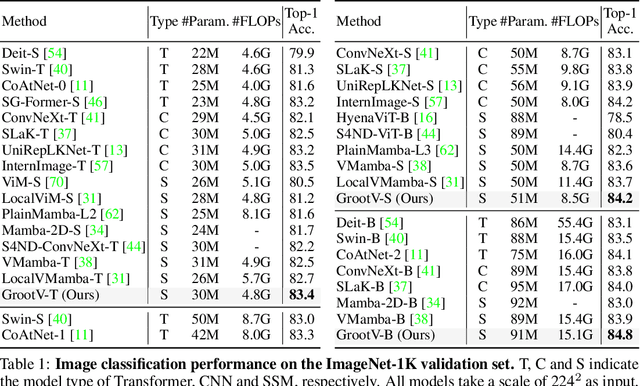
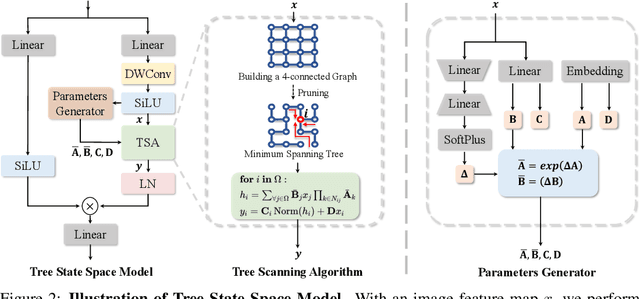
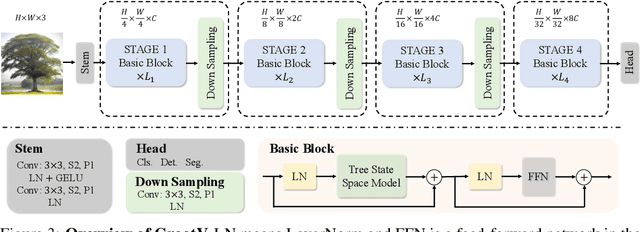
The state space models, employing recursively propagated features, demonstrate strong representation capabilities comparable to Transformer models and superior efficiency. However, constrained by the inherent geometric constraints of sequences, it still falls short in modeling long-range dependencies. To address this issue, we propose the GrootVL network, which first dynamically generates a tree topology based on spatial relationships and input features. Then, feature propagation is performed based on this graph, thereby breaking the original sequence constraints to achieve stronger representation capabilities. Additionally, we introduce a linear complexity dynamic programming algorithm to enhance long-range interactions without increasing computational cost. GrootVL is a versatile multimodal framework that can be applied to both visual and textual tasks. Extensive experiments demonstrate that our method significantly outperforms existing structured state space models on image classification, object detection and segmentation. Besides, by fine-tuning large language models, our approach achieves consistent improvements in multiple textual tasks at minor training cost.
GRA: Detecting Oriented Objects through Group-wise Rotating and Attention
Mar 19, 2024



Oriented object detection, an emerging task in recent years, aims to identify and locate objects across varied orientations. This requires the detector to accurately capture the orientation information, which varies significantly within and across images. Despite the existing substantial efforts, simultaneously ensuring model effectiveness and parameter efficiency remains challenging in this scenario. In this paper, we propose a lightweight yet effective Group-wise Rotating and Attention (GRA) module to replace the convolution operations in backbone networks for oriented object detection. GRA can adaptively capture fine-grained features of objects with diverse orientations, comprising two key components: Group-wise Rotating and Group-wise Attention. Group-wise Rotating first divides the convolution kernel into groups, where each group extracts different object features by rotating at a specific angle according to the object orientation. Subsequently, Group-wise Attention is employed to adaptively enhance the object-related regions in the feature. The collaborative effort of these components enables GRA to effectively capture the various orientation information while maintaining parameter efficiency. Extensive experimental results demonstrate the superiority of our method. For example, GRA achieves a new state-of-the-art (SOTA) on the DOTA-v2.0 benchmark, while saving the parameters by nearly 50% compared to the previous SOTA method. Code will be released.