 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMasked Co-attentional Transformer reconstructs 100x ultra-fast/low-dose whole-body PET from longitudinal images and anatomically guided MRI
May 09, 2022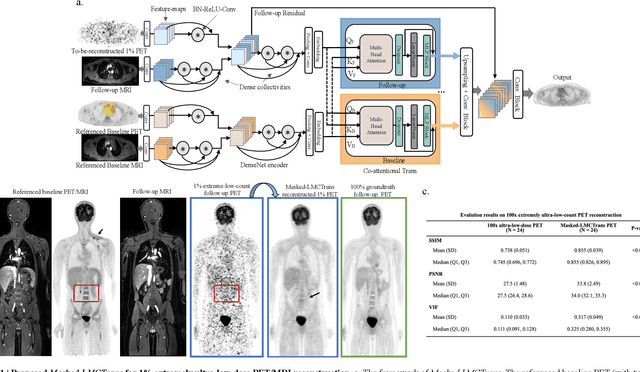
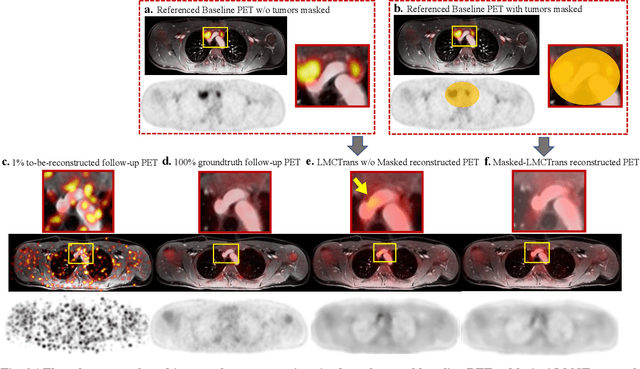
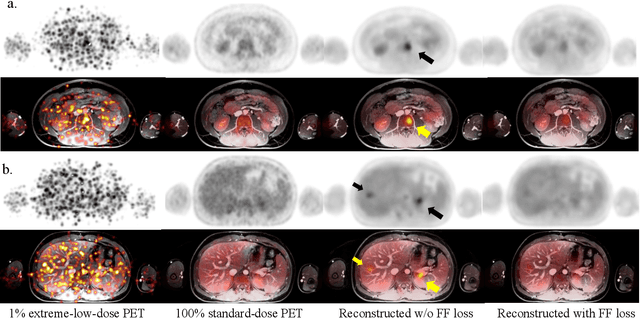
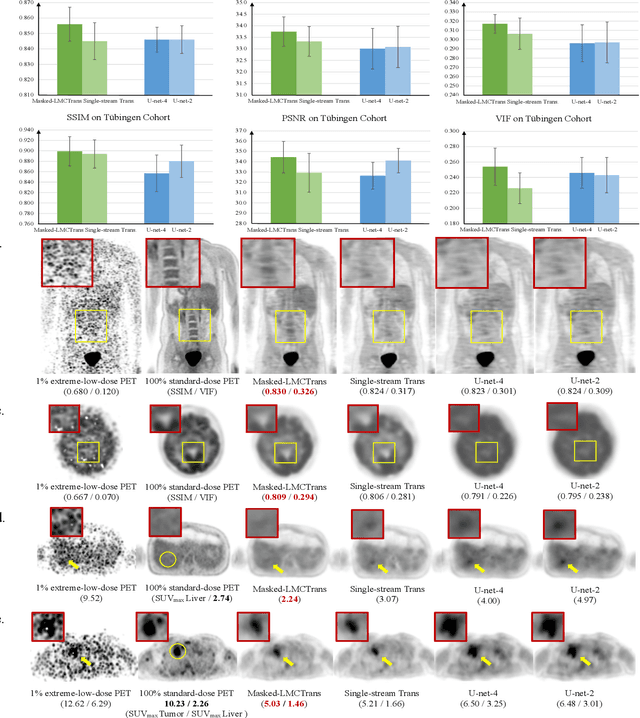
Despite its tremendous value for the diagnosis, treatment monitoring and surveillance of children with cancer, whole body staging with positron emission tomography (PET) is time consuming and associated with considerable radiation exposure. 100x (1% of the standard clinical dosage) ultra-low-dose/ultra-fast whole-body PET reconstruction has the potential for cancer imaging with unprecedented speed and improved safety, but it cannot be achieved by the naive use of machine learning techniques. In this study, we utilize the global similarity between baseline and follow-up PET and magnetic resonance (MR) images to develop Masked-LMCTrans, a longitudinal multi-modality co-attentional CNN-Transformer that provides interaction and joint reasoning between serial PET/MRs of the same patient. We mask the tumor area in the referenced baseline PET and reconstruct the follow-up PET scans. In this manner, Masked-LMCTrans reconstructs 100x almost-zero radio-exposure whole-body PET that was not possible before. The technique also opens a new pathway for longitudinal radiology imaging reconstruction, a significantly under-explored area to date. Our model was trained and tested with Stanford PET/MRI scans of pediatric lymphoma patients and evaluated externally on PET/MRI images from T\"ubingen University. The high image quality of the reconstructed 100x whole-body PET images resulting from the application of Masked-LMCTrans will substantially advance the development of safer imaging approaches and shorter exam-durations for pediatric patients, as well as expand the possibilities for frequent longitudinal monitoring of these patients by PET.
Conditional Generation of Synthetic Geospatial Images from Pixel-level and Feature-level Inputs
Sep 11, 2021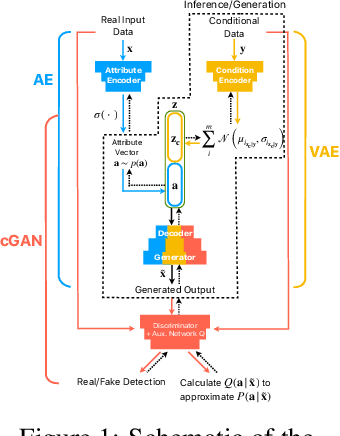
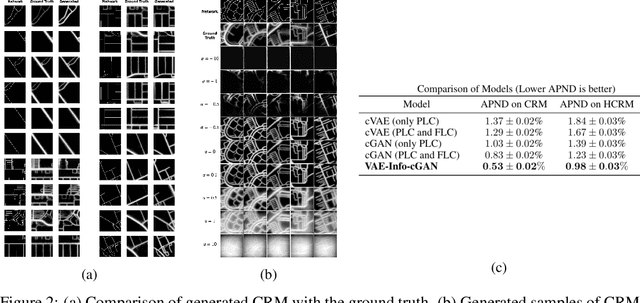
Training robust supervised deep learning models for many geospatial applications of computer vision is difficult due to dearth of class-balanced and diverse training data. Conversely, obtaining enough training data for many applications is financially prohibitive or may be infeasible, especially when the application involves modeling rare or extreme events. Synthetically generating data (and labels) using a generative model that can sample from a target distribution and exploit the multi-scale nature of images can be an inexpensive solution to address scarcity of labeled data. Towards this goal, we present a deep conditional generative model, called VAE-Info-cGAN, that combines a Variational Autoencoder (VAE) with a conditional Information Maximizing Generative Adversarial Network (InfoGAN), for synthesizing semantically rich images simultaneously conditioned on a pixel-level condition (PLC) and a macroscopic feature-level condition (FLC). Dimensionally, the PLC can only vary in the channel dimension from the synthesized image and is meant to be a task-specific input. The FLC is modeled as an attribute vector in the latent space of the generated image which controls the contributions of various characteristic attributes germane to the target distribution. Experiments on a GPS trajectories dataset show that the proposed model can accurately generate various forms of spatiotemporal aggregates across different geographic locations while conditioned only on a raster representation of the road network. The primary intended application of the VAE-Info-cGAN is synthetic data (and label) generation for targeted data augmentation for computer vision-based modeling of problems relevant to geospatial analysis and remote sensing.
VAE-Info-cGAN: Generating Synthetic Images by Combining Pixel-level and Feature-level Geospatial Conditional Inputs
Dec 08, 2020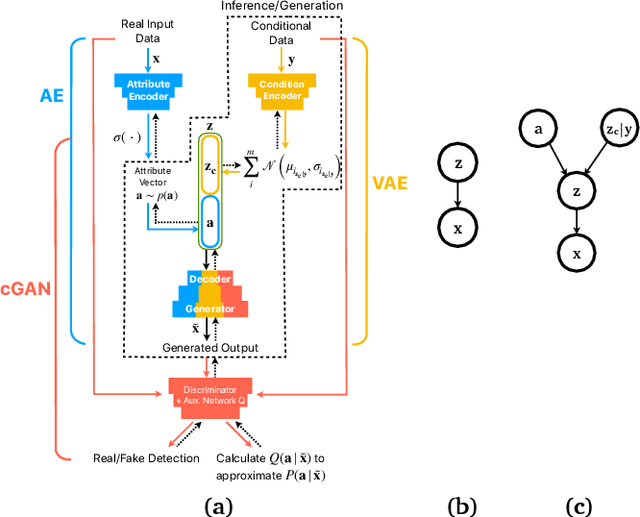
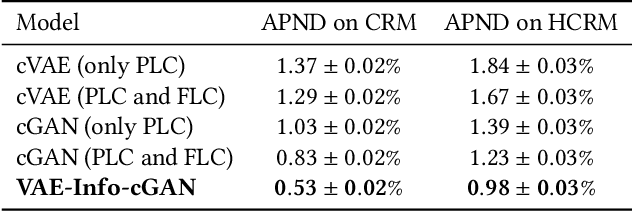


Training robust supervised deep learning models for many geospatial applications of computer vision is difficult due to dearth of class-balanced and diverse training data. Conversely, obtaining enough training data for many applications is financially prohibitive or may be infeasible, especially when the application involves modeling rare or extreme events. Synthetically generating data (and labels) using a generative model that can sample from a target distribution and exploit the multi-scale nature of images can be an inexpensive solution to address scarcity of labeled data. Towards this goal, we present a deep conditional generative model, called VAE-Info-cGAN, that combines a Variational Autoencoder (VAE) with a conditional Information Maximizing Generative Adversarial Network (InfoGAN), for synthesizing semantically rich images simultaneously conditioned on a pixel-level condition (PLC) and a macroscopic feature-level condition (FLC). Dimensionally, the PLC can only vary in the channel dimension from the synthesized image and is meant to be a task-specific input. The FLC is modeled as an attribute vector in the latent space of the generated image which controls the contributions of various characteristic attributes germane to the target distribution. An interpretation of the attribute vector to systematically generate synthetic images by varying a chosen binary macroscopic feature is explored. Experiments on a GPS trajectories dataset show that the proposed model can accurately generate various forms of spatio-temporal aggregates across different geographic locations while conditioned only on a raster representation of the road network. The primary intended application of the VAE-Info-cGAN is synthetic data (and label) generation for targeted data augmentation for computer vision-based modeling of problems relevant to geospatial analysis and remote sensing.
* 10 pages, 4 figures, Peer-reviewed and accepted version of the paper published at the 13th ACM SIGSPATIAL International Workshop on Computational Transportation Science (IWCTS 2020)
Optimizing and Visualizing Deep Learning for Benign/Malignant Classification in Breast Tumors
May 17, 2017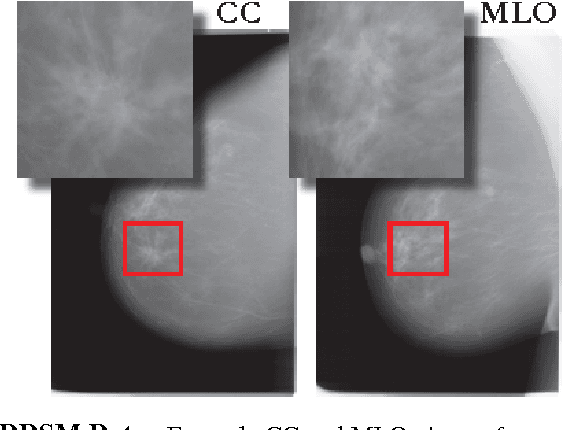
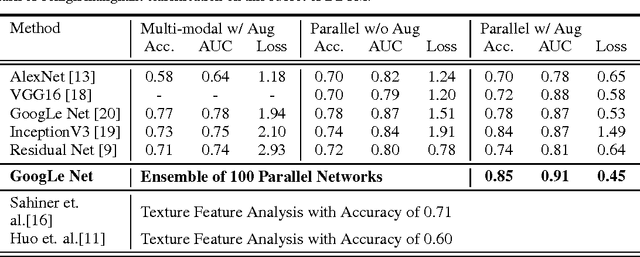
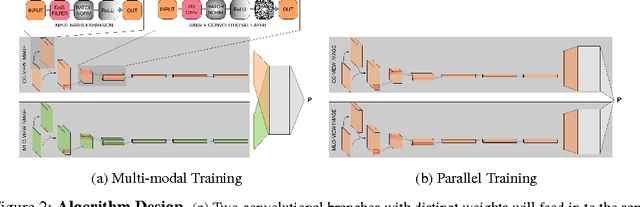
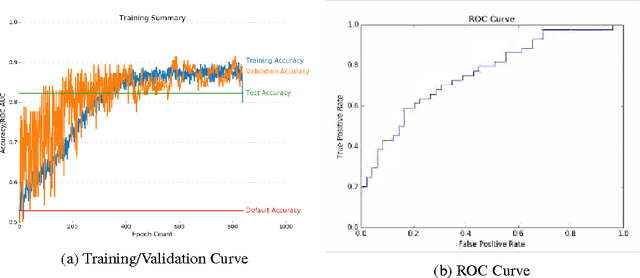
Breast cancer has the highest incidence and second highest mortality rate for women in the US. Our study aims to utilize deep learning for benign/malignant classification of mammogram tumors using a subset of cases from the Digital Database of Screening Mammography (DDSM). Though it was a small dataset from the view of Deep Learning (about 1000 patients), we show that currently state of the art architectures of deep learning can find a robust signal, even when trained from scratch. Using convolutional neural networks (CNNs), we are able to achieve an accuracy of 85% and an ROC AUC of 0.91, while leading hand-crafted feature based methods are only able to achieve an accuracy of 71%. We investigate an amalgamation of architectures to show that our best result is reached with an ensemble of the lightweight GoogLe Nets tasked with interpreting both the coronal caudal view and the mediolateral oblique view, simply averaging the probability scores of both views to make the final prediction. In addition, we have created a novel method to visualize what features the neural network detects for the benign/malignant classification, and have correlated those features with well known radiological features, such as spiculation. Our algorithm significantly improves existing classification methods for mammography lesions and identifies features that correlate with established clinical markers.