 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVAE-Info-cGAN: Generating Synthetic Images by Combining Pixel-level and Feature-level Geospatial Conditional Inputs
Paper and Code
Dec 08, 2020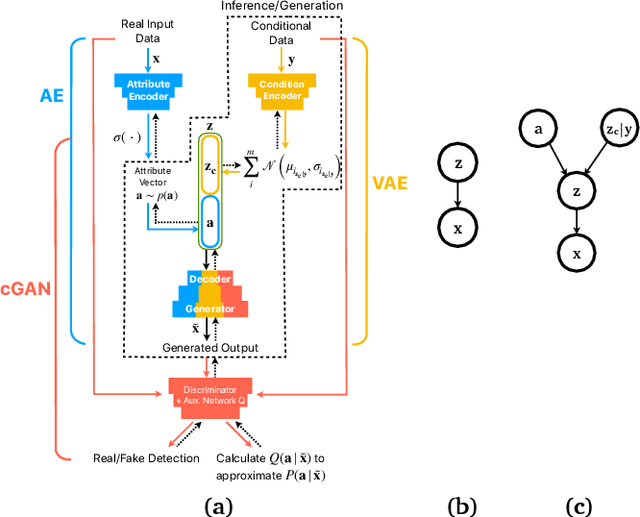
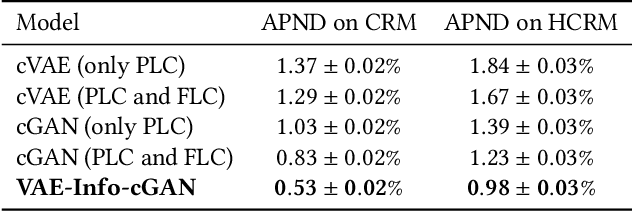


Training robust supervised deep learning models for many geospatial applications of computer vision is difficult due to dearth of class-balanced and diverse training data. Conversely, obtaining enough training data for many applications is financially prohibitive or may be infeasible, especially when the application involves modeling rare or extreme events. Synthetically generating data (and labels) using a generative model that can sample from a target distribution and exploit the multi-scale nature of images can be an inexpensive solution to address scarcity of labeled data. Towards this goal, we present a deep conditional generative model, called VAE-Info-cGAN, that combines a Variational Autoencoder (VAE) with a conditional Information Maximizing Generative Adversarial Network (InfoGAN), for synthesizing semantically rich images simultaneously conditioned on a pixel-level condition (PLC) and a macroscopic feature-level condition (FLC). Dimensionally, the PLC can only vary in the channel dimension from the synthesized image and is meant to be a task-specific input. The FLC is modeled as an attribute vector in the latent space of the generated image which controls the contributions of various characteristic attributes germane to the target distribution. An interpretation of the attribute vector to systematically generate synthetic images by varying a chosen binary macroscopic feature is explored. Experiments on a GPS trajectories dataset show that the proposed model can accurately generate various forms of spatio-temporal aggregates across different geographic locations while conditioned only on a raster representation of the road network. The primary intended application of the VAE-Info-cGAN is synthetic data (and label) generation for targeted data augmentation for computer vision-based modeling of problems relevant to geospatial analysis and remote sensing.