 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCP Loss: Channel-wise Perceptual Loss for Time Series Forecasting
Jan 25, 2026Multi-channel time-series data, prevalent across diverse applications, is characterized by significant heterogeneity in its different channels. However, existing forecasting models are typically guided by channel-agnostic loss functions like MSE, which apply a uniform metric across all channels. This often leads to fail to capture channel-specific dynamics such as sharp fluctuations or trend shifts. To address this, we propose a Channel-wise Perceptual Loss (CP Loss). Its core idea is to learn a unique perceptual space for each channel that is adapted to its characteristics, and to compute the loss within this space. Specifically, we first design a learnable channel-wise filter that decomposes the raw signal into disentangled multi-scale representations, which form the basis of our perceptual space. Crucially, the filter is optimized jointly with the main forecasting model, ensuring that the learned perceptual space is explicitly oriented towards the prediction task. Finally, losses are calculated within these perception spaces to optimize the model. Code is available at https://github.com/zyh16143998882/CP_Loss.
CASL: Curvature-Augmented Self-supervised Learning for 3D Anomaly Detection
Nov 17, 2025Deep learning-based 3D anomaly detection methods have demonstrated significant potential in industrial manufacturing. However, many approaches are specifically designed for anomaly detection tasks, which limits their generalizability to other 3D understanding tasks. In contrast, self-supervised point cloud models aim for general-purpose representation learning, yet our investigation reveals that these classical models are suboptimal at anomaly detection under the unified fine-tuning paradigm. This motivates us to develop a more generalizable 3D model that can effectively detect anomalies without relying on task-specific designs. Interestingly, we find that using only the curvature of each point as its anomaly score already outperforms several classical self-supervised and dedicated anomaly detection models, highlighting the critical role of curvature in 3D anomaly detection. In this paper, we propose a Curvature-Augmented Self-supervised Learning (CASL) framework based on a reconstruction paradigm. Built upon the classical U-Net architecture, our approach introduces multi-scale curvature prompts to guide the decoder in predicting the spatial coordinates of each point. Without relying on any dedicated anomaly detection mechanisms, it achieves leading detection performance through straightforward anomaly classification fine-tuning. Moreover, the learned representations generalize well to standard 3D understanding tasks such as point cloud classification. The code is available at https://github.com/zyh16143998882/CASL.
Improving Deepfake Detection with Reinforcement Learning-Based Adaptive Data Augmentation
Nov 10, 2025The generalization capability of deepfake detectors is critical for real-world use. Data augmentation via synthetic fake face generation effectively enhances generalization, yet current SoTA methods rely on fixed strategies-raising a key question: Is a single static augmentation sufficient, or does the diversity of forgery features demand dynamic approaches? We argue existing methods overlook the evolving complexity of real-world forgeries (e.g., facial warping, expression manipulation), which fixed policies cannot fully simulate. To address this, we propose CRDA (Curriculum Reinforcement-Learning Data Augmentation), a novel framework guiding detectors to progressively master multi-domain forgery features from simple to complex. CRDA synthesizes augmented samples via a configurable pool of forgery operations and dynamically generates adversarial samples tailored to the detector's current learning state. Central to our approach is integrating reinforcement learning (RL) and causal inference. An RL agent dynamically selects augmentation actions based on detector performance to efficiently explore the vast augmentation space, adapting to increasingly challenging forgeries. Simultaneously, the agent introduces action space variations to generate heterogeneous forgery patterns, guided by causal inference to mitigate spurious correlations-suppressing task-irrelevant biases and focusing on causally invariant features. This integration ensures robust generalization by decoupling synthetic augmentation patterns from the model's learned representations. Extensive experiments show our method significantly improves detector generalizability, outperforming SOTA methods across multiple cross-domain datasets.
PMA: Towards Parameter-Efficient Point Cloud Understanding via Point Mamba Adapter
May 27, 2025Applying pre-trained models to assist point cloud understanding has recently become a mainstream paradigm in 3D perception. However, existing application strategies are straightforward, utilizing only the final output of the pre-trained model for various task heads. It neglects the rich complementary information in the intermediate layer, thereby failing to fully unlock the potential of pre-trained models. To overcome this limitation, we propose an orthogonal solution: Point Mamba Adapter (PMA), which constructs an ordered feature sequence from all layers of the pre-trained model and leverages Mamba to fuse all complementary semantics, thereby promoting comprehensive point cloud understanding. Constructing this ordered sequence is non-trivial due to the inherent isotropy of 3D space. Therefore, we further propose a geometry-constrained gate prompt generator (G2PG) shared across different layers, which applies shared geometric constraints to the output gates of the Mamba and dynamically optimizes the spatial order, thus enabling more effective integration of multi-layer information. Extensive experiments conducted on challenging point cloud datasets across various tasks demonstrate that our PMA elevates the capability for point cloud understanding to a new level by fusing diverse complementary intermediate features. Code is available at https://github.com/zyh16143998882/PMA.
EvdCLIP: Improving Vision-Language Retrieval with Entity Visual Descriptions from Large Language Models
May 24, 2025Vision-language retrieval (VLR) has attracted significant attention in both academia and industry, which involves using text (or images) as queries to retrieve corresponding images (or text). However, existing methods often neglect the rich visual semantics knowledge of entities, thus leading to incorrect retrieval results. To address this problem, we propose the Entity Visual Description enhanced CLIP (EvdCLIP), designed to leverage the visual knowledge of entities to enrich queries. Specifically, since humans recognize entities through visual cues, we employ a large language model (LLM) to generate Entity Visual Descriptions (EVDs) as alignment cues to complement textual data. These EVDs are then integrated into raw queries to create visually-rich, EVD-enhanced queries. Furthermore, recognizing that EVD-enhanced queries may introduce noise or low-quality expansions, we develop a novel, trainable EVD-aware Rewriter (EaRW) for vision-language retrieval tasks. EaRW utilizes EVD knowledge and the generative capabilities of the language model to effectively rewrite queries. With our specialized training strategy, EaRW can generate high-quality and low-noise EVD-enhanced queries. Extensive quantitative and qualitative experiments on image-text retrieval benchmarks validate the superiority of EvdCLIP on vision-language retrieval tasks.
Logic-of-Thought: Empowering Large Language Models with Logic Programs for Solving Puzzles in Natural Language
May 22, 2025Solving puzzles in natural language poses a long-standing challenge in AI. While large language models (LLMs) have recently shown impressive capabilities in a variety of tasks, they continue to struggle with complex puzzles that demand precise reasoning and exhaustive search. In this paper, we propose Logic-of-Thought (Logot), a novel framework that bridges LLMs with logic programming to address this problem. Our method leverages LLMs to translate puzzle rules and states into answer set programs (ASPs), the solution of which are then accurately and efficiently inferred by an ASP interpreter. This hybrid approach combines the natural language understanding of LLMs with the precise reasoning capabilities of logic programs. We evaluate our method on various grid puzzles and dynamic puzzles involving actions, demonstrating near-perfect accuracy across all tasks. Our code and data are available at: https://github.com/naiqili/Logic-of-Thought.
Efficient Differentiable Approximation of Generalized Low-rank Regularization
May 21, 2025Low-rank regularization (LRR) has been widely applied in various machine learning tasks, but the associated optimization is challenging. Directly optimizing the rank function under constraints is NP-hard in general. To overcome this difficulty, various relaxations of the rank function were studied. However, optimization of these relaxed LRRs typically depends on singular value decomposition, which is a time-consuming and nondifferentiable operator that cannot be optimized with gradient-based techniques. To address these challenges, in this paper we propose an efficient differentiable approximation of the generalized LRR. The considered LRR form subsumes many popular choices like the nuclear norm, the Schatten-$p$ norm, and various nonconvex relaxations. Our method enables LRR terms to be appended to loss functions in a plug-and-play fashion, and the GPU-friendly operations enable efficient and convenient implementation. Furthermore, convergence analysis is presented, which rigorously shows that both the bias and the variance of our rank estimator rapidly reduce with increased sample size and iteration steps. In the experimental study, the proposed method is applied to various tasks, which demonstrates its versatility and efficiency. Code is available at https://github.com/naiqili/EDLRR.
MC3D-AD: A Unified Geometry-aware Reconstruction Model for Multi-category 3D Anomaly Detection
May 04, 2025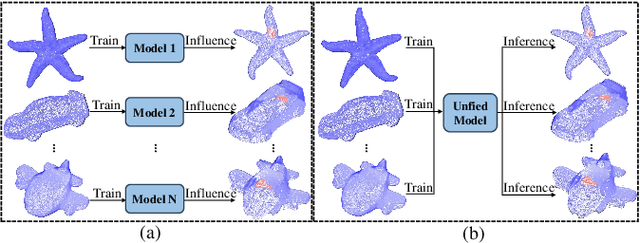
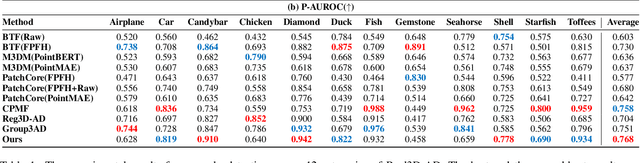
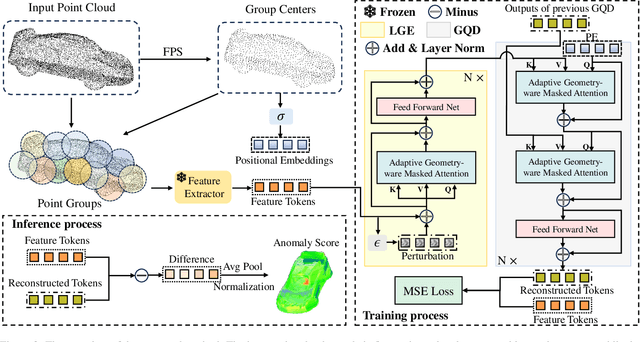
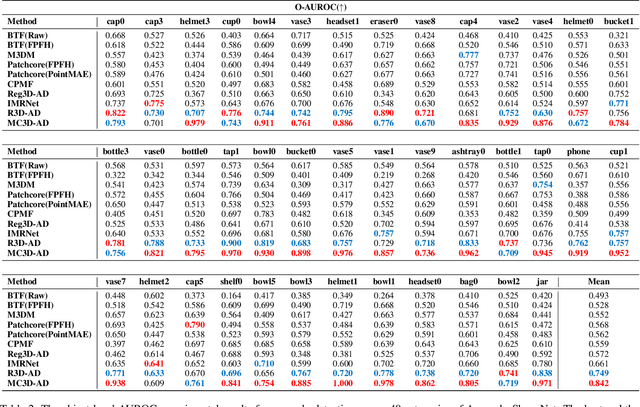
3D Anomaly Detection (AD) is a promising means of controlling the quality of manufactured products. However, existing methods typically require carefully training a task-specific model for each category independently, leading to high cost, low efficiency, and weak generalization. Therefore, this paper presents a novel unified model for Multi-Category 3D Anomaly Detection (MC3D-AD) that aims to utilize both local and global geometry-aware information to reconstruct normal representations of all categories. First, to learn robust and generalized features of different categories, we propose an adaptive geometry-aware masked attention module that extracts geometry variation information to guide mask attention. Then, we introduce a local geometry-aware encoder reinforced by the improved mask attention to encode group-level feature tokens. Finally, we design a global query decoder that utilizes point cloud position embeddings to improve the decoding process and reconstruction ability. This leads to local and global geometry-aware reconstructed feature tokens for the AD task. MC3D-AD is evaluated on two publicly available Real3D-AD and Anomaly-ShapeNet datasets, and exhibits significant superiority over current state-of-the-art single-category methods, achieving 3.1\% and 9.3\% improvement in object-level AUROC over Real3D-AD and Anomaly-ShapeNet, respectively. The source code will be released upon acceptance.
Embracing Collaboration Over Competition: Condensing Multiple Prompts for Visual In-Context Learning
Apr 30, 2025Visual In-Context Learning (VICL) enables adaptively solving vision tasks by leveraging pixel demonstrations, mimicking human-like task completion through analogy. Prompt selection is critical in VICL, but current methods assume the existence of a single "ideal" prompt in a pool of candidates, which in practice may not hold true. Multiple suitable prompts may exist, but individually they often fall short, leading to difficulties in selection and the exclusion of useful context. To address this, we propose a new perspective: prompt condensation. Rather than relying on a single prompt, candidate prompts collaborate to efficiently integrate informative contexts without sacrificing resolution. We devise Condenser, a lightweight external plugin that compresses relevant fine-grained context across multiple prompts. Optimized end-to-end with the backbone, Condenser ensures accurate integration of contextual cues. Experiments demonstrate Condenser outperforms state-of-the-arts across benchmark tasks, showing superior context compression, scalability with more prompts, and enhanced computational efficiency compared to ensemble methods, positioning it as a highly competitive solution for VICL. Code is open-sourced at https://github.com/gimpong/CVPR25-Condenser.
FastVAR: Linear Visual Autoregressive Modeling via Cached Token Pruning
Mar 30, 2025Visual Autoregressive (VAR) modeling has gained popularity for its shift towards next-scale prediction. However, existing VAR paradigms process the entire token map at each scale step, leading to the complexity and runtime scaling dramatically with image resolution. To address this challenge, we propose FastVAR, a post-training acceleration method for efficient resolution scaling with VARs. Our key finding is that the majority of latency arises from the large-scale step where most tokens have already converged. Leveraging this observation, we develop the cached token pruning strategy that only forwards pivotal tokens for scale-specific modeling while using cached tokens from previous scale steps to restore the pruned slots. This significantly reduces the number of forwarded tokens and improves the efficiency at larger resolutions. Experiments show the proposed FastVAR can further speedup FlashAttention-accelerated VAR by 2.7$\times$ with negligible performance drop of <1%. We further extend FastVAR to zero-shot generation of higher resolution images. In particular, FastVAR can generate one 2K image with 15GB memory footprints in 1.5s on a single NVIDIA 3090 GPU. Code is available at https://github.com/csguoh/FastVAR.