 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHeterogeneous Uncertainty-Guided Composed Image Retrieval with Fine-Grained Probabilistic Learning
Jan 16, 2026Composed Image Retrieval (CIR) enables image search by combining a reference image with modification text. Intrinsic noise in CIR triplets incurs intrinsic uncertainty and threatens the model's robustness. Probabilistic learning approaches have shown promise in addressing such issues; however, they fall short for CIR due to their instance-level holistic modeling and homogeneous treatment of queries and targets. This paper introduces a Heterogeneous Uncertainty-Guided (HUG) paradigm to overcome these limitations. HUG utilizes a fine-grained probabilistic learning framework, where queries and targets are represented by Gaussian embeddings that capture detailed concepts and uncertainties. We customize heterogeneous uncertainty estimations for multi-modal queries and uni-modal targets. Given a query, we capture uncertainties not only regarding uni-modal content quality but also multi-modal coordination, followed by a provable dynamic weighting mechanism to derive comprehensive query uncertainty. We further design uncertainty-guided objectives, including query-target holistic contrast and fine-grained contrasts with comprehensive negative sampling strategies, which effectively enhance discriminative learning. Experiments on benchmarks demonstrate HUG's effectiveness beyond state-of-the-art baselines, with faithful analysis justifying the technical contributions.
Embracing Collaboration Over Competition: Condensing Multiple Prompts for Visual In-Context Learning
Apr 30, 2025Visual In-Context Learning (VICL) enables adaptively solving vision tasks by leveraging pixel demonstrations, mimicking human-like task completion through analogy. Prompt selection is critical in VICL, but current methods assume the existence of a single "ideal" prompt in a pool of candidates, which in practice may not hold true. Multiple suitable prompts may exist, but individually they often fall short, leading to difficulties in selection and the exclusion of useful context. To address this, we propose a new perspective: prompt condensation. Rather than relying on a single prompt, candidate prompts collaborate to efficiently integrate informative contexts without sacrificing resolution. We devise Condenser, a lightweight external plugin that compresses relevant fine-grained context across multiple prompts. Optimized end-to-end with the backbone, Condenser ensures accurate integration of contextual cues. Experiments demonstrate Condenser outperforms state-of-the-arts across benchmark tasks, showing superior context compression, scalability with more prompts, and enhanced computational efficiency compared to ensemble methods, positioning it as a highly competitive solution for VICL. Code is open-sourced at https://github.com/gimpong/CVPR25-Condenser.
AutoSSVH: Exploring Automated Frame Sampling for Efficient Self-Supervised Video Hashing
Apr 04, 2025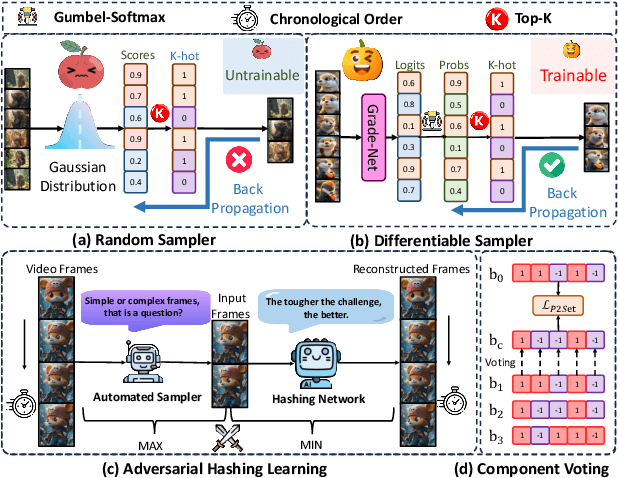

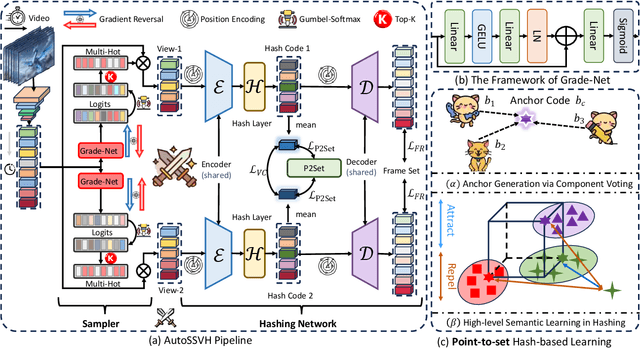
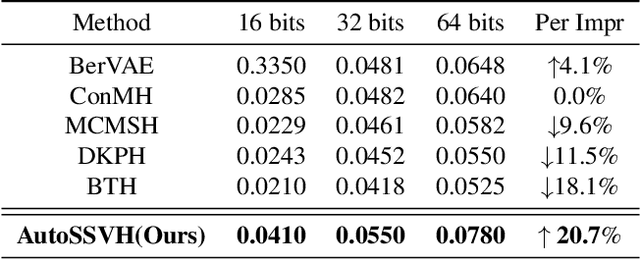
Self-Supervised Video Hashing (SSVH) compresses videos into hash codes for efficient indexing and retrieval using unlabeled training videos. Existing approaches rely on random frame sampling to learn video features and treat all frames equally. This results in suboptimal hash codes, as it ignores frame-specific information density and reconstruction difficulty. To address this limitation, we propose a new framework, termed AutoSSVH, that employs adversarial frame sampling with hash-based contrastive learning. Our adversarial sampling strategy automatically identifies and selects challenging frames with richer information for reconstruction, enhancing encoding capability. Additionally, we introduce a hash component voting strategy and a point-to-set (P2Set) hash-based contrastive objective, which help capture complex inter-video semantic relationships in the Hamming space and improve the discriminability of learned hash codes. Extensive experiments demonstrate that AutoSSVH achieves superior retrieval efficacy and efficiency compared to state-of-the-art approaches. Code is available at https://github.com/EliSpectre/CVPR25-AutoSSVH.
Towards Scalable Semantic Representation for Recommendation
Oct 12, 2024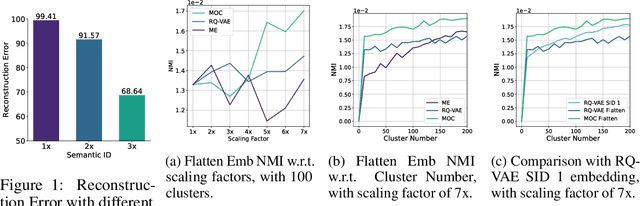
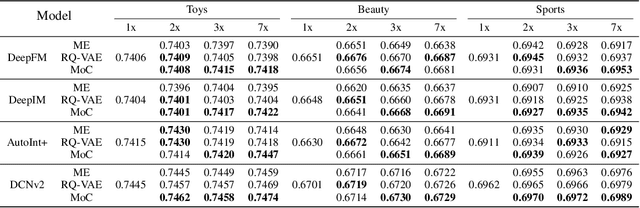
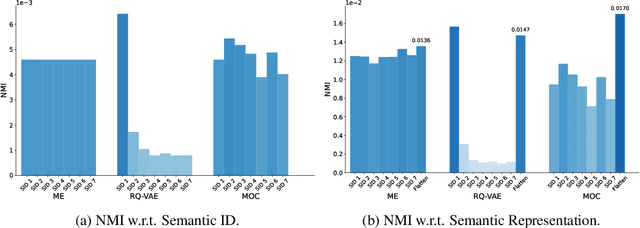
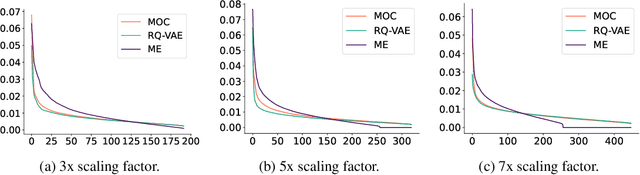
With recent advances in large language models (LLMs), there has been emerging numbers of research in developing Semantic IDs based on LLMs to enhance the performance of recommendation systems. However, the dimension of these embeddings needs to match that of the ID embedding in recommendation, which is usually much smaller than the original length. Such dimension compression results in inevitable losses in discriminability and dimension robustness of the LLM embeddings, which motivates us to scale up the semantic representation. In this paper, we propose Mixture-of-Codes, which first constructs multiple independent codebooks for LLM representation in the indexing stage, and then utilizes the Semantic Representation along with a fusion module for the downstream recommendation stage. Extensive analysis and experiments demonstrate that our method achieves superior discriminability and dimension robustness scalability, leading to the best scale-up performance in recommendations.
GMMFormer v2: An Uncertainty-aware Framework for Partially Relevant Video Retrieval
May 22, 2024



Given a text query, partially relevant video retrieval (PRVR) aims to retrieve untrimmed videos containing relevant moments. Due to the lack of moment annotations, the uncertainty lying in clip modeling and text-clip correspondence leads to major challenges. Despite the great progress, existing solutions either sacrifice efficiency or efficacy to capture varying and uncertain video moments. What's worse, few methods have paid attention to the text-clip matching pattern under such uncertainty, exposing the risk of semantic collapse. To address these issues, we present GMMFormer v2, an uncertainty-aware framework for PRVR. For clip modeling, we improve a strong baseline GMMFormer with a novel temporal consolidation module upon multi-scale contextual features, which maintains efficiency and improves the perception for varying moments. To achieve uncertainty-aware text-clip matching, we upgrade the query diverse loss in GMMFormer to facilitate fine-grained uniformity and propose a novel optimal matching loss for fine-grained text-clip alignment. Their collaboration alleviates the semantic collapse phenomenon and neatly promotes accurate correspondence between texts and moments. We conduct extensive experiments and ablation studies on three PRVR benchmarks, demonstrating remarkable improvement of GMMFormer v2 compared to the past SOTA competitor and the versatility of uncertainty-aware text-clip matching for PRVR. Code is available at \url{https://github.com/huangmozhi9527/GMMFormer_v2}.