 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoSSVH: Exploring Automated Frame Sampling for Efficient Self-Supervised Video Hashing
Apr 04, 2025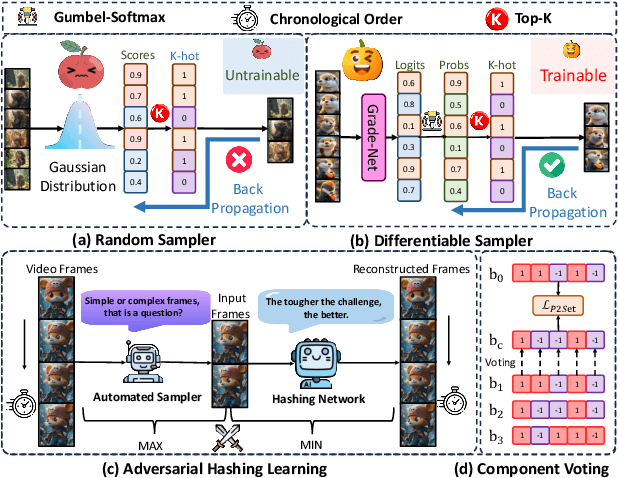

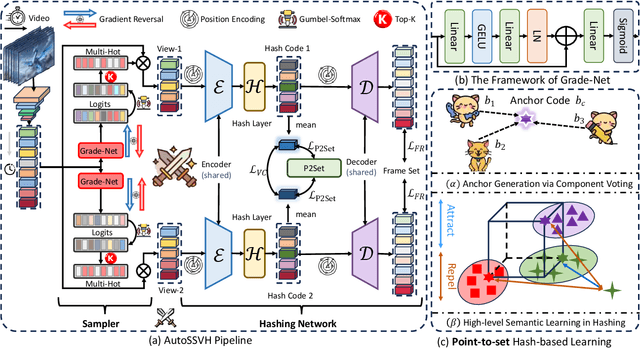
Self-Supervised Video Hashing (SSVH) compresses videos into hash codes for efficient indexing and retrieval using unlabeled training videos. Existing approaches rely on random frame sampling to learn video features and treat all frames equally. This results in suboptimal hash codes, as it ignores frame-specific information density and reconstruction difficulty. To address this limitation, we propose a new framework, termed AutoSSVH, that employs adversarial frame sampling with hash-based contrastive learning. Our adversarial sampling strategy automatically identifies and selects challenging frames with richer information for reconstruction, enhancing encoding capability. Additionally, we introduce a hash component voting strategy and a point-to-set (P2Set) hash-based contrastive objective, which help capture complex inter-video semantic relationships in the Hamming space and improve the discriminability of learned hash codes. Extensive experiments demonstrate that AutoSSVH achieves superior retrieval efficacy and efficiency compared to state-of-the-art approaches. Code is available at https://github.com/EliSpectre/CVPR25-AutoSSVH.
Efficient Self-Supervised Video Hashing with Selective State Spaces
Dec 19, 2024



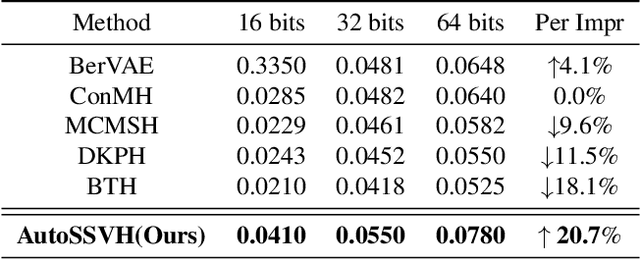
Self-supervised video hashing (SSVH) is a practical task in video indexing and retrieval. Although Transformers are predominant in SSVH for their impressive temporal modeling capabilities, they often suffer from computational and memory inefficiencies. Drawing inspiration from Mamba, an advanced state-space model, we explore its potential in SSVH to achieve a better balance between efficacy and efficiency. We introduce S5VH, a Mamba-based video hashing model with an improved self-supervised learning paradigm. Specifically, we design bidirectional Mamba layers for both the encoder and decoder, which are effective and efficient in capturing temporal relationships thanks to the data-dependent selective scanning mechanism with linear complexity. In our learning strategy, we transform global semantics in the feature space into semantically consistent and discriminative hash centers, followed by a center alignment loss as a global learning signal. Our self-local-global (SLG) paradigm significantly improves learning efficiency, leading to faster and better convergence. Extensive experiments demonstrate S5VH's improvements over state-of-the-art methods, superior transferability, and scalable advantages in inference efficiency. Code is available at https://github.com/gimpong/AAAI25-S5VH.
3D-GP-LMVIC: Learning-based Multi-View Image Coding with 3D Gaussian Geometric Priors
Sep 06, 2024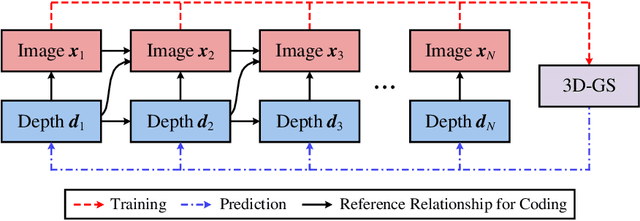
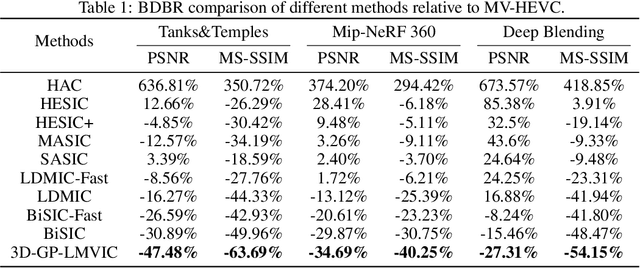
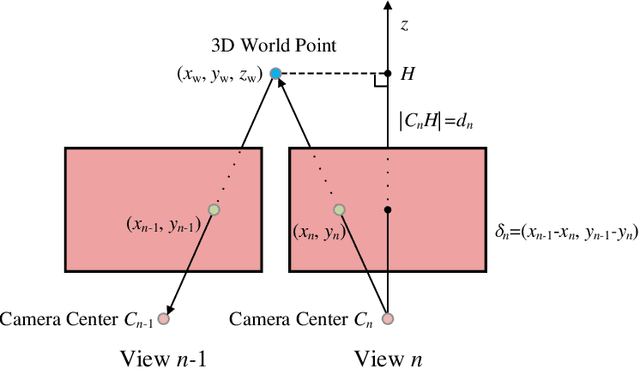
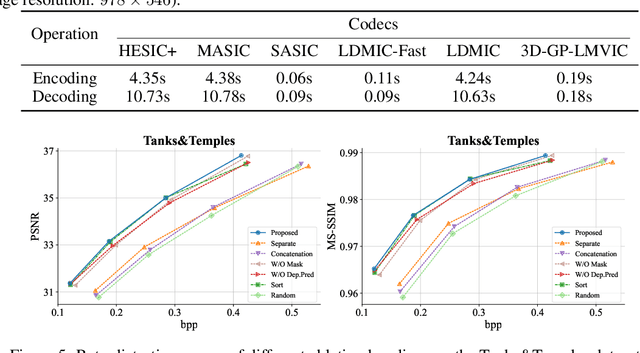
Multi-view image compression is vital for 3D-related applications. To effectively model correlations between views, existing methods typically predict disparity between two views on a 2D plane, which works well for small disparities, such as in stereo images, but struggles with larger disparities caused by significant view changes. To address this, we propose a novel approach: learning-based multi-view image coding with 3D Gaussian geometric priors (3D-GP-LMVIC). Our method leverages 3D Gaussian Splatting to derive geometric priors of the 3D scene, enabling more accurate disparity estimation across views within the compression model. Additionally, we introduce a depth map compression model to reduce redundancy in geometric information between views. A multi-view sequence ordering method is also proposed to enhance correlations between adjacent views. Experimental results demonstrate that 3D-GP-LMVIC surpasses both traditional and learning-based methods in performance, while maintaining fast encoding and decoding speed.