 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributional Uncertainty and Adaptive Decision-Making in System
Mar 14, 2026Complex engineered systems require coordinated design choices across heterogeneous components under multiple conflicting objectives and uncertain specifications. Monotone co-design provides a compositional framework for such problems by modeling each subsystem as a design problem: a feasible relation between provided functionalities and required resources in partially ordered sets. Existing uncertain co-design models rely on interval bounds, which support worst-case reasoning but cannot represent probabilistic risk or multi-stage adaptive decisions. We develop a distributional extension of co-design that models uncertain design outcomes as distributions over design problems and supports adaptive decision processes through Markov-kernel re-parameterizations. Using quasi-measurable and quasi-universal spaces, we show that the standard co-design interconnection operations remain compositional under this richer notion of uncertainty. We further introduce queries and observations that extract probabilistic design trade-offs, including feasibility probabilities, confidence bounds, and distributions of minimal required resources. A task-driven unmanned aerial vehicle case study illustrates how the framework captures risk-sensitive and information-dependent design choices that interval-based models cannot express.
Splatwizard: A Benchmark Toolkit for 3D Gaussian Splatting Compression
Dec 31, 2025The recent advent of 3D Gaussian Splatting (3DGS) has marked a significant breakthrough in real-time novel view synthesis. However, the rapid proliferation of 3DGS-based algorithms has created a pressing need for standardized and comprehensive evaluation tools, especially for compression task. Existing benchmarks often lack the specific metrics necessary to holistically assess the unique characteristics of different methods, such as rendering speed, rate distortion trade-offs memory efficiency, and geometric accuracy. To address this gap, we introduce Splatwizard, a unified benchmark toolkit designed specifically for benchmarking 3DGS compression models. Splatwizard provides an easy-to-use framework to implement new 3DGS compression model and utilize state-of-the-art techniques proposed by previous work. Besides, an integrated pipeline that automates the calculation of key performance indicators, including image-based quality metrics, chamfer distance of reconstruct mesh, rendering frame rates, and computational resource consumption is included in the framework as well. Code is available at https://github.com/splatwizard/splatwizard
TOPP-DWR: Time-Optimal Path Parameterization of Differential-Driven Wheeled Robots Considering Piecewise-Constant Angular Velocity Constraints
Nov 17, 2025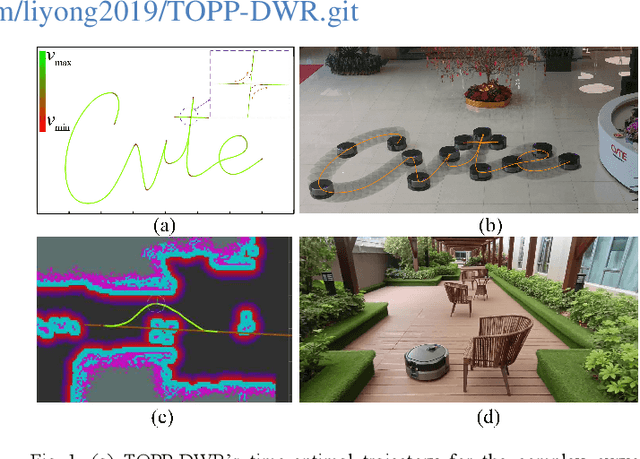
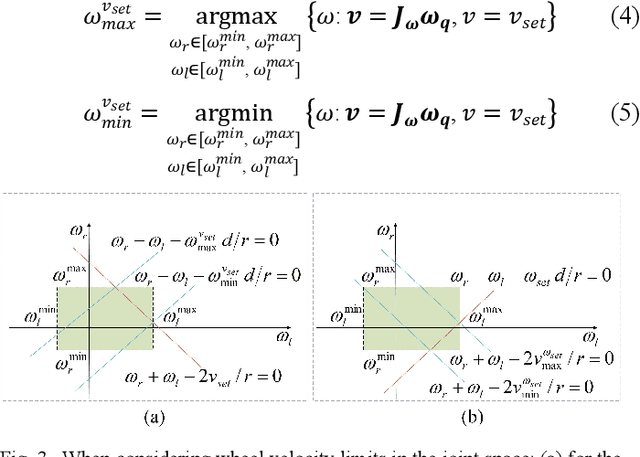
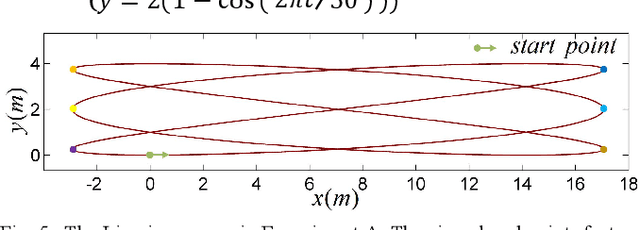
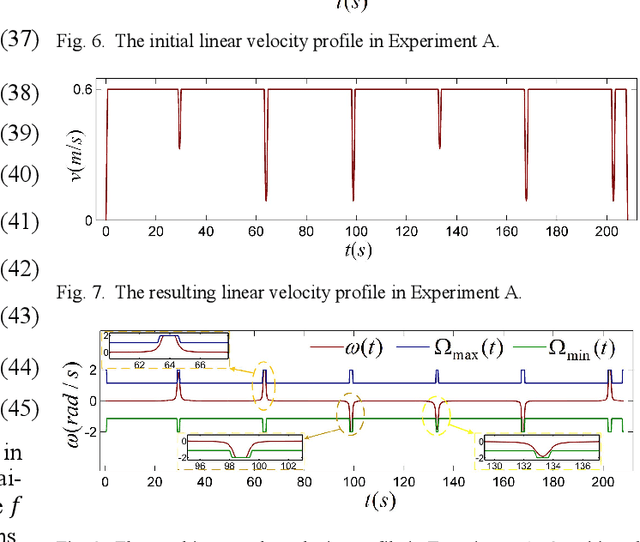
Differential-driven wheeled robots (DWR) represent the quintessential type of mobile robots and find extensive appli- cations across the robotic field. Most high-performance control approaches for DWR explicitly utilize the linear and angular velocities of the trajectory as control references. However, existing research on time-optimal path parameterization (TOPP) for mobile robots usually neglects the angular velocity and joint vel- ocity constraints, which can result in degraded control perfor- mance in practical applications. In this article, a systematic and practical TOPP algorithm named TOPP-DWR is proposed for DWR and other mobile robots. First, the non-uniform B-spline is adopted to represent the initial trajectory in the task space. Second, the piecewise-constant angular velocity, as well as joint velocity, linear velocity, and linear acceleration constraints, are incorporated into the TOPP problem. During the construction of the optimization problem, the aforementioned constraints are uniformly represented as linear velocity constraints. To boost the numerical computational efficiency, we introduce a slack variable to reformulate the problem into second-order-cone programming (SOCP). Subsequently, comparative experiments are conducted to validate the superiority of the proposed method. Quantitative performance indexes show that TOPP-DWR achieves TOPP while adhering to all constraints. Finally, field autonomous navigation experiments are carried out to validate the practicability of TOPP-DWR in real-world applications.
3D-GP-LMVIC: Learning-based Multi-View Image Coding with 3D Gaussian Geometric Priors
Sep 06, 2024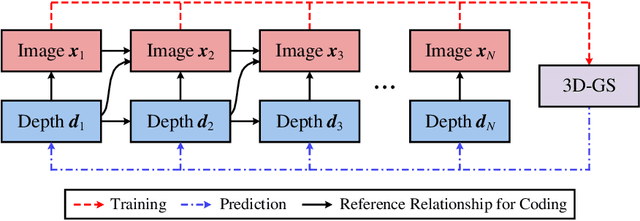
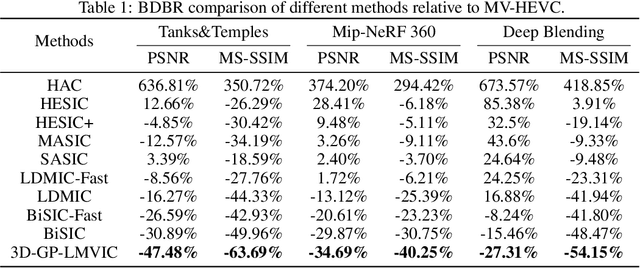
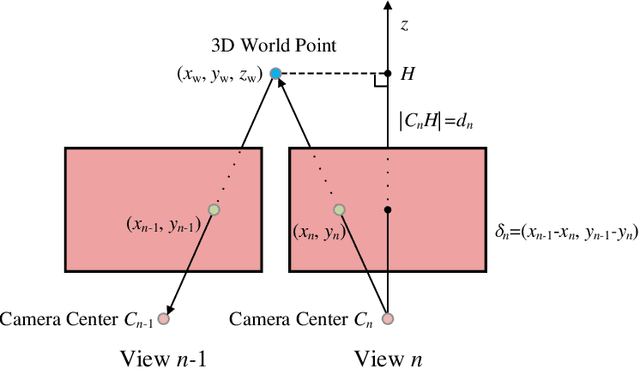
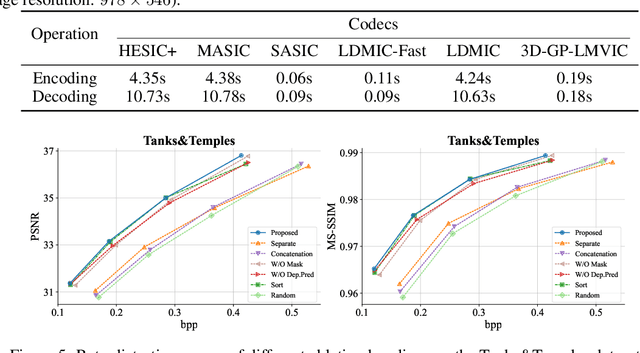
Multi-view image compression is vital for 3D-related applications. To effectively model correlations between views, existing methods typically predict disparity between two views on a 2D plane, which works well for small disparities, such as in stereo images, but struggles with larger disparities caused by significant view changes. To address this, we propose a novel approach: learning-based multi-view image coding with 3D Gaussian geometric priors (3D-GP-LMVIC). Our method leverages 3D Gaussian Splatting to derive geometric priors of the 3D scene, enabling more accurate disparity estimation across views within the compression model. Additionally, we introduce a depth map compression model to reduce redundancy in geometric information between views. A multi-view sequence ordering method is also proposed to enhance correlations between adjacent views. Experimental results demonstrate that 3D-GP-LMVIC surpasses both traditional and learning-based methods in performance, while maintaining fast encoding and decoding speed.
FFCA-Net: Stereo Image Compression via Fast Cascade Alignment of Side Information
Dec 29, 2023



Multi-view compression technology, especially Stereo Image Compression (SIC), plays a crucial role in car-mounted cameras and 3D-related applications. Interestingly, the Distributed Source Coding (DSC) theory suggests that efficient data compression of correlated sources can be achieved through independent encoding and joint decoding. This motivates the rapidly developed deep-distributed SIC methods in recent years. However, these approaches neglect the unique characteristics of stereo-imaging tasks and incur high decoding latency. To address this limitation, we propose a Feature-based Fast Cascade Alignment network (FFCA-Net) to fully leverage the side information on the decoder. FFCA adopts a coarse-to-fine cascaded alignment approach. In the initial stage, FFCA utilizes a feature domain patch-matching module based on stereo priors. This module reduces redundancy in the search space of trivial matching methods and further mitigates the introduction of noise. In the subsequent stage, we utilize an hourglass-based sparse stereo refinement network to further align inter-image features with a reduced computational cost. Furthermore, we have devised a lightweight yet high-performance feature fusion network, called a Fast Feature Fusion network (FFF), to decode the aligned features. Experimental results on InStereo2K, KITTI, and Cityscapes datasets demonstrate the significant superiority of our approach over traditional and learning-based SIC methods. In particular, our approach achieves significant gains in terms of 3 to 10-fold faster decoding speed than other methods.
Perceptual Image Compression with Cooperative Cross-Modal Side Information
Nov 28, 2023



The explosion of data has resulted in more and more associated text being transmitted along with images. Inspired by from distributed source coding, many works utilize image side information to enhance image compression. However, existing methods generally do not consider using text as side information to enhance perceptual compression of images, even though the benefits of multimodal synergy have been widely demonstrated in research. This begs the following question: How can we effectively transfer text-level semantic dependencies to help image compression, which is only available to the decoder? In this work, we propose a novel deep image compression method with text-guided side information to achieve a better rate-perception-distortion tradeoff. Specifically, we employ the CLIP text encoder and an effective Semantic-Spatial Aware block to fuse the text and image features. This is done by predicting a semantic mask to guide the learned text-adaptive affine transformation at the pixel level. Furthermore, we design a text-conditional generative adversarial networks to improve the perceptual quality of reconstructed images. Extensive experiments involving four datasets and ten image quality assessment metrics demonstrate that the proposed approach achieves superior results in terms of rate-perception trade-off and semantic distortion.
Adapter Learning in Pretrained Feature Extractor for Continual Learning of Diseases
Apr 18, 2023



Currently intelligent diagnosis systems lack the ability of continually learning to diagnose new diseases once deployed, under the condition of preserving old disease knowledge. In particular, updating an intelligent diagnosis system with training data of new diseases would cause catastrophic forgetting of old disease knowledge. To address the catastrophic forgetting issue, a novel adapter-based strategy is proposed to help effectively learn a set of new diseases at each round (or task) of continual learning, without changing the shared feature extractor. The learnable lightweight task-specific adapter(s) can be flexibly designed (e.g., two convolutional layers) and then added to the pretrained and fixed feature extractor. Together with a specially designed task-specific head which absorbs all previously learned old diseases as a single 'out-of-distribution' category, task-specific adapter(s) can help the pretrained feature extractor more effectively extract discriminative features between diseases. In addition, a simple yet effective fine-tuning is applied to collaboratively fine-tune multiple task-specific heads such that outputs from different heads are comparable and consequently the appropriate classifier head can be more accurately selected during model inference. Extensive empirical evaluations on three image datasets demonstrate the superior performance of the proposed method in continual learning of new diseases. The source code will be released publicly.
Learned Distributed Image Compression with Multi-Scale Patch Matching in Feature Domai
Sep 06, 2022
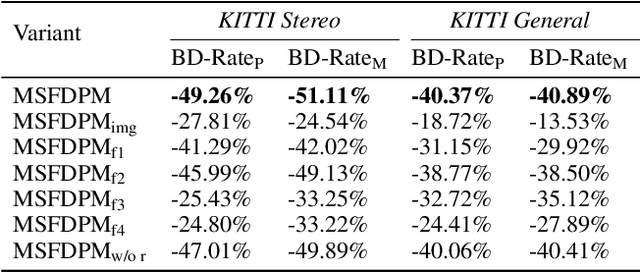
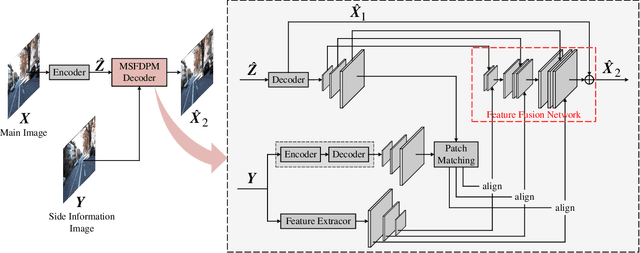

Beyond achieving higher compression efficiency over classical image compression codecs, deep image compression is expected to be improved with additional side information, e.g., another image from a different perspective of the same scene. To better utilize the side information under the distributed compression scenario, the existing method (Ayzik and Avidan 2020) only implements patch matching at the image domain to solve the parallax problem caused by the difference in viewing points. However, the patch matching at the image domain is not robust to the variance of scale, shape, and illumination caused by the different viewing angles, and can not make full use of the rich texture information of the side information image. To resolve this issue, we propose Multi-Scale Feature Domain Patch Matching (MSFDPM) to fully utilizes side information at the decoder of the distributed image compression model. Specifically, MSFDPM consists of a side information feature extractor, a multi-scale feature domain patch matching module, and a multi-scale feature fusion network. Furthermore, we reuse inter-patch correlation from the shallow layer to accelerate the patch matching of the deep layer. Finally, we nd that our patch matching in a multi-scale feature domain further improves compression rate by about 20% compared with the patch matching method at image domain (Ayzik and Avidan 2020).