 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh Quality Underwater Image Compression with Adaptive Correction and Codebook-based Augmentation
May 15, 2025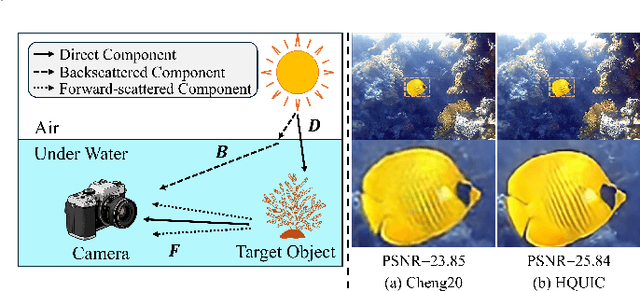
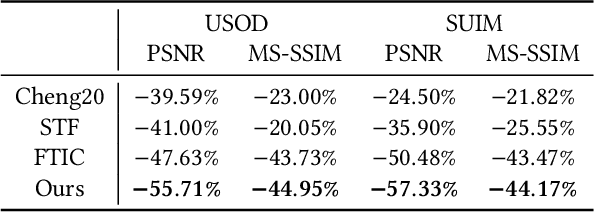
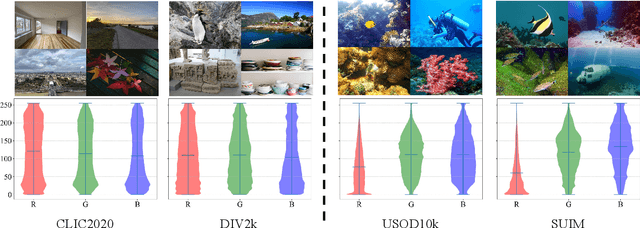
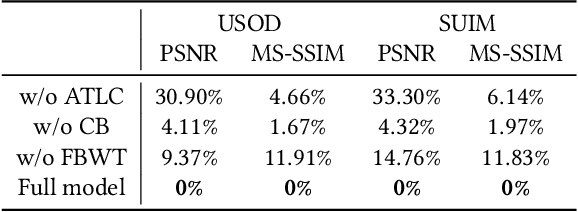
With the increasing exploration and exploitation of the underwater world, underwater images have become a critical medium for human interaction with marine environments, driving extensive research into their efficient transmission and storage. However, contemporary underwater image compression algorithms fail to fully leverage the unique characteristics distinguishing underwater scenes from terrestrial images, resulting in suboptimal performance. To address this limitation, we introduce HQUIC, designed to exploit underwater-image-specific features for enhanced compression efficiency. HQUIC employs an ALTC module to adaptively predict the attenuation coefficients and global light information of the images, which effectively mitigates the issues caused by the differences in lighting and tone existing in underwater images. Subsequently, HQUIC employs a codebook as an auxiliary branch to extract the common objects within underwater images and enhances the performance of the main branch. Furthermore, HQUIC dynamically weights multi-scale frequency components, prioritizing information critical for distortion quality while discarding redundant details. Extensive evaluations on diverse underwater datasets demonstrate that HQUIC outperforms state-of-the-art compression methods.
Towards Facial Image Compression with Consistency Preserving Diffusion Prior
May 09, 2025With the widespread application of facial image data across various domains, the efficient storage and transmission of facial images has garnered significant attention. However, the existing learned face image compression methods often produce unsatisfactory reconstructed image quality at low bit rates. Simply adapting diffusion-based compression methods to facial compression tasks results in reconstructed images that perform poorly in downstream applications due to insufficient preservation of high-frequency information. To further explore the diffusion prior in facial image compression, we propose Facial Image Compression with a Stable Diffusion Prior (FaSDiff), a method that preserves consistency through frequency enhancement. FaSDiff employs a high-frequency-sensitive compressor in an end-to-end framework to capture fine image details and produce robust visual prompts. Additionally, we introduce a hybrid low-frequency enhancement module that disentangles low-frequency facial semantics and stably modulates the diffusion prior alongside visual prompts. The proposed modules allow FaSDiff to leverage diffusion priors for superior human visual perception while minimizing performance loss in machine vision due to semantic inconsistency. Extensive experiments show that FaSDiff outperforms state-of-the-art methods in balancing human visual quality and machine vision accuracy. The code will be released after the paper is accepted.
3D-GP-LMVIC: Learning-based Multi-View Image Coding with 3D Gaussian Geometric Priors
Sep 06, 2024
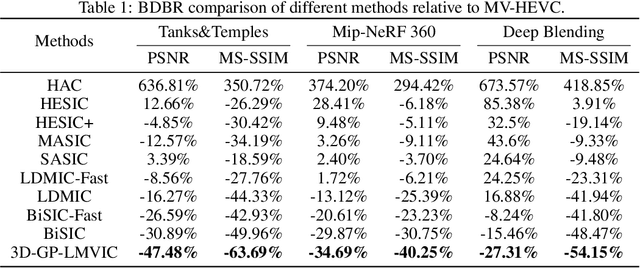
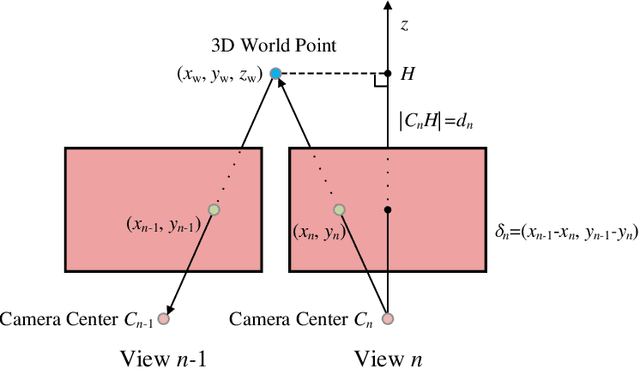
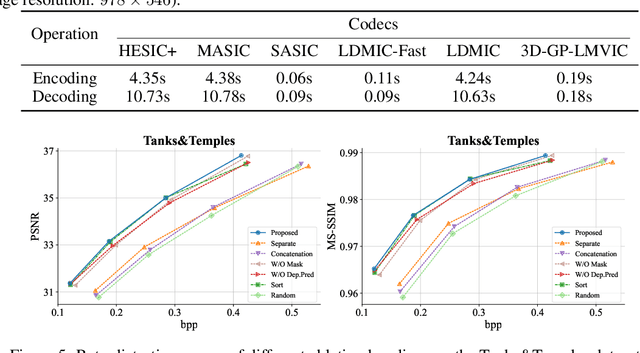
Multi-view image compression is vital for 3D-related applications. To effectively model correlations between views, existing methods typically predict disparity between two views on a 2D plane, which works well for small disparities, such as in stereo images, but struggles with larger disparities caused by significant view changes. To address this, we propose a novel approach: learning-based multi-view image coding with 3D Gaussian geometric priors (3D-GP-LMVIC). Our method leverages 3D Gaussian Splatting to derive geometric priors of the 3D scene, enabling more accurate disparity estimation across views within the compression model. Additionally, we introduce a depth map compression model to reduce redundancy in geometric information between views. A multi-view sequence ordering method is also proposed to enhance correlations between adjacent views. Experimental results demonstrate that 3D-GP-LMVIC surpasses both traditional and learning-based methods in performance, while maintaining fast encoding and decoding speed.
MambaVC: Learned Visual Compression with Selective State Spaces
May 28, 2024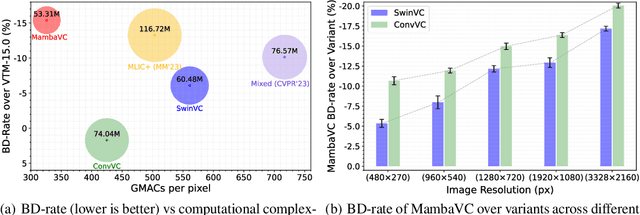
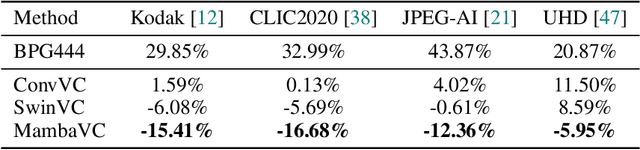
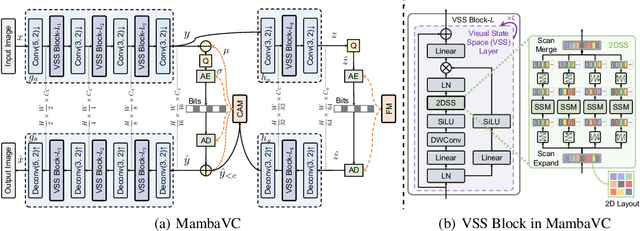
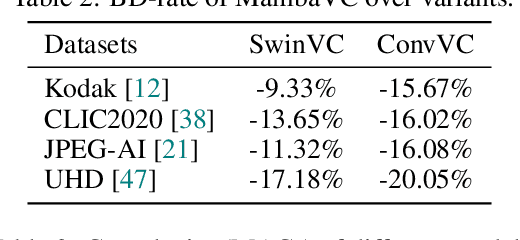
Learned visual compression is an important and active task in multimedia. Existing approaches have explored various CNN- and Transformer-based designs to model content distribution and eliminate redundancy, where balancing efficacy (i.e., rate-distortion trade-off) and efficiency remains a challenge. Recently, state-space models (SSMs) have shown promise due to their long-range modeling capacity and efficiency. Inspired by this, we take the first step to explore SSMs for visual compression. We introduce MambaVC, a simple, strong and efficient compression network based on SSM. MambaVC develops a visual state space (VSS) block with a 2D selective scanning (2DSS) module as the nonlinear activation function after each downsampling, which helps to capture informative global contexts and enhances compression. On compression benchmark datasets, MambaVC achieves superior rate-distortion performance with lower computational and memory overheads. Specifically, it outperforms CNN and Transformer variants by 9.3% and 15.6% on Kodak, respectively, while reducing computation by 42% and 24%, and saving 12% and 71% of memory. MambaVC shows even greater improvements with high-resolution images, highlighting its potential and scalability in real-world applications. We also provide a comprehensive comparison of different network designs, underscoring MambaVC's advantages. Code is available at https://github.com/QinSY123/2024-MambaVC.
Fast Implicit Neural Representation Image Codec in Resource-limited Devices
Jan 23, 2024Displaying high-quality images on edge devices, such as augmented reality devices, is essential for enhancing the user experience. However, these devices often face power consumption and computing resource limitations, making it challenging to apply many deep learning-based image compression algorithms in this field. Implicit Neural Representation (INR) for image compression is an emerging technology that offers two key benefits compared to cutting-edge autoencoder models: low computational complexity and parameter-free decoding. It also outperforms many traditional and early neural compression methods in terms of quality. In this study, we introduce a new Mixed Autoregressive Model (MARM) to significantly reduce the decoding time for the current INR codec, along with a new synthesis network to enhance reconstruction quality. MARM includes our proposed Autoregressive Upsampler (ARU) blocks, which are highly computationally efficient, and ARM from previous work to balance decoding time and reconstruction quality. We also propose enhancing ARU's performance using a checkerboard two-stage decoding strategy. Moreover, the ratio of different modules can be adjusted to maintain a balance between quality and speed. Comprehensive experiments demonstrate that our method significantly improves computational efficiency while preserving image quality. With different parameter settings, our method can outperform popular AE-based codecs in constrained environments in terms of both quality and decoding time, or achieve state-of-the-art reconstruction quality compared to other INR codecs.
Progressive Learning with Visual Prompt Tuning for Variable-Rate Image Compression
Nov 28, 2023In this paper, we propose a progressive learning paradigm for transformer-based variable-rate image compression. Our approach covers a wide range of compression rates with the assistance of the Layer-adaptive Prompt Module (LPM). Inspired by visual prompt tuning, we use LPM to extract prompts for input images and hidden features at the encoder side and decoder side, respectively, which are fed as additional information into the Swin Transformer layer of a pre-trained transformer-based image compression model to affect the allocation of attention region and the bits, which in turn changes the target compression ratio of the model. To ensure the network is more lightweight, we involves the integration of prompt networks with less convolutional layers. Exhaustive experiments show that compared to methods based on multiple models, which are optimized separately for different target rates, the proposed method arrives at the same performance with 80% savings in parameter storage and 90% savings in datasets. Meanwhile, our model outperforms all current variable bitrate image methods in terms of rate-distortion performance and approaches the state-of-the-art fixed bitrate image compression methods trained from scratch.
Perceptual Image Compression with Cooperative Cross-Modal Side Information
Nov 28, 2023



The explosion of data has resulted in more and more associated text being transmitted along with images. Inspired by from distributed source coding, many works utilize image side information to enhance image compression. However, existing methods generally do not consider using text as side information to enhance perceptual compression of images, even though the benefits of multimodal synergy have been widely demonstrated in research. This begs the following question: How can we effectively transfer text-level semantic dependencies to help image compression, which is only available to the decoder? In this work, we propose a novel deep image compression method with text-guided side information to achieve a better rate-perception-distortion tradeoff. Specifically, we employ the CLIP text encoder and an effective Semantic-Spatial Aware block to fuse the text and image features. This is done by predicting a semantic mask to guide the learned text-adaptive affine transformation at the pixel level. Furthermore, we design a text-conditional generative adversarial networks to improve the perceptual quality of reconstructed images. Extensive experiments involving four datasets and ten image quality assessment metrics demonstrate that the proposed approach achieves superior results in terms of rate-perception trade-off and semantic distortion.