 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlowErase-RL: Rethinking Concept Erasure as Reward Optimization in Flow Matching Models
May 19, 2026Recent advances in flow matching models have significantly improved text-to-image generation quality, but also introduce growing safety risks due to the generation of harmful or undesirable content. Existing concept erasure methods are either inference-time interventions with limited effectiveness or rely on supervised fine-tuning (SFT), which requires precisely aligned data and struggles with scalability and multi-concept settings. In this paper, we propose \emph{FlowErase-RL}, the first GRPO-based framework for concept erasure in flow matching models. We reformulate concept erasure as a reward optimization problem and introduce a \textbf{dynamic dual-path reward mechanism} that jointly optimizes (i) a Concept Erasure (CE) reward to suppress target concepts and (ii) a Non-target Space (NS) reward to preserve generative fidelity. The two reward paths are adaptively balanced during training via a performance-driven switching strategy, enabling stable optimization without explicit supervision. Extensive experiments on nudity, object, and artistic style erasure demonstrate that our method achieves state-of-the-art erasure performance while maintaining strong image quality and semantic alignment. Moreover, it exhibits robust resistance to adversarial attacks and scales effectively to multi-concept scenarios. Our results establish a new paradigm for safe and controllable generation in flow matching models.
Towards Efficient Low-rate Image Compression with Frequency-aware Diffusion Prior Refinement
Jan 15, 2026Recent advancements in diffusion-based generative priors have enabled visually plausible image compression at extremely low bit rates. However, existing approaches suffer from slow sampling processes and suboptimal bit allocation due to fragmented training paradigms. In this work, we propose Accelerate \textbf{Diff}usion-based Image Compression via \textbf{C}onsistency Prior \textbf{R}efinement (DiffCR), a novel compression framework for efficient and high-fidelity image reconstruction. At the heart of DiffCR is a Frequency-aware Skip Estimation (FaSE) module that refines the $ε$-prediction prior from a pre-trained latent diffusion model and aligns it with compressed latents at different timesteps via Frequency Decoupling Attention (FDA). Furthermore, a lightweight consistency estimator enables fast \textbf{two-step decoding} by preserving the semantic trajectory of diffusion sampling. Without updating the backbone diffusion model, DiffCR achieves substantial bitrate savings (27.2\% BD-rate (LPIPS) and 65.1\% BD-rate (PSNR)) and over $10\times$ speed-up compared to SOTA diffusion-based compression baselines.
ActErase: A Training-Free Paradigm for Precise Concept Erasure via Activation Patching
Jan 01, 2026Recent advances in text-to-image diffusion models have demonstrated remarkable generation capabilities, yet they raise significant concerns regarding safety, copyright, and ethical implications. Existing concept erasure methods address these risks by removing sensitive concepts from pre-trained models, but most of them rely on data-intensive and computationally expensive fine-tuning, which poses a critical limitation. To overcome these challenges, inspired by the observation that the model's activations are predominantly composed of generic concepts, with only a minimal component can represent the target concept, we propose a novel training-free method (ActErase) for efficient concept erasure. Specifically, the proposed method operates by identifying activation difference regions via prompt-pair analysis, extracting target activations and dynamically replacing input activations during forward passes. Comprehensive evaluations across three critical erasure tasks (nudity, artistic style, and object removal) demonstrates that our training-free method achieves state-of-the-art (SOTA) erasure performance, while effectively preserving the model's overall generative capability. Our approach also exhibits strong robustness against adversarial attacks, establishing a new plug-and-play paradigm for lightweight yet effective concept manipulation in diffusion models.
Splatwizard: A Benchmark Toolkit for 3D Gaussian Splatting Compression
Dec 31, 2025The recent advent of 3D Gaussian Splatting (3DGS) has marked a significant breakthrough in real-time novel view synthesis. However, the rapid proliferation of 3DGS-based algorithms has created a pressing need for standardized and comprehensive evaluation tools, especially for compression task. Existing benchmarks often lack the specific metrics necessary to holistically assess the unique characteristics of different methods, such as rendering speed, rate distortion trade-offs memory efficiency, and geometric accuracy. To address this gap, we introduce Splatwizard, a unified benchmark toolkit designed specifically for benchmarking 3DGS compression models. Splatwizard provides an easy-to-use framework to implement new 3DGS compression model and utilize state-of-the-art techniques proposed by previous work. Besides, an integrated pipeline that automates the calculation of key performance indicators, including image-based quality metrics, chamfer distance of reconstruct mesh, rendering frame rates, and computational resource consumption is included in the framework as well. Code is available at https://github.com/splatwizard/splatwizard
Closing the Safety Gap: Surgical Concept Erasure in Visual Autoregressive Models
Sep 26, 2025The rapid progress of visual autoregressive (VAR) models has brought new opportunities for text-to-image generation, but also heightened safety concerns. Existing concept erasure techniques, primarily designed for diffusion models, fail to generalize to VARs due to their next-scale token prediction paradigm. In this paper, we first propose a novel VAR Erasure framework VARE that enables stable concept erasure in VAR models by leveraging auxiliary visual tokens to reduce fine-tuning intensity. Building upon this, we introduce S-VARE, a novel and effective concept erasure method designed for VAR, which incorporates a filtered cross entropy loss to precisely identify and minimally adjust unsafe visual tokens, along with a preservation loss to maintain semantic fidelity, addressing the issues such as language drift and reduced diversity introduce by na\"ive fine-tuning. Extensive experiments demonstrate that our approach achieves surgical concept erasure while preserving generation quality, thereby closing the safety gap in autoregressive text-to-image generation by earlier methods.
Temporal Saliency-Guided Distillation: A Scalable Framework for Distilling Video Datasets
May 27, 2025



Dataset distillation (DD) has emerged as a powerful paradigm for dataset compression, enabling the synthesis of compact surrogate datasets that approximate the training utility of large-scale ones. While significant progress has been achieved in distilling image datasets, extending DD to the video domain remains challenging due to the high dimensionality and temporal complexity inherent in video data. Existing video distillation (VD) methods often suffer from excessive computational costs and struggle to preserve temporal dynamics, as na\"ive extensions of image-based approaches typically lead to degraded performance. In this paper, we propose a novel uni-level video dataset distillation framework that directly optimizes synthetic videos with respect to a pre-trained model. To address temporal redundancy and enhance motion preservation, we introduce a temporal saliency-guided filtering mechanism that leverages inter-frame differences to guide the distillation process, encouraging the retention of informative temporal cues while suppressing frame-level redundancy. Extensive experiments on standard video benchmarks demonstrate that our method achieves state-of-the-art performance, bridging the gap between real and distilled video data and offering a scalable solution for video dataset compression.
High Quality Underwater Image Compression with Adaptive Correction and Codebook-based Augmentation
May 15, 2025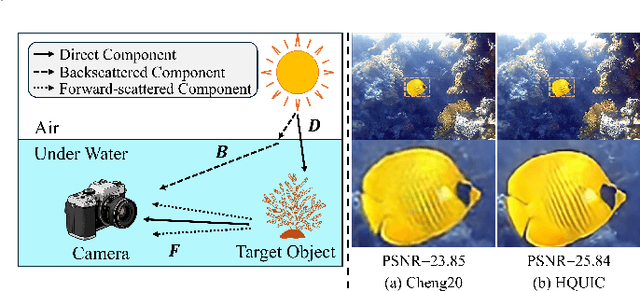
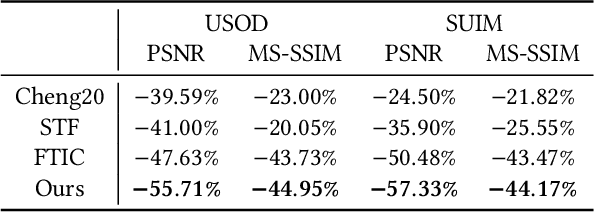
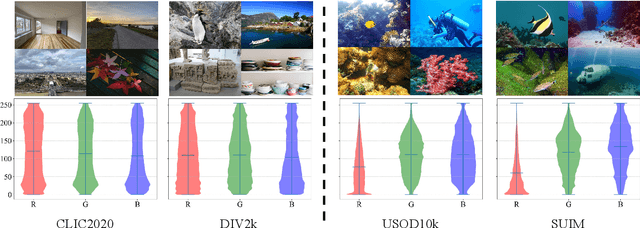
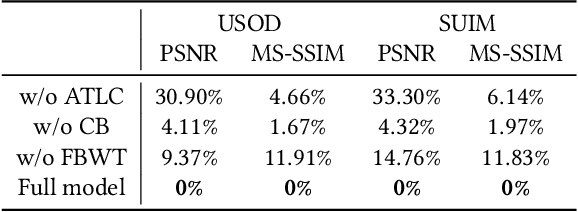
With the increasing exploration and exploitation of the underwater world, underwater images have become a critical medium for human interaction with marine environments, driving extensive research into their efficient transmission and storage. However, contemporary underwater image compression algorithms fail to fully leverage the unique characteristics distinguishing underwater scenes from terrestrial images, resulting in suboptimal performance. To address this limitation, we introduce HQUIC, designed to exploit underwater-image-specific features for enhanced compression efficiency. HQUIC employs an ALTC module to adaptively predict the attenuation coefficients and global light information of the images, which effectively mitigates the issues caused by the differences in lighting and tone existing in underwater images. Subsequently, HQUIC employs a codebook as an auxiliary branch to extract the common objects within underwater images and enhances the performance of the main branch. Furthermore, HQUIC dynamically weights multi-scale frequency components, prioritizing information critical for distortion quality while discarding redundant details. Extensive evaluations on diverse underwater datasets demonstrate that HQUIC outperforms state-of-the-art compression methods.
Towards Facial Image Compression with Consistency Preserving Diffusion Prior
May 09, 2025With the widespread application of facial image data across various domains, the efficient storage and transmission of facial images has garnered significant attention. However, the existing learned face image compression methods often produce unsatisfactory reconstructed image quality at low bit rates. Simply adapting diffusion-based compression methods to facial compression tasks results in reconstructed images that perform poorly in downstream applications due to insufficient preservation of high-frequency information. To further explore the diffusion prior in facial image compression, we propose Facial Image Compression with a Stable Diffusion Prior (FaSDiff), a method that preserves consistency through frequency enhancement. FaSDiff employs a high-frequency-sensitive compressor in an end-to-end framework to capture fine image details and produce robust visual prompts. Additionally, we introduce a hybrid low-frequency enhancement module that disentangles low-frequency facial semantics and stably modulates the diffusion prior alongside visual prompts. The proposed modules allow FaSDiff to leverage diffusion priors for superior human visual perception while minimizing performance loss in machine vision due to semantic inconsistency. Extensive experiments show that FaSDiff outperforms state-of-the-art methods in balancing human visual quality and machine vision accuracy. The code will be released after the paper is accepted.
MambaVC: Learned Visual Compression with Selective State Spaces
May 28, 2024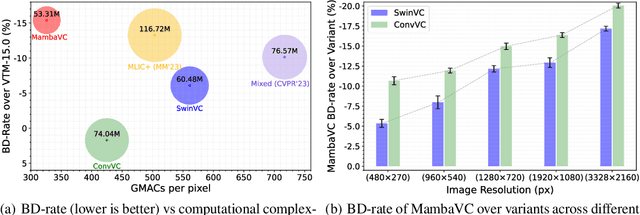
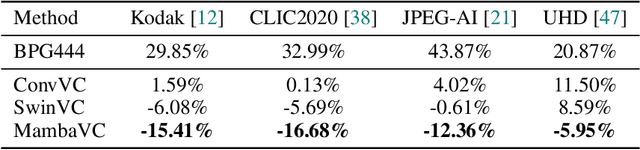
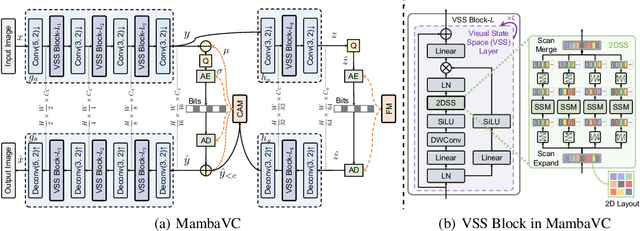
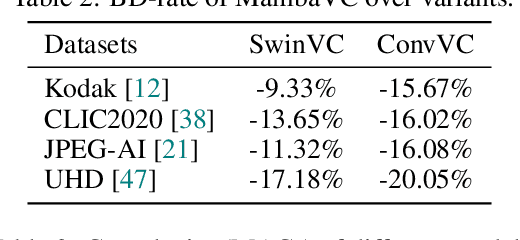
Learned visual compression is an important and active task in multimedia. Existing approaches have explored various CNN- and Transformer-based designs to model content distribution and eliminate redundancy, where balancing efficacy (i.e., rate-distortion trade-off) and efficiency remains a challenge. Recently, state-space models (SSMs) have shown promise due to their long-range modeling capacity and efficiency. Inspired by this, we take the first step to explore SSMs for visual compression. We introduce MambaVC, a simple, strong and efficient compression network based on SSM. MambaVC develops a visual state space (VSS) block with a 2D selective scanning (2DSS) module as the nonlinear activation function after each downsampling, which helps to capture informative global contexts and enhances compression. On compression benchmark datasets, MambaVC achieves superior rate-distortion performance with lower computational and memory overheads. Specifically, it outperforms CNN and Transformer variants by 9.3% and 15.6% on Kodak, respectively, while reducing computation by 42% and 24%, and saving 12% and 71% of memory. MambaVC shows even greater improvements with high-resolution images, highlighting its potential and scalability in real-world applications. We also provide a comprehensive comparison of different network designs, underscoring MambaVC's advantages. Code is available at https://github.com/QinSY123/2024-MambaVC.
Progressive Learning with Visual Prompt Tuning for Variable-Rate Image Compression
Nov 28, 2023In this paper, we propose a progressive learning paradigm for transformer-based variable-rate image compression. Our approach covers a wide range of compression rates with the assistance of the Layer-adaptive Prompt Module (LPM). Inspired by visual prompt tuning, we use LPM to extract prompts for input images and hidden features at the encoder side and decoder side, respectively, which are fed as additional information into the Swin Transformer layer of a pre-trained transformer-based image compression model to affect the allocation of attention region and the bits, which in turn changes the target compression ratio of the model. To ensure the network is more lightweight, we involves the integration of prompt networks with less convolutional layers. Exhaustive experiments show that compared to methods based on multiple models, which are optimized separately for different target rates, the proposed method arrives at the same performance with 80% savings in parameter storage and 90% savings in datasets. Meanwhile, our model outperforms all current variable bitrate image methods in terms of rate-distortion performance and approaches the state-of-the-art fixed bitrate image compression methods trained from scratch.