 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Structural Latent Points for Efficient Visual Representations in Robotic Manipulation
May 20, 2026Current 3D-aware pretraining methods for embodied perception and manipulation are largely built on differentiable rendering frameworks, producing either fully implicit neural fields or fully explicit geometric primitives. Implicit representations, while expressive, lack explicit structural cues, whereas explicit ones preserve geometry but suffer from resolution limits and weak generalization. To address these limitations, we propose a novel pretraining framework that learns a hybrid representation-structural latent points. Specifically, we insert a point-wise latent variational autoencoder into the latent space of a point-cloud autoencoder, jointly regularizing point-wise features and coordinates toward a Gaussian prior. The resulting compact latent preserves coarse structural tendencies, which do not encode precise geometry but capture richer rough shape and semantic information, effectively combining the expressiveness of implicit representations with the structural priors of explicit ones. In addition, informed by shared design choices in prior work, we develop a streamlined, efficient 3DGS-based rendering pipeline that is deliberately kept lightweight, improving efficiency while leaving greater representational capacity to the front-end latent module. Extensive evaluations on RLBench, ManiSkill2, and a real-robot platform demonstrate consistent gains in task success, sample efficiency, and robustness to viewpoint and scene variations over strong baselines. Ablation studies further confirm that each component of our framework is critical to overall performance.
CPC-VAR:Continual Personalized and Compositional Generation in Visual Autoregressive Models
May 19, 2026Visual autoregressive (VAR) models have recently emerged as an efficient paradigm for text-to-image generation. Despite their strong generative capability, existing VAR-based personalization methods remain limited to static settings, failing to accommodate evolving user demands. In particular, sequential concept learning leads to severe catastrophic forgetting, while multi-concept synthesis often suffers from feature entanglement and attribute inconsistency. In this work, we present the first systematic study of continual personalized generation in VAR models. We identify two key challenges: (i) preserving previously learned concepts during sequential customization, and (ii) composing multiple personalized concepts in a controllable manner. To address these issues, we propose a unified framework with two core components. For continual single-concept learning, we introduce Gradient-based Concept Neuron Selection (GCNS), which identifies concept-relevant neurons and constrains only conflicting parameters across tasks, effectively mitigating forgetting without additional model expansion. For multi-concept synthesis, we propose a context-aware composition strategy that performs multi-branch feature modeling and localized cross-attention fusion guided by spatial conditions, enabling precise and disentangled concept composition. Extensive experiments demonstrate that our method significantly improves performance in long-sequence continual personalization while achieving superior results in multi-concept image synthesis compared to existing baselines. These findings highlight the potential of VAR models for scalable and controllable personalized generation.
ActionNex: A Virtual Outage Manager for Cloud
Apr 03, 2026Outage management in large-scale cloud operations remains heavily manual, requiring rapid triage, cross-team coordination, and experience-driven decisions under partial observability. We present \textbf{ActionNex}, a production-grade agentic system that supports end-to-end outage assistance, including real-time updates, knowledge distillation, and role- and stage-conditioned next-best action recommendations. ActionNex ingests multimodal operational signals (e.g., outage content, telemetry, and human communications) and compresses them into critical events that represent meaningful state transitions. It couples this perception layer with a hierarchical memory subsystem: long-term Key-Condition-Action (KCA) knowledge distilled from playbooks and historical executions, episodic memory of prior outages, and working memory of the live context. A reasoning agent aligns current critical events to preconditions, retrieves relevant memories, and generates actionable recommendations; executed human actions serve as an implicit feedback signal to enable continual self-evolution in a human-agent hybrid system. We evaluate ActionNex on eight real Azure outages (8M tokens, 4,000 critical events) using two complementary ground-truth action sets, achieving 71.4\% precision and 52.8-54.8\% recall. The system has been piloted in production and has received positive early feedback.
Functional Subspace Watermarking for Large Language Models
Mar 19, 2026Model watermarking utilizes internal representations to protect the ownership of large language models (LLMs). However, these features inevitably undergo complex distortions during realistic model modifications such as fine-tuning, quantization, or knowledge distillation, making reliable extraction extremely challenging. Despite extensive research on model-side watermarking, existing methods still lack sufficient robustness against parameter-level perturbations. To address this gap, we propose \texttt{\textbf{Functional Subspace Watermarking (FSW)}}, a framework that anchors ownership signals into a low-dimensional functional backbone. Specifically, we first solve a generalized eigenvalue problem to extract a stable functional subspace for watermark injection, while introducing an adaptive spectral truncation strategy to achieve an optimal balance between robustness and model utility. Furthermore, a vector consistency constraint is incorporated to ensure that watermark injection does not compromise the original semantic performance. Extensive experiments across various LLM architectures and datasets demonstrate that our method achieves superior detection accuracy and statistical verifiability under multiple model attacks, maintaining robustness that outperforms existing state-of-the-art (SOTA) methods.
UGID: Unified Graph Isomorphism for Debiasing Large Language Models
Mar 19, 2026Large language models (LLMs) exhibit pronounced social biases. Output-level or data-optimization--based debiasing methods cannot fully resolve these biases, and many prior works have shown that biases are embedded in internal representations. We propose \underline{U}nified \underline{G}raph \underline{I}somorphism for \underline{D}ebiasing large language models (\textit{\textbf{UGID}}), an internal-representation--level debiasing framework for large language models that models the Transformer as a structured computational graph, where attention mechanisms define the routing edges of the graph and hidden states define the graph nodes. Specifically, debiasing is formulated as enforcing invariance of the graph structure across counterfactual inputs, with differences allowed only on sensitive attributes. \textit{\textbf{UGID}} jointly constrains attention routing and hidden representations in bias-sensitive regions, effectively preventing bias migration across architectural components. To achieve effective behavioral alignment without degrading general capabilities, we introduce a log-space constraint on sensitive logits and a selective anchor-based objective to preserve definitional semantics. Extensive experiments on large language models demonstrate that \textit{\textbf{UGID}} effectively reduces bias under both in-distribution and out-of-distribution settings, significantly reduces internal structural discrepancies, and preserves model safety and utility.
Omnidirectional Humanoid Locomotion on Stairs via Unsafe Stepping Penalty and Sparse LiDAR Elevation Mapping
Mar 09, 2026Humanoid robots, characterized by numerous degrees of freedom and a high center of gravity, are inherently unstable. Safe omnidirectional locomotion on stairs requires both omnidirectional terrain perception and reliable foothold selection. Existing methods often rely on forward-facing depth cameras, which create blind zones that restrict omnidirectional mobility. Furthermore, sparse post-contact unsafe stepping penalties lead to low learning efficiency and suboptimal strategies. To realize safe stair-traversal gaits, this paper introduces a single-stage training framework incorporating a dense unsafe stepping penalty that provides continuous feedback as the foot approaches a hazardous placement. To obtain stable and reliable elevation maps, we build a rolling point-cloud mapping system with spatiotemporal confidence decay and a self-protection zone mechanism, producing temporally consistent local maps. These maps are further refined by an Edge-Guided Asymmetric U-Net (EGAU), which mitigates reconstruction distortion caused by sparse LiDAR returns on stair risers. Simulation and real-robot experiments show that the proposed method achieves a near-100\% safe stepping rate on stair terrains in simulation, while maintaining a remarkably high safe stepping rate in real-world deployments. Furthermore, it completes a continuous long-distance walking test on complex outdoor terrains, demonstrating reliable sim-to-real transfer and long-term stability.
DEP: A Decentralized Large Language Model Evaluation Protocol
Mar 01, 2026With the rapid development of Large Language Models (LLMs), a large number of benchmarks have been proposed. However, most benchmarks lack unified evaluation standard and require the manual implementation of custom scripts, making results hard to ensure consistency and reproducibility. Furthermore, mainstream evaluation frameworks are centralized, with datasets and answers, which increases the risk of benchmark leakage. To address these issues, we propose a Decentralized Evaluation Protocol (DEP), a decentralized yet unified and standardized evaluation framework through a matching server without constraining benchmarks. The server can be mounted locally or deployed remotely, and once adapted, it can be reused over the long term. By decoupling users, LLMs, and benchmarks, DEP enables modular, plug-and-play evaluation: benchmark files and evaluation logic stay exclusively on the server side. In remote setting, users cannot access the ground truth, thereby achieving data isolation and leak-proof evaluation. To facilitate practical adoption, we develop DEP Toolkit, a protocol-compatible toolkit that supports features such as breakpoint resume, concurrent requests, and congestion control. We also provide detailed documentation for adapting new benchmarks to DEP. Using DEP toolkit, we evaluate multiple LLMs across benchmarks. Experimental results verify the effectiveness of DEP and show that it reduces the cost of deploying benchmark evaluations. As of February 2026, we have adapted over 60 benchmarks and continue to promote community co-construction to support unified evaluation across various tasks and domains.
ActErase: A Training-Free Paradigm for Precise Concept Erasure via Activation Patching
Jan 01, 2026Recent advances in text-to-image diffusion models have demonstrated remarkable generation capabilities, yet they raise significant concerns regarding safety, copyright, and ethical implications. Existing concept erasure methods address these risks by removing sensitive concepts from pre-trained models, but most of them rely on data-intensive and computationally expensive fine-tuning, which poses a critical limitation. To overcome these challenges, inspired by the observation that the model's activations are predominantly composed of generic concepts, with only a minimal component can represent the target concept, we propose a novel training-free method (ActErase) for efficient concept erasure. Specifically, the proposed method operates by identifying activation difference regions via prompt-pair analysis, extracting target activations and dynamically replacing input activations during forward passes. Comprehensive evaluations across three critical erasure tasks (nudity, artistic style, and object removal) demonstrates that our training-free method achieves state-of-the-art (SOTA) erasure performance, while effectively preserving the model's overall generative capability. Our approach also exhibits strong robustness against adversarial attacks, establishing a new plug-and-play paradigm for lightweight yet effective concept manipulation in diffusion models.
AutoLugano: A Deep Learning Framework for Fully Automated Lymphoma Segmentation and Lugano Staging on FDG-PET/CT
Dec 08, 2025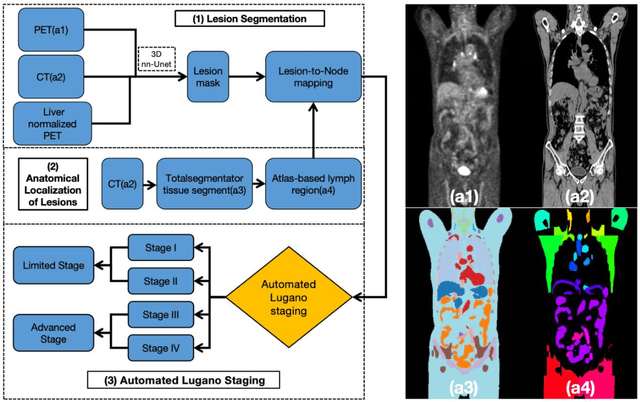
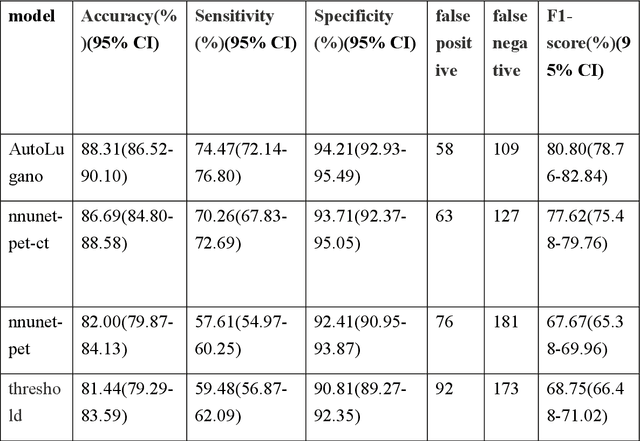
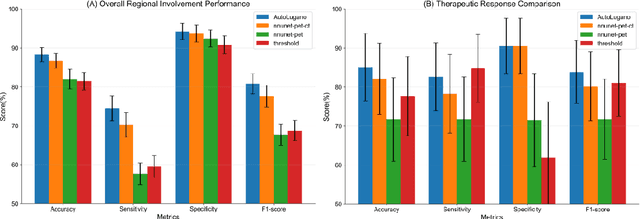
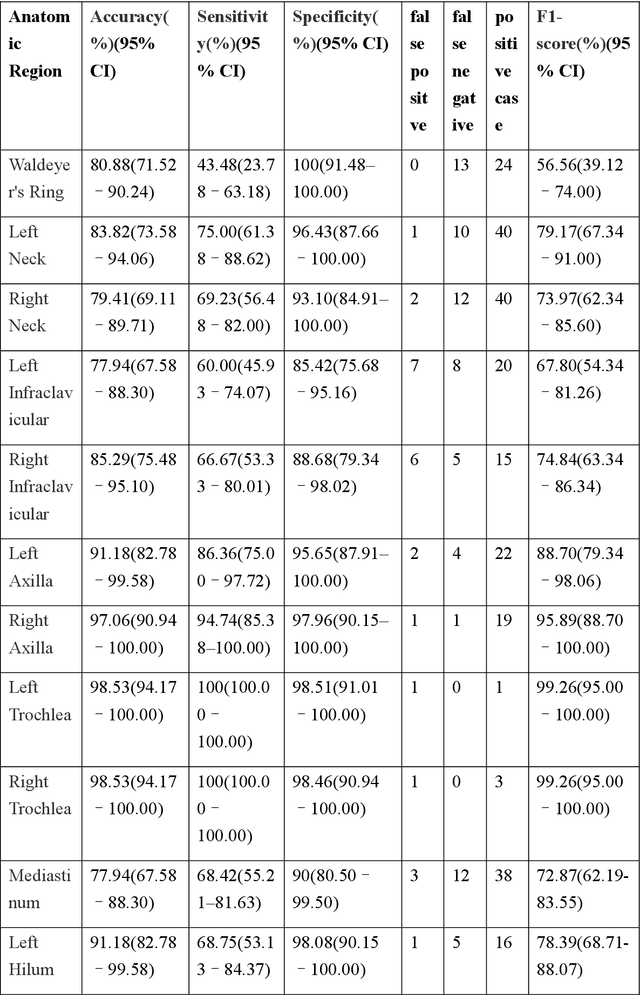
Purpose: To develop a fully automated deep learning system, AutoLugano, for end-to-end lymphoma classification by performing lesion segmentation, anatomical localization, and automated Lugano staging from baseline FDG-PET/CT scans. Methods: The AutoLugano system processes baseline FDG-PET/CT scans through three sequential modules:(1) Anatomy-Informed Lesion Segmentation, a 3D nnU-Net model, trained on multi-channel inputs, performs automated lesion detection (2) Atlas-based Anatomical Localization, which leverages the TotalSegmentator toolkit to map segmented lesions to 21 predefined lymph node regions using deterministic anatomical rules; and (3) Automated Lugano Staging, where the spatial distribution of involved regions is translated into Lugano stages and therapeutic groups (Limited vs. Advanced Stage).The system was trained on the public autoPET dataset (n=1,007) and externally validated on an independent cohort of 67 patients. Performance was assessed using accuracy, sensitivity, specificity, F1-scorefor regional involvement detection and staging agreement. Results: On the external validation set, the proposed model demonstrated robust performance, achieving an overall accuracy of 88.31%, sensitivity of 74.47%, Specificity of 94.21% and an F1-score of 80.80% for regional involvement detection,outperforming baseline models. Most notably, for the critical clinical task of therapeutic stratification (Limited vs. Advanced Stage), the system achieved a high accuracy of 85.07%, with a specificity of 90.48% and a sensitivity of 82.61%.Conclusion: AutoLugano represents the first fully automated, end-to-end pipeline that translates a single baseline FDG-PET/CT scan into a complete Lugano stage. This study demonstrates its strong potential to assist in initial staging, treatment stratification, and supporting clinical decision-making.
Closing the Safety Gap: Surgical Concept Erasure in Visual Autoregressive Models
Sep 26, 2025The rapid progress of visual autoregressive (VAR) models has brought new opportunities for text-to-image generation, but also heightened safety concerns. Existing concept erasure techniques, primarily designed for diffusion models, fail to generalize to VARs due to their next-scale token prediction paradigm. In this paper, we first propose a novel VAR Erasure framework VARE that enables stable concept erasure in VAR models by leveraging auxiliary visual tokens to reduce fine-tuning intensity. Building upon this, we introduce S-VARE, a novel and effective concept erasure method designed for VAR, which incorporates a filtered cross entropy loss to precisely identify and minimally adjust unsafe visual tokens, along with a preservation loss to maintain semantic fidelity, addressing the issues such as language drift and reduced diversity introduce by na\"ive fine-tuning. Extensive experiments demonstrate that our approach achieves surgical concept erasure while preserving generation quality, thereby closing the safety gap in autoregressive text-to-image generation by earlier methods.