 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlaze: Simplified High Performance Cluster Computing
Paper and Code

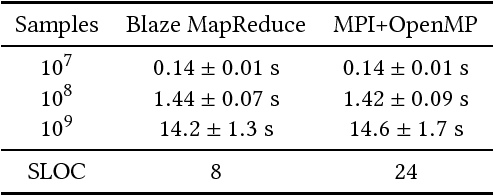
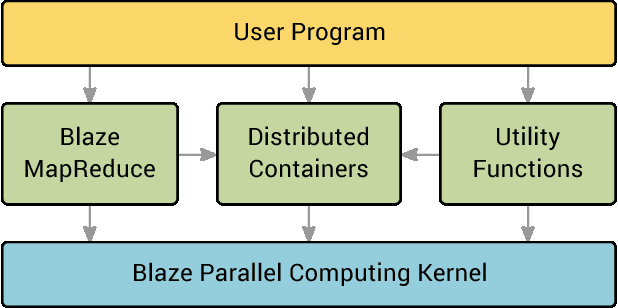

MapReduce and its variants have significantly simplified and accelerated the process of developing parallel programs. However, most MapReduce implementations focus on data-intensive tasks while many real-world tasks are compute intensive and their data can fit distributedly into the memory. For these tasks, the speed of MapReduce programs can be much slower than those hand-optimized ones. We present Blaze, a C++ library that makes it easy to develop high performance parallel programs for such compute intensive tasks. At the core of Blaze is a highly-optimized in-memory MapReduce function, which has three main improvements over conventional MapReduce implementations: eager reduction, fast serialization, and special treatment for a small fixed key range. We also offer additional conveniences that make developing parallel programs similar to developing serial programs. These improvements make Blaze an easy-to-use cluster computing library that approaches the speed of hand-optimized parallel code. We apply Blaze to some common data mining tasks, including word frequency count, PageRank, k-means, expectation maximization (Gaussian mixture model), and k-nearest neighbors. Blaze outperforms Apache Spark by more than 10 times on average for these tasks, and the speed of Blaze scales almost linearly with the number of nodes. In addition, Blaze uses only the MapReduce function and 3 utility functions in its implementation while Spark uses almost 30 different parallel primitives in its official implementation.