 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Visual Relocalization with Nearest View Synthesis from Feature Gaussian Splatting
Mar 31, 2026Visual relocalization is a fundamental task in the field of 3D computer vision, estimating a camera's pose when it revisits a previously known scene. While point-based hierarchical relocalization methods have shown strong scalability and efficiency, they are often limited by sparse image observations and weak feature matching. In this work, we propose SplatHLoc, a novel hierarchical visual relocalization framework that uses Feature Gaussian Splatting as the scene representation. To address the sparsity of database images, we propose an adaptive viewpoint retrieval method that synthesizes virtual candidates with viewpoints more closely aligned with the query, thereby improving the accuracy of initial pose estimation. For feature matching, we observe that Gaussian-rendered features and those extracted directly from images exhibit different strengths across the two-stage matching process: the former performs better in the coarse stage, while the latter proves more effective in the fine stage. Therefore, we introduce a hybrid feature matching strategy, enabling more accurate and efficient pose estimation. Extensive experiments on both indoor and outdoor datasets show that SplatHLoc enhances the robustness of visual relocalization, setting a new state-of-the-art.
Learnable Query Aggregation with KV Routing for Cross-view Geo-localisation
Dec 30, 2025Cross-view geo-localisation (CVGL) aims to estimate the geographic location of a query image by matching it with images from a large-scale database. However, the significant view-point discrepancies present considerable challenges for effective feature aggregation and alignment. To address these challenges, we propose a novel CVGL system that incorporates three key improvements. Firstly, we leverage the DINOv2 backbone with a convolution adapter fine-tuning to enhance model adaptability to cross-view variations. Secondly, we propose a multi-scale channel reallocation module to strengthen the diversity and stability of spatial representations. Finally, we propose an improved aggregation module that integrates a Mixture-of-Experts (MoE) routing into the feature aggregation process. Specifically, the module dynamically selects expert subspaces for the keys and values in a cross-attention framework, enabling adaptive processing of heterogeneous input domains. Extensive experiments on the University-1652 and SUES-200 datasets demonstrate that our method achieves competitive performance with fewer trained parameters.
TrackingMiM: Efficient Mamba-in-Mamba Serialization for Real-time UAV Object Tracking
Jul 02, 2025The Vision Transformer (ViT) model has long struggled with the challenge of quadratic complexity, a limitation that becomes especially critical in unmanned aerial vehicle (UAV) tracking systems, where data must be processed in real time. In this study, we explore the recently proposed State-Space Model, Mamba, leveraging its computational efficiency and capability for long-sequence modeling to effectively process dense image sequences in tracking tasks. First, we highlight the issue of temporal inconsistency in existing Mamba-based methods, specifically the failure to account for temporal continuity in the Mamba scanning mechanism. Secondly, building upon this insight,we propose TrackingMiM, a Mamba-in-Mamba architecture, a minimal-computation burden model for handling image sequence of tracking problem. In our framework, the mamba scan is performed in a nested way while independently process temporal and spatial coherent patch tokens. While the template frame is encoded as query token and utilized for tracking in every scan. Extensive experiments conducted on five UAV tracking benchmarks confirm that the proposed TrackingMiM achieves state-of-the-art precision while offering noticeable higher speed in UAV tracking.
MT-PCR: A Hybrid Mamba-Transformer with Spatial Serialization for Hierarchical Point Cloud Registration
Jun 16, 2025Point cloud registration (PCR) is a fundamental task in 3D computer vision and robotics. Most existing learning-based PCR methods rely on Transformers, which suffer from quadratic computational complexity. This limitation restricts the resolution of point clouds that can be processed, inevitably leading to information loss. In contrast, Mamba-a recently proposed model based on state space models (SSMs)-achieves linear computational complexity while maintaining strong long-range contextual modeling capabilities. However, directly applying Mamba to PCR tasks yields suboptimal performance due to the unordered and irregular nature of point cloud data. To address this challenge, we propose MT-PCR, the first point cloud registration framework that integrates both Mamba and Transformer modules. Specifically, we serialize point cloud features using Z-order space-filling curves to enforce spatial locality, enabling Mamba to better model the geometric structure of the input. Additionally, we remove the order indicator module commonly used in Mamba-based sequence modeling, leads to improved performance in our setting. The serialized features are then processed by an optimized Mamba encoder, followed by a Transformer refinement stage. Extensive experiments on multiple benchmarks demonstrate that MT-PCR outperforms Transformer-based and concurrent state-of-the-art methods in both accuracy and efficiency, significantly reducing while GPU memory usage and FLOPs.
SuperPlace: The Renaissance of Classical Feature Aggregation for Visual Place Recognition in the Era of Foundation Models
Jun 16, 2025Recent visual place recognition (VPR) approaches have leveraged foundation models (FM) and introduced novel aggregation techniques. However, these methods have failed to fully exploit key concepts of FM, such as the effective utilization of extensive training sets, and they have overlooked the potential of classical aggregation methods, such as GeM and NetVLAD. Building on these insights, we revive classical feature aggregation methods and develop more fundamental VPR models, collectively termed SuperPlace. First, we introduce a supervised label alignment method that enables training across various VPR datasets within a unified framework. Second, we propose G$^2$M, a compact feature aggregation method utilizing two GeMs, where one GeM learns the principal components of feature maps along the channel dimension and calibrates the output of the other. Third, we propose the secondary fine-tuning (FT$^2$) strategy for NetVLAD-Linear (NVL). NetVLAD first learns feature vectors in a high-dimensional space and then compresses them into a lower-dimensional space via a single linear layer. Extensive experiments highlight our contributions and demonstrate the superiority of SuperPlace. Specifically, G$^2$M achieves promising results with only one-tenth of the feature dimensions compared to recent methods. Moreover, NVL-FT$^2$ ranks first on the MSLS leaderboard.
EmbodiedPlace: Learning Mixture-of-Features with Embodied Constraints for Visual Place Recognition
Jun 16, 2025Visual Place Recognition (VPR) is a scene-oriented image retrieval problem in computer vision in which re-ranking based on local features is commonly employed to improve performance. In robotics, VPR is also referred to as Loop Closure Detection, which emphasizes spatial-temporal verification within a sequence. However, designing local features specifically for VPR is impractical, and relying on motion sequences imposes limitations. Inspired by these observations, we propose a novel, simple re-ranking method that refines global features through a Mixture-of-Features (MoF) approach under embodied constraints. First, we analyze the practical feasibility of embodied constraints in VPR and categorize them according to existing datasets, which include GPS tags, sequential timestamps, local feature matching, and self-similarity matrices. We then propose a learning-based MoF weight-computation approach, utilizing a multi-metric loss function. Experiments demonstrate that our method improves the state-of-the-art (SOTA) performance on public datasets with minimal additional computational overhead. For instance, with only 25 KB of additional parameters and a processing time of 10 microseconds per frame, our method achieves a 0.9\% improvement over a DINOv2-based baseline performance on the Pitts-30k test set.
TextInPlace: Indoor Visual Place Recognition in Repetitive Structures with Scene Text Spotting and Verification
Mar 09, 2025Visual Place Recognition (VPR) is a crucial capability for long-term autonomous robots, enabling them to identify previously visited locations using visual information. However, existing methods remain limited in indoor settings due to the highly repetitive structures inherent in such environments. We observe that scene text typically appears in indoor spaces, serving to distinguish visually similar but different places. This inspires us to propose TextInPlace, a simple yet effective VPR framework that integrates Scene Text Spotting (STS) to mitigate visual perceptual ambiguity in repetitive indoor environments. Specifically, TextInPlace adopts a dual-branch architecture within a local parameter sharing network. The VPR branch employs attention-based aggregation to extract global descriptors for coarse-grained retrieval, while the STS branch utilizes a bridging text spotter to detect and recognize scene text. Finally, the discriminative text is filtered to compute text similarity and re-rank the top-K retrieved images. To bridge the gap between current text-based repetitive indoor scene datasets and the typical scenarios encountered in robot navigation, we establish an indoor VPR benchmark dataset, called Maze-with-Text. Extensive experiments on both custom and public datasets demonstrate that TextInPlace achieves superior performance over existing methods that rely solely on appearance information. The dataset, code, and trained models are publicly available at https://github.com/HqiTao/TextInPlace.
NocPlace: Nocturnal Visual Place Recognition Using Generative and Inherited Knowledge Transfer
Feb 27, 2024


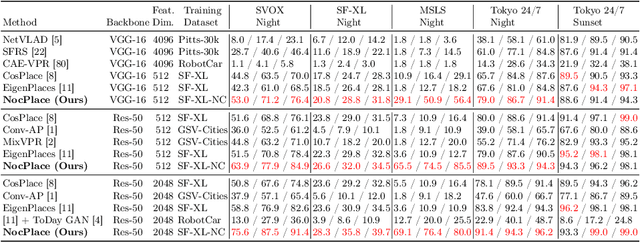
Visual Place Recognition (VPR) is crucial in computer vision, aiming to retrieve database images similar to a query image from an extensive collection of known images. However, like many vision-related tasks, learning-based VPR often experiences a decline in performance during nighttime due to the scarcity of nighttime images. Specifically, VPR needs to address the cross-domain problem of night-to-day rather than just the issue of a single nighttime domain. In response to these issues, we present NocPlace, which leverages a generated large-scale, multi-view, nighttime VPR dataset to embed resilience against dazzling lights and extreme darkness in the learned global descriptor. Firstly, we establish a day-night urban scene dataset called NightCities, capturing diverse nighttime scenarios and lighting variations across 60 cities globally. Following this, an unpaired image-to-image translation network is trained on this dataset. Using this trained translation network, we process an existing VPR dataset, thereby obtaining its nighttime version. The NocPlace is then fine-tuned using night-style images, the original labels, and descriptors inherited from the Daytime VPR model. Comprehensive experiments on various nighttime VPR test sets reveal that NocPlace considerably surpasses previous state-of-the-art methods.
Deep Homography Estimation for Visual Place Recognition
Feb 25, 2024Visual place recognition (VPR) is a fundamental task for many applications such as robot localization and augmented reality. Recently, the hierarchical VPR methods have received considerable attention due to the trade-off between accuracy and efficiency. They usually first use global features to retrieve the candidate images, then verify the spatial consistency of matched local features for re-ranking. However, the latter typically relies on the RANSAC algorithm for fitting homography, which is time-consuming and non-differentiable. This makes existing methods compromise to train the network only in global feature extraction. Here, we propose a transformer-based deep homography estimation (DHE) network that takes the dense feature map extracted by a backbone network as input and fits homography for fast and learnable geometric verification. Moreover, we design a re-projection error of inliers loss to train the DHE network without additional homography labels, which can also be jointly trained with the backbone network to help it extract the features that are more suitable for local matching. Extensive experiments on benchmark datasets show that our method can outperform several state-of-the-art methods. And it is more than one order of magnitude faster than the mainstream hierarchical VPR methods using RANSAC. The code is released at https://github.com/Lu-Feng/DHE-VPR.
NPR: Nocturnal Place Recognition in Streets
Apr 17, 2023



Visual Place Recognition (VPR) is the task of retrieving database images similar to a query photo by comparing it to a large database of known images. In real-world applications, extreme illumination changes caused by query images taken at night pose a significant obstacle that VPR needs to overcome. However, a training set with day-night correspondence for city-scale, street-level VPR does not exist. To address this challenge, we propose a novel pipeline that divides VPR and conquers Nocturnal Place Recognition (NPR). Specifically, we first established a street-level day-night dataset, NightStreet, and used it to train an unpaired image-to-image translation model. Then we used this model to process existing large-scale VPR datasets to generate the VPR-Night datasets and demonstrated how to combine them with two popular VPR pipelines. Finally, we proposed a divide-and-conquer VPR framework and provided explanations at the theoretical, experimental, and application levels. Under our framework, previous methods can significantly improve performance on two public datasets, including the top-ranked method.