 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Visual Relocalization with Nearest View Synthesis from Feature Gaussian Splatting
Mar 31, 2026Visual relocalization is a fundamental task in the field of 3D computer vision, estimating a camera's pose when it revisits a previously known scene. While point-based hierarchical relocalization methods have shown strong scalability and efficiency, they are often limited by sparse image observations and weak feature matching. In this work, we propose SplatHLoc, a novel hierarchical visual relocalization framework that uses Feature Gaussian Splatting as the scene representation. To address the sparsity of database images, we propose an adaptive viewpoint retrieval method that synthesizes virtual candidates with viewpoints more closely aligned with the query, thereby improving the accuracy of initial pose estimation. For feature matching, we observe that Gaussian-rendered features and those extracted directly from images exhibit different strengths across the two-stage matching process: the former performs better in the coarse stage, while the latter proves more effective in the fine stage. Therefore, we introduce a hybrid feature matching strategy, enabling more accurate and efficient pose estimation. Extensive experiments on both indoor and outdoor datasets show that SplatHLoc enhances the robustness of visual relocalization, setting a new state-of-the-art.
TextInPlace: Indoor Visual Place Recognition in Repetitive Structures with Scene Text Spotting and Verification
Mar 09, 2025Visual Place Recognition (VPR) is a crucial capability for long-term autonomous robots, enabling them to identify previously visited locations using visual information. However, existing methods remain limited in indoor settings due to the highly repetitive structures inherent in such environments. We observe that scene text typically appears in indoor spaces, serving to distinguish visually similar but different places. This inspires us to propose TextInPlace, a simple yet effective VPR framework that integrates Scene Text Spotting (STS) to mitigate visual perceptual ambiguity in repetitive indoor environments. Specifically, TextInPlace adopts a dual-branch architecture within a local parameter sharing network. The VPR branch employs attention-based aggregation to extract global descriptors for coarse-grained retrieval, while the STS branch utilizes a bridging text spotter to detect and recognize scene text. Finally, the discriminative text is filtered to compute text similarity and re-rank the top-K retrieved images. To bridge the gap between current text-based repetitive indoor scene datasets and the typical scenarios encountered in robot navigation, we establish an indoor VPR benchmark dataset, called Maze-with-Text. Extensive experiments on both custom and public datasets demonstrate that TextInPlace achieves superior performance over existing methods that rely solely on appearance information. The dataset, code, and trained models are publicly available at https://github.com/HqiTao/TextInPlace.
NocPlace: Nocturnal Visual Place Recognition Using Generative and Inherited Knowledge Transfer
Feb 27, 2024


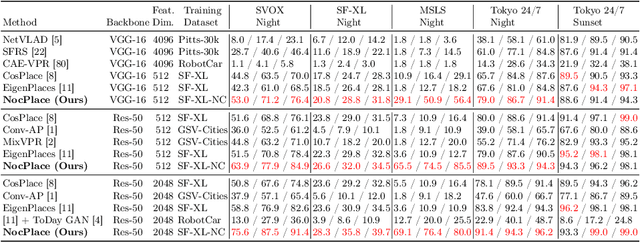
Visual Place Recognition (VPR) is crucial in computer vision, aiming to retrieve database images similar to a query image from an extensive collection of known images. However, like many vision-related tasks, learning-based VPR often experiences a decline in performance during nighttime due to the scarcity of nighttime images. Specifically, VPR needs to address the cross-domain problem of night-to-day rather than just the issue of a single nighttime domain. In response to these issues, we present NocPlace, which leverages a generated large-scale, multi-view, nighttime VPR dataset to embed resilience against dazzling lights and extreme darkness in the learned global descriptor. Firstly, we establish a day-night urban scene dataset called NightCities, capturing diverse nighttime scenarios and lighting variations across 60 cities globally. Following this, an unpaired image-to-image translation network is trained on this dataset. Using this trained translation network, we process an existing VPR dataset, thereby obtaining its nighttime version. The NocPlace is then fine-tuned using night-style images, the original labels, and descriptors inherited from the Daytime VPR model. Comprehensive experiments on various nighttime VPR test sets reveal that NocPlace considerably surpasses previous state-of-the-art methods.
A Convolutional-Transformer Network for Crack Segmentation with Boundary Awareness
Feb 23, 2023Cracks play a crucial role in assessing the safety and durability of manufactured buildings. However, the long and sharp topological features and complex background of cracks make the task of crack segmentation extremely challenging. In this paper, we propose a novel convolutional-transformer network based on encoder-decoder architecture to solve this challenge. Particularly, we designed a Dilated Residual Block (DRB) and a Boundary Awareness Module (BAM). The DRB pays attention to the local detail of cracks and adjusts the feature dimension for other blocks as needed. And the BAM learns the boundary features from the dilated crack label. Furthermore, the DRB is combined with a lightweight transformer that captures global information to serve as an effective encoder. Experimental results show that the proposed network performs better than state-of-the-art algorithms on two typical datasets. Datasets, code, and trained models are available for research at https://github.com/HqiTao/CT-crackseg.