 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSCOUT: Teaching Pre-trained Language Models to Enhance Reasoning via Flow Chain-of-Thought
May 30, 2025Chain of Thought (CoT) prompting improves the reasoning performance of large language models (LLMs) by encouraging step by step thinking. However, CoT-based methods depend on intermediate reasoning steps, which limits scalability and generalization. Recent work explores recursive reasoning, where LLMs reuse internal layers across iterations to refine latent representations without explicit CoT supervision. While promising, these approaches often require costly pretraining and lack a principled framework for how reasoning should evolve across iterations. We address this gap by introducing Flow Chain of Thought (Flow CoT), a reasoning paradigm that models recursive inference as a progressive trajectory of latent cognitive states. Flow CoT frames each iteration as a distinct cognitive stage deepening reasoning across iterations without relying on manual supervision. To realize this, we propose SCOUT (Stepwise Cognitive Optimization Using Teachers), a lightweight fine tuning framework that enables Flow CoT style reasoning without the need for pretraining. SCOUT uses progressive distillation to align each iteration with a teacher of appropriate capacity, and a cross attention based retrospective module that integrates outputs from previous iterations while preserving the models original computation flow. Experiments across eight reasoning benchmarks show that SCOUT consistently improves both accuracy and explanation quality, achieving up to 1.8% gains under fine tuning. Qualitative analyses further reveal that SCOUT enables progressively deeper reasoning across iterations refining both belief formation and explanation granularity. These results not only validate the effectiveness of SCOUT, but also demonstrate the practical viability of Flow CoT as a scalable framework for enhancing reasoning in LLMs.
MIGA: Mutual Information-Guided Attack on Denoising Models for Semantic Manipulation
Mar 11, 2025Deep learning-based denoising models have been widely employed in vision tasks, functioning as filters to eliminate noise while retaining crucial semantic information. Additionally, they play a vital role in defending against adversarial perturbations that threaten downstream tasks. However, these models can be intrinsically susceptible to adversarial attacks due to their dependence on specific noise assumptions. Existing attacks on denoising models mainly aim at deteriorating visual clarity while neglecting semantic manipulation, rendering them either easily detectable or limited in effectiveness. In this paper, we propose Mutual Information-Guided Attack (MIGA), the first method designed to directly attack deep denoising models by strategically disrupting their ability to preserve semantic content via adversarial perturbations. By minimizing the mutual information between the original and denoised images, a measure of semantic similarity. MIGA forces the denoiser to produce perceptually clean yet semantically altered outputs. While these images appear visually plausible, they encode systematically distorted semantics, revealing a fundamental vulnerability in denoising models. These distortions persist in denoised outputs and can be quantitatively assessed through downstream task performance. We propose new evaluation metrics and systematically assess MIGA on four denoising models across five datasets, demonstrating its consistent effectiveness in disrupting semantic fidelity. Our findings suggest that denoising models are not always robust and can introduce security risks in real-world applications.
Deep Homography Estimation for Visual Place Recognition
Feb 25, 2024Visual place recognition (VPR) is a fundamental task for many applications such as robot localization and augmented reality. Recently, the hierarchical VPR methods have received considerable attention due to the trade-off between accuracy and efficiency. They usually first use global features to retrieve the candidate images, then verify the spatial consistency of matched local features for re-ranking. However, the latter typically relies on the RANSAC algorithm for fitting homography, which is time-consuming and non-differentiable. This makes existing methods compromise to train the network only in global feature extraction. Here, we propose a transformer-based deep homography estimation (DHE) network that takes the dense feature map extracted by a backbone network as input and fits homography for fast and learnable geometric verification. Moreover, we design a re-projection error of inliers loss to train the DHE network without additional homography labels, which can also be jointly trained with the backbone network to help it extract the features that are more suitable for local matching. Extensive experiments on benchmark datasets show that our method can outperform several state-of-the-art methods. And it is more than one order of magnitude faster than the mainstream hierarchical VPR methods using RANSAC. The code is released at https://github.com/Lu-Feng/DHE-VPR.
Towards Seamless Adaptation of Pre-trained Models for Visual Place Recognition
Feb 22, 2024Recent studies show that vision models pre-trained in generic visual learning tasks with large-scale data can provide useful feature representations for a wide range of visual perception problems. However, few attempts have been made to exploit pre-trained foundation models in visual place recognition (VPR). Due to the inherent difference in training objectives and data between the tasks of model pre-training and VPR, how to bridge the gap and fully unleash the capability of pre-trained models for VPR is still a key issue to address. To this end, we propose a novel method to realize seamless adaptation of pre-trained models for VPR. Specifically, to obtain both global and local features that focus on salient landmarks for discriminating places, we design a hybrid adaptation method to achieve both global and local adaptation efficiently, in which only lightweight adapters are tuned without adjusting the pre-trained model. Besides, to guide effective adaptation, we propose a mutual nearest neighbor local feature loss, which ensures proper dense local features are produced for local matching and avoids time-consuming spatial verification in re-ranking. Experimental results show that our method outperforms the state-of-the-art methods with less training data and training time, and uses about only 3% retrieval runtime of the two-stage VPR methods with RANSAC-based spatial verification. It ranks 1st on the MSLS challenge leaderboard (at the time of submission). The code is released at https://github.com/Lu-Feng/SelaVPR.
AANet: Aggregation and Alignment Network with Semi-hard Positive Sample Mining for Hierarchical Place Recognition
Oct 08, 2023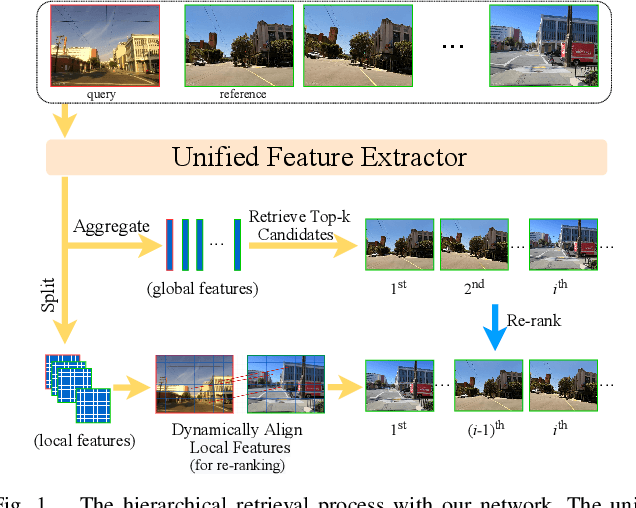
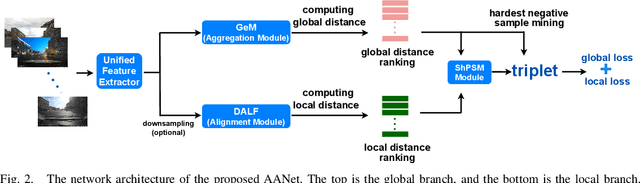
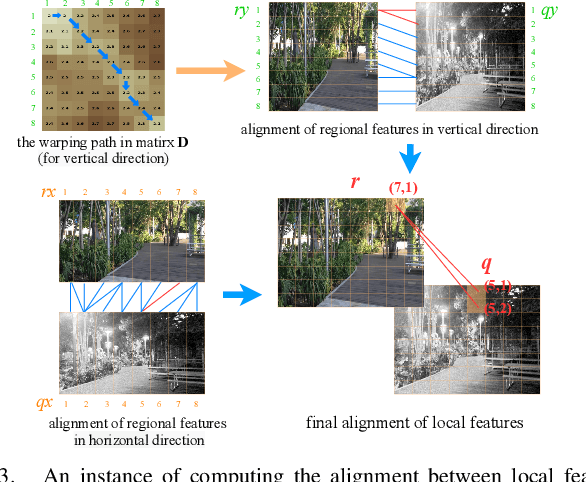
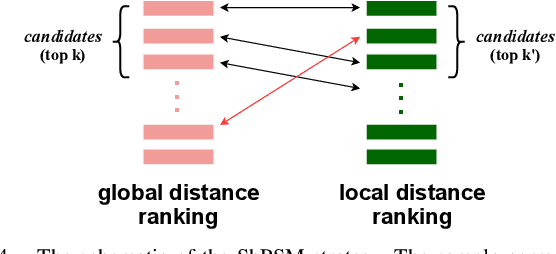
Visual place recognition (VPR) is one of the research hotspots in robotics, which uses visual information to locate robots. Recently, the hierarchical two-stage VPR methods have become popular in this field due to the trade-off between accuracy and efficiency. These methods retrieve the top-k candidate images using the global features in the first stage, then re-rank the candidates by matching the local features in the second stage. However, they usually require additional algorithms (e.g. RANSAC) for geometric consistency verification in re-ranking, which is time-consuming. Here we propose a Dynamically Aligning Local Features (DALF) algorithm to align the local features under spatial constraints. It is significantly more efficient than the methods that need geometric consistency verification. We present a unified network capable of extracting global features for retrieving candidates via an aggregation module and aligning local features for re-ranking via the DALF alignment module. We call this network AANet. Meanwhile, many works use the simplest positive samples in triplet for weakly supervised training, which limits the ability of the network to recognize harder positive pairs. To address this issue, we propose a Semi-hard Positive Sample Mining (ShPSM) strategy to select appropriate hard positive images for training more robust VPR networks. Extensive experiments on four benchmark VPR datasets show that the proposed AANet can outperform several state-of-the-art methods with less time consumption. The code is released at https://github.com/Lu-Feng/AANet.