 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBEAP-Agent: Backtrackable Execution and Adaptive Planning for GUI Agents
Jan 29, 2026GUI agents are designed to automate repetitive tasks and enhance productivity. However, existing GUI agents struggle to recover once they follow an incorrect exploration path, often leading to task failure. In this work, we model GUI task execution as a DFS process and propose BEAP-Agent, a DFS-based framework that supports long-range, multi-level state backtracking with dynamic task tracking and updating. The framework consists of three collaborative components: Planner, Executor, and Tracker. Together, they enable effective task exploration and execution. BEAP-Agent fills the gap in systematic backtracking mechanisms for GUI agents, offering a systematic solution for long-horizon task exploration. We conducted a systematic evaluation on the OSWorld benchmark, where BEAP-Agent achieved an accuracy of 28.2%, validating the effectiveness of the proposed method.
RM-Distiller: Exploiting Generative LLM for Reward Model Distillation
Jan 20, 2026Reward models (RMs) play a pivotal role in aligning large language models (LLMs) with human preferences. Due to the difficulty of obtaining high-quality human preference annotations, distilling preferences from generative LLMs has emerged as a standard practice. However, existing approaches predominantly treat teacher models as simple binary annotators, failing to fully exploit the rich knowledge and capabilities for RM distillation. To address this, we propose RM-Distiller, a framework designed to systematically exploit the multifaceted capabilities of teacher LLMs: (1) Refinement capability, which synthesizes highly correlated response pairs to create fine-grained and contrastive signals. (2) Scoring capability, which guides the RM in capturing precise preference strength via a margin-aware optimization objective. (3) Generation capability, which incorporates the teacher's generative distribution to regularize the RM to preserve its fundamental linguistic knowledge. Extensive experiments demonstrate that RM-Distiller significantly outperforms traditional distillation methods both on RM benchmarks and reinforcement learning-based alignment, proving that exploiting multifaceted teacher capabilities is critical for effective reward modeling. To the best of our knowledge, this is the first systematic research on RM distillation from generative LLMs.
SDE-SQL: Enhancing Text-to-SQL Generation in Large Language Models via Self-Driven Exploration with SQL Probes
Jun 08, 2025Recent advancements in large language models (LLMs) have significantly improved performance on the Text-to-SQL task. However, prior approaches typically rely on static, pre-processed database information provided at inference time, which limits the model's ability to fully understand the database contents. Without dynamic interaction, LLMs are constrained to fixed, human-provided context and cannot autonomously explore the underlying data. To address this limitation, we propose SDE-SQL, a framework that enables large language models to perform self-driven exploration of databases during inference. This is accomplished by generating and executing SQL probes, which allow the model to actively retrieve information from the database and iteratively update its understanding of the data. Unlike prior methods, SDE-SQL operates in a zero-shot setting, without relying on any question-SQL pairs as in-context demonstrations. When evaluated on the BIRD benchmark with Qwen2.5-72B-Instruct, SDE-SQL achieves an 8.02% relative improvement in execution accuracy over the vanilla Qwen2.5-72B-Instruct baseline, establishing a new state-of-the-art among methods based on open-source models without supervised fine-tuning (SFT) or model ensembling. Moreover, with SFT, the performance of SDE-SQL can be further enhanced, yielding an additional 0.52% improvement.
SCOUT: Teaching Pre-trained Language Models to Enhance Reasoning via Flow Chain-of-Thought
May 30, 2025Chain of Thought (CoT) prompting improves the reasoning performance of large language models (LLMs) by encouraging step by step thinking. However, CoT-based methods depend on intermediate reasoning steps, which limits scalability and generalization. Recent work explores recursive reasoning, where LLMs reuse internal layers across iterations to refine latent representations without explicit CoT supervision. While promising, these approaches often require costly pretraining and lack a principled framework for how reasoning should evolve across iterations. We address this gap by introducing Flow Chain of Thought (Flow CoT), a reasoning paradigm that models recursive inference as a progressive trajectory of latent cognitive states. Flow CoT frames each iteration as a distinct cognitive stage deepening reasoning across iterations without relying on manual supervision. To realize this, we propose SCOUT (Stepwise Cognitive Optimization Using Teachers), a lightweight fine tuning framework that enables Flow CoT style reasoning without the need for pretraining. SCOUT uses progressive distillation to align each iteration with a teacher of appropriate capacity, and a cross attention based retrospective module that integrates outputs from previous iterations while preserving the models original computation flow. Experiments across eight reasoning benchmarks show that SCOUT consistently improves both accuracy and explanation quality, achieving up to 1.8% gains under fine tuning. Qualitative analyses further reveal that SCOUT enables progressively deeper reasoning across iterations refining both belief formation and explanation granularity. These results not only validate the effectiveness of SCOUT, but also demonstrate the practical viability of Flow CoT as a scalable framework for enhancing reasoning in LLMs.
LlamaSeg: Image Segmentation via Autoregressive Mask Generation
May 26, 2025We present LlamaSeg, a visual autoregressive framework that unifies multiple image segmentation tasks via natural language instructions. We reformulate image segmentation as a visual generation problem, representing masks as "visual" tokens and employing a LLaMA-style Transformer to predict them directly from image inputs. By adhering to the next-token prediction paradigm, our approach naturally integrates segmentation tasks into autoregressive architectures. To support large-scale training, we introduce a data annotation pipeline and construct the SA-OVRS dataset, which contains 2M segmentation masks annotated with over 5,800 open-vocabulary labels or diverse textual descriptions, covering a wide spectrum of real-world scenarios. This enables our model to localize objects in images based on text prompts and to generate fine-grained masks. To more accurately evaluate the quality of masks produced by visual generative models, we further propose a composite metric that combines Intersection over Union (IoU) with Average Hausdorff Distance (AHD), offering a more precise assessment of contour fidelity. Experimental results demonstrate that our method surpasses existing generative models across multiple datasets and yields more detailed segmentation masks.
ReEx-SQL: Reasoning with Execution-Aware Reinforcement Learning for Text-to-SQL
May 19, 2025In Text-to-SQL, execution feedback is essential for guiding large language models (LLMs) to reason accurately and generate reliable SQL queries. However, existing methods treat execution feedback solely as a post-hoc signal for correction or selection, failing to integrate it into the generation process. This limitation hinders their ability to address reasoning errors as they occur, ultimately reducing query accuracy and robustness. To address this issue, we propose ReEx-SQL (Reasoning with Execution-Aware Reinforcement Learning), a framework for Text-to-SQL that enables models to interact with the database during decoding and dynamically adjust their reasoning based on execution feedback. ReEx-SQL introduces an execution-aware reasoning paradigm that interleaves intermediate SQL execution into reasoning paths, facilitating context-sensitive revisions. It achieves this through structured prompts with markup tags and a stepwise rollout strategy that integrates execution feedback into each stage of generation. To supervise policy learning, we develop a composite reward function that includes an exploration reward, explicitly encouraging effective database interaction. Additionally, ReEx-SQL adopts a tree-based decoding strategy to support exploratory reasoning, enabling dynamic expansion of alternative reasoning paths. Notably, ReEx-SQL achieves 88.8% on Spider and 64.9% on BIRD at the 7B scale, surpassing the standard reasoning baseline by 2.7% and 2.6%, respectively. It also shows robustness, achieving 85.2% on Spider-Realistic with leading performance. In addition, its tree-structured decoding improves efficiency and performance over linear decoding, reducing inference time by 51.9% on the BIRD development set.
Federated Large Language Models: Feasibility, Robustness, Security and Future Directions
May 13, 2025The integration of Large Language Models (LLMs) and Federated Learning (FL) presents a promising solution for joint training on distributed data while preserving privacy and addressing data silo issues. However, this emerging field, known as Federated Large Language Models (FLLM), faces significant challenges, including communication and computation overheads, heterogeneity, privacy and security concerns. Current research has primarily focused on the feasibility of FLLM, but future trends are expected to emphasize enhancing system robustness and security. This paper provides a comprehensive review of the latest advancements in FLLM, examining challenges from four critical perspectives: feasibility, robustness, security, and future directions. We present an exhaustive survey of existing studies on FLLM feasibility, introduce methods to enhance robustness in the face of resource, data, and task heterogeneity, and analyze novel risks associated with this integration, including privacy threats and security challenges. We also review the latest developments in defense mechanisms and explore promising future research directions, such as few-shot learning, machine unlearning, and IP protection. This survey highlights the pressing need for further research to enhance system robustness and security while addressing the unique challenges posed by the integration of FL and LLM.
RAISE: Reinforenced Adaptive Instruction Selection For Large Language Models
Apr 09, 2025In the instruction fine-tuning of large language models (LLMs), it has become a consensus that a few high-quality instructions are superior to a large number of low-quality instructions. At present, many instruction selection methods have been proposed, but most of these methods select instruction based on heuristic quality metrics, and only consider data selection before training. These designs lead to insufficient optimization of instruction fine-tuning, and fixed heuristic indicators are often difficult to optimize for specific tasks. So we designed a dynamic, task-objective-driven instruction selection framework RAISE(Reinforenced Adaptive Instruction SElection), which incorporates the entire instruction fine-tuning process into optimization, selecting instruction at each step based on the expected impact of instruction on model performance improvement. Our approach is well interpretable and has strong task-specific optimization capabilities. By modeling dynamic instruction selection as a sequential decision-making process, we use RL to train our selection strategy. Extensive experiments and result analysis prove the superiority of our method compared with other instruction selection methods. Notably, RAISE achieves superior performance by updating only 1\% of the training steps compared to full-data training, demonstrating its efficiency and effectiveness.
VisNumBench: Evaluating Number Sense of Multimodal Large Language Models
Mar 19, 2025Can Multimodal Large Language Models (MLLMs) develop an intuitive number sense similar to humans? Targeting this problem, we introduce Visual Number Benchmark (VisNumBench) to evaluate the number sense abilities of MLLMs across a wide range of visual numerical tasks. VisNumBench consists of about 1,900 multiple-choice question-answer pairs derived from both synthetic and real-world visual data, covering seven visual numerical attributes and four types of visual numerical estimation tasks. Our experiments on VisNumBench led to the following key findings: (i) The 17 MLLMs we tested, including open-source models such as Qwen2.5-VL and InternVL2.5, as well as proprietary models like GPT-4o and Gemini 2.0 Flash, perform significantly below human levels in number sense-related tasks. (ii) Multimodal mathematical models and multimodal chain-of-thought (CoT) models did not exhibit significant improvements in number sense abilities. (iii) Stronger MLLMs with larger parameter sizes and broader general abilities demonstrate modest gains in number sense abilities. We believe VisNumBench will serve as a valuable resource for the research community, encouraging further advancements in enhancing MLLMs' number sense abilities. All benchmark resources, including code and datasets, will be publicly available at https://wwwtttjjj.github.io/VisNumBench/.
Active Learning from Scene Embeddings for End-to-End Autonomous Driving
Mar 14, 2025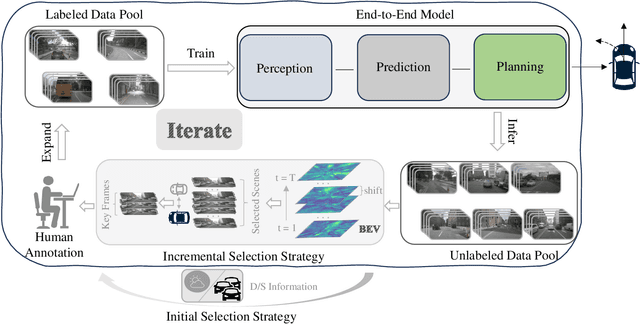
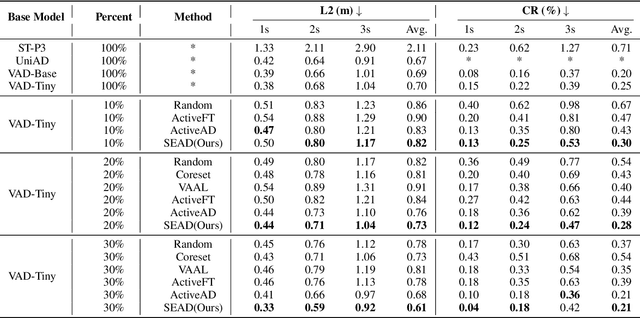
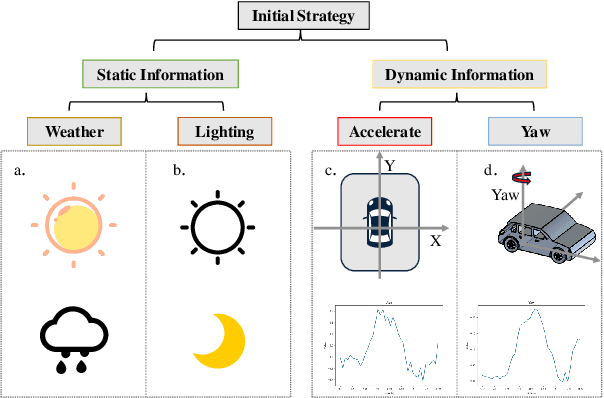
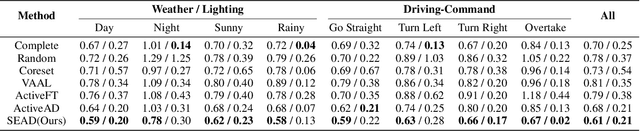
In the field of autonomous driving, end-to-end deep learning models show great potential by learning driving decisions directly from sensor data. However, training these models requires large amounts of labeled data, which is time-consuming and expensive. Considering that the real-world driving data exhibits a long-tailed distribution where simple scenarios constitute a majority part of the data, we are thus inspired to identify the most challenging scenarios within it. Subsequently, we can efficiently improve the performance of the model by training with the selected data of the highest value. Prior research has focused on the selection of valuable data by empirically designed strategies. However, manually designed methods suffer from being less generalizable to new data distributions. Observing that the BEV (Bird's Eye View) features in end-to-end models contain all the information required to represent the scenario, we propose an active learning framework that relies on these vectorized scene-level features, called SEAD. The framework selects initial data based on driving-environmental information and incremental data based on BEV features. Experiments show that we only need 30\% of the nuScenes training data to achieve performance close to what can be achieved with the full dataset. The source code will be released.